在以前的项目中用到了百度语音识别服务,在这里做一个笔记。这里还是要和大家强调一下,最好的学习资料就是官网网站。我这里只是一个笔记,一方面整理了思路,另一方面方便以后我再次用到的时候可以快速回忆起来。
百度语音识别服务是什么?
百度语音识别服务能将语音文件(指定格式,不是所有格式都可以)识别成文本。语音识别我们都接触过,手机输入法里就有语音识别服务。
什么是百度语音识别的 REST API?
按照官网的说法
简单说来,就是无须在开发者的项目中写入代码,或引入 jar 包 。 REST API 就是将音频文件转换成某种特定格式,通过 http 请求发送给百度语音识别的服务器,由百度语音识别的服务器进行语音识别,最后返回识别出的文本。
在我看来,她好在可以很方便的调用,我们自己不用去维护语音识别部分的代码,接入也十分简单,关键是她是免费的!
使用的方式简单说来是
1、根据百度语音识别官方网站提供的
App ID 和 API Key 获取 accessToken。
2、根据上一步的 accessToken 连同其它请求参数一起向百度语音识别网关发出请求,获得识别的文本。
是不是觉得和微信公众平台的开发有点像?的确是这样的。微信公众平台的开发的确也是先获取 token,再通过 token 去请求其它数据。
集成步骤
本集成步骤参考了《Baidu_Voice_REST_API_Manual》。建议各位朋友先下载该资料学习。
第 1 步:注册成为百度开发者,创建应用,得到 API Key 和 Secret Key。
这一步非常简单,在官网上也有操作提示,这里就不多介绍了。
第 2 步:开通语音识别服务
开通语音识别服务的步骤也非常简单,大家可以自行操作或者参考官方文档。这里要注意:“ 语音识别” 服务初次开通成功后即可获得 50000 次/ 日 的在线调用次数配额。
如果我们每天调用的次数大于 50000 次,可以向百度申请提高次数,据说也是免费的,大赞。
以下的步骤就很关键了,因为我们要开始写代码了。
第 3 步:获取 Access Token
简而言之,就是向百度 OAuth2.0 授权服务的网关发出请求,将返回的数据(一般是字符串)进行解析,解析出我们想要的 Access Token。下面的图片截取自官网文档,写得非常详细了。
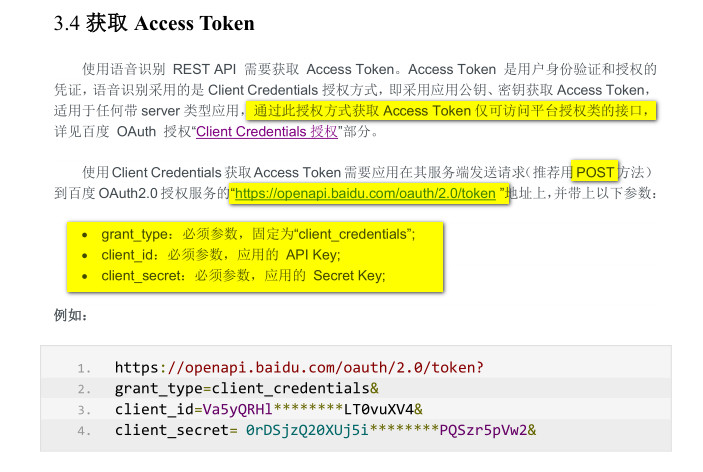
说明:其实就是使用 API Key 和 Secret Key 和一个固定值的参数向百度 OAuth2.0 授权服务的网关发出 POST 请求,如果请求成功,则解析返回的字符串,从中解析出 access token 待用。
为了方便说明问题,下面代码没有应用良好格式,仅仅只是测试的方法,不建议直接应用于生产环境。
本例使用 HttpClient 框架发送 post 请求,HttpClient 的 Gradle 依赖为:
compile "org.apache.httpcomponents:httpclient:4.5.2"示例代码:
/*** 获取 token,推荐用 POST 方法*/
@Test
public void test01(){try {CloseableHttpClient httpClient = HttpClients.createDefault();HttpPost httpPost = new HttpPost("https://openapi.baidu.com/oauth/2.0/token");List<NameValuePair> nvps = new ArrayList<>();nvps.add(new BasicNameValuePair("grant_type","client_credentials"));nvps.add(new BasicNameValuePair("client_id",apiKey));nvps.add(new BasicNameValuePair("client_secret",secretKey));httpPost.setEntity(new UrlEncodedFormEntity(nvps));ResponseHandler<String> responseHandler = new ResponseHandler(){@Overridepublic String handleResponse(HttpResponse response) throws ClientProtocolException, IOException {int status = response.getStatusLine().getStatusCode();if (status >= 200 && status < 300) {HttpEntity entity = response.getEntity();try {return entity != null ? EntityUtils.toString(entity) : null;} catch (ParseException ex) {throw new ClientProtocolException(ex);}} else {throw new ClientProtocolException("Unexpected response status: " + status);}}};String responseBody = httpClient.execute(httpPost,responseHandler);System.out.println(responseBody);} catch (UnsupportedEncodingException e) {e.printStackTrace();} catch (ClientProtocolException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}
}返回数据:
