一、ACID属性
Atomicity(原子性)
当前事务内的所有操作要么全部成功,要么全部失败
主要通过mysql的undo log日志来实现,假设A向B转账500元,A要减500元,B加500元,在操作更新的时候,mysql会记录undo log日志,如果是update就会记录更新前的值,如果是新增,undo log就是生成一条删除sql,两个操作要么同时成功,如果失败,mysql会根据undo log日志进行回滚
Consistency(一致性)
事务开始前和结束后,按照事务执行达到预期的结果
还是上面那个例子,假设A向B转账500元,A要减500元,B加500元,不能出现A减成功,B加失败的情况,在代码中异常没有抛出被catch了,导致事务没有回滚
Isolation(隔离性)
事务A在做操作时不受其它事务的影响,隔离性是由锁和MVCC机制来实现
Durability(持久性)
数据库一旦提交了事务,数据的修改和新增就永远存在数据库里,不会因为宕机、断电而丢失,由redo log来实现(为什么不用索引文件而用redo log,因为存储引擎innodb的ibd文件有多个,而redo log可以磁盘顺序写,可以提高效率)
二、mysql事务隔离级别
CREATE TABLE `account` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(255) DEFAULT NULL,`balance` int(11) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;INSERT INTO `test`.`account` (`name`, `balance`) VALUES ('test1', '1000');INSERT INTO `test`.`account` (`name`, `balance`) VALUES ('test2', '2000');INSERT INTO `test`.`account` (`name`, `balance`) VALUES ('test3', '3000');设置事务隔离级别8.0之前可以使用:
set tx_isolation='READ-UNCOMMITTED';
set tx_isolation='READ-COMMITTED';
set tx_isolation='REPEATABLE-READ';
set tx_isolation='SERIALIZABLE';show variables like 'tx_isolation';#查看数据库事务隔离级别mysql8.0废弃了tx_isolation,用transaction_isolation代替
set global TRANSACTION ISOLATION level read COMMITTED;#全局设置事务隔离级别为读已提交
show global variables like 'transaction_isolation';#查看全局的事务隔离级别set session TRANSACTION ISOLATION level read UNCOMMITTED;#设置当前session隔离级别为读未提交
set session TRANSACTION ISOLATION level read COMMITTED;#设置当前session隔离级别为读已提交
set session TRANSACTION ISOLATION level repeatable read;#设置当前session隔离级别为可重复读
set session TRANSACTION ISOLATION level serializable;#设置当前session隔离级别为串行化
show variables like 'transaction_isolation';#查看当前session隔离级别1、读未提交
事务A读取到了事务B未提交的数据
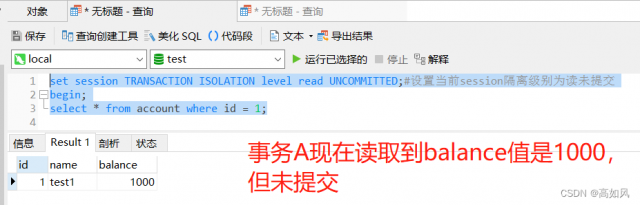
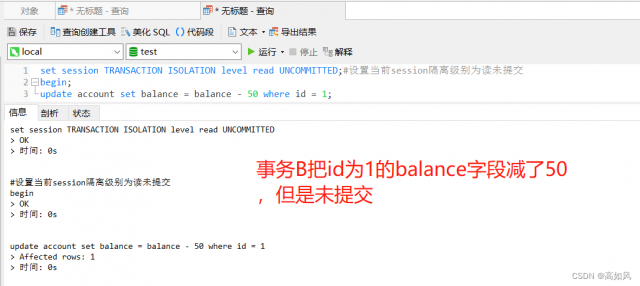
B事务在进行修改时会针对account表d为1的记录加一个行锁(悲观锁),其它事务对id为1的数据进行操作时要等待当前B事务执行完释放锁才能执行
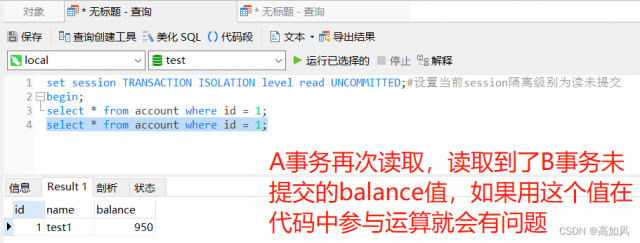
想象一下如果B事务回滚了,我们再在A事务进行减50,结果会是如何?
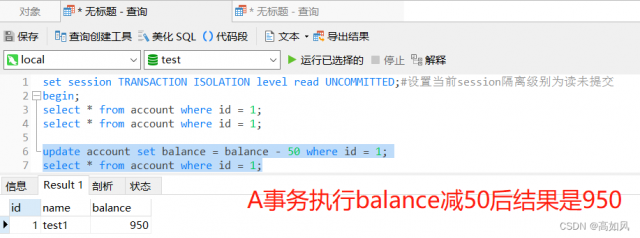
虽然A事务在查询时,balance值是950,但是真正参与减50的是数据库最新提交真实的值
脏读:读到未提交的数据
脏写:把未提交的数据用到代码运算后直接写到数据库中,这种用乐观锁可以解决,假设有A事务需要修改balance,B事务这时候也在修改balance,顺便修改version,即便A读到B事务修改version后的值,这时候B事务如果rollback,那A事务更改失败,提交,A事务更新成功,也都没问题
2、读已提交
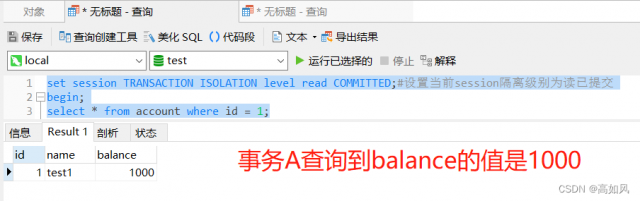