{"access_token":"24.463f2a9f7ce6721fe4d15568f812c086.2592000.1469627568.282335-7038695","session_key":"9mzdDxLM148MA1QmcNNrxGfLYBU9VokNbUY\/8WsJ1r4rUSev1bjP9GTKP6L6SVDnjx4BZxE5ZpJoqztA2K7O0MM9l0Z4","scope":"public audio_voice_assistant_get wise_adapt lebo_resource_base lightservice_public hetu_basic lightcms_map_poi kaidian_kaidian","refresh_token":"25.f77abdb8f638404747dd969615c7b557.315360000.1782395568.282335-7038695","session_secret":"3efb3872a362beacab28879eed85497b","expires_in":2592000}
格式化以后:

我们须要从中解析出 access_token , json 字符串解析的框架有很多 fastjson、Jackson、json-lib、gson,这里就不多做介绍了。
另外还是要说明一下,因为 access_token 的有效时间是 2592000 (秒),即 30 × 24 × 60 × 60 (秒), 30 天,所以没有必要每一次请求都去获取 access_token ,建议把 access_token 放在应用的缓存里,如果失效了,再去获取,可以提高应用的效率,这一点和微信公众平台开发是一样的。
第 4 步:根据 Access Token 调用语音识别接口(隐式发送)
说明:我们这里采用的是隐式发送,即不发送真实的音频文件,而是发送音频文件转换而成的字节数组。这里一定要看官网说明,严格调用,才会识别出理想的结果。难点是音频格式的转换。
我是看了官网说明文档和示例代码,经过反复调试才得以调用成功的。鉴于这里篇幅的限制,请大家先看官网说明文档,我这里就不复制了。
这里为了方便说明,先上示例代码,同样地该代码只是为了便于说明问题,不建议在生产环境中直接使用:
/*** 识别英文*/
@Test
public void test02(){recognize("voice_en.wav","en");
}上面的测试方法调用了语音识别的方法,该方法传递两个参数,一个是文件的全路径,另一个是中文或者英文的参数。
下面
/*** 请求语音识别的时候使用*/private static final String speech_recognition_url = "http://vop.baidu.com/server_api";private void recognize(String wavName,String language){File wavFile = new File(wavName);HttpPost httpPost = null;CloseableHttpResponse response = null;CloseableHttpClient httpClient = HttpClients.createDefault();httpPost = new HttpPost(speech_recognition_url);SpeechRecognitionRequestEntity requestEntity = new SpeechRecognitionRequestEntity();// 语音压缩的格式:请按照官网文档填写 pcm(不压缩)、wav、opus、speex、amr、x-flac 之一,不区分大小写requestEntity.setFormat("wav");// 声道数,仅支持单声道,请填写 1requestEntity.setChannel("1");// 采样率,支持 8000 或者 16000 (这个类型是 int ,不能设置为 String 类型,关于采样率如何转换,请见下文)requestEntity.setRate(16000);// todo 这里应判断 AccessToken 是否过期,处理异常,如果过期了,应该重新获取 accessTokenrequestEntity.setToken("24.463f2a9f7ce6721fe4d15568f812c086.2592000.1469627568.282335-7038695");// Cuid 貌似可以随意填写requestEntity.setCuid("goodluck");requestEntity.setLen(wavFile.length());// 官网说: speech 要传递真实的语音数据,需要进行 base64 编码// 重点关注:请见后面封装的方法,就是把一个文件转换成为指定格式的字节数组requestEntity.setSpeech(handlerWavFile(wavFile));// 语种选择,中文=zh、粤语=ct、英文=en,不区分大小写,默认中文requestEntity.setLan(language);// 关键点 1 :将请求参数转换为 json 格式String requestEntityJson = JSON.toJSONString(requestEntity);// 关键点 2 :封装 StringEntity ,为解决中文乱码问题,应该设置编码StringEntity entity = new StringEntity(requestEntityJson.toString(), "UTF-8");entity.setContentEncoding("UTF-8");// 关键点 3 :设置 StringEntity 的 ContentTypeentity.setContentType("application/json");httpPost.setEntity(entity);ResponseHandler<String> responseHandler = new ResponseHandler<String>() {@Overridepublic String handleResponse(HttpResponse response) throws ClientProtocolException, IOException {String resData = null;int statusCode = response.getStatusLine().getStatusCode();if (statusCode >= 200 && statusCode < 300) {HttpEntity httpEntity = response.getEntity();resData = EntityUtils.toString(httpEntity,"utf-8");EntityUtils.consume(httpEntity);}return resData;}};try {String responseStr = httpClient.execute(httpPost,responseHandler);System.out.println(responseStr);} catch (IOException e) {e.printStackTrace();}
}SpeechRecognitionRequestEntity 类(省略了 get 和 set 方法):
public class SpeechRecognitionRequestEntity {// 语音压缩的格式private String format;/*** 注意,采样率的数据类型一定是 int,不能是 String*/// 采样率,支持 8000 或者 16000,在我们的项目中,写 16000private int rate;// 声道数,仅支持单声道,请填写 1private String channel;// 开发者身份验证密钥private String token;// 用户 ID,推荐使用设备 mac 地址 手机 IMEI 等设备唯一性参数// todo 貌似可以随意填写,唯一即可private String cuid;/*** 注意:这里填写的是原始语音的长度,不是使用 base64 编码的语音长度*/// 原始语音长度,单位字节private long len;// 真实的语音数据,需要进行 base64 编码private String speech;// 语种选择,中文=zh、粤语=ct、英文=en,不区分大小写,默认中文private String lan;
}这部分代码摘抄自官网示例代码:
private byte[] loadFile(File file) throws IOException {InputStream is = new FileInputStream(file);long length = file.length();byte[] bytes = new byte[(int) length];int offset = 0;int numRead = 0;while (offset < bytes.length && (numRead = is.read(bytes, offset, bytes.length - offset)) >= 0) {offset += numRead;}if (offset < bytes.length) {is.close();throw new IOException("Could not completely read file " + file.getName());}is.close();
return bytes;
}返回结果:
{"corpus_no":"6300874524819907792","err_msg":"success.","err_no":0,"result":["one day in the cage club got bad news, ","one day in the case club got bad news, ","one day in that case club got bad news, ","one day in the cage club got the bad news, ","one day in the case club got the bad news, "],"sn":"843115237281467036671"}格式化以后:

以上介绍了代码如何编写。但是在开发中,我遇到了一个难题,要将音频文件转换成百度语音识别能够识别的格式。请看官方文档说明。

于是,为了测试,我使用格式工厂软件进行格式转化。以下是格式转换的参数。
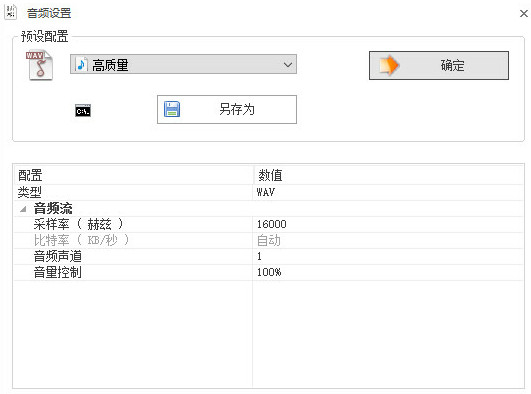
很高兴的是,经过格式工厂软件转换以后的音频文件能够被百度语音识别 REST 服务识别,识别度还不错,这是令人兴奋的。
但是,我又遇到了另一个问题,在服务器上总不能每个从客户端传来的音频文件都用格式工厂转换吧。于是,我找到了 Linux 平台上一款很好用的软件 sox。使用 sox 命令进行格式转换的命令格式:
sox 原始文件名全路径 -r 16000 -c1 生成的文件名全路径接下来,我又继续查找资料,在 Linux 上调用 Linux 平台上的服务可以使用Java 中的 Runtime 和 Process 类运行外部程序。
参考代码:
String[] cmdStrings = new String[] { "/usr/bin/sox", tempWavFileName, "-r", "16000", "-c1", soundFileName_16000 };
Process psProcess = Runtime.getRuntime().exec(cmdStrings);
psProcess.waitFor();到这里,语音识别开发的难点都攻克了。现在总结下来,真的是收获了不少。在这里先做个记录,有些知识点的掌握我还不是很透彻,后续还要再完善一下。
本文链接:https://my.lmcjl.com/post/11168.html
4 评论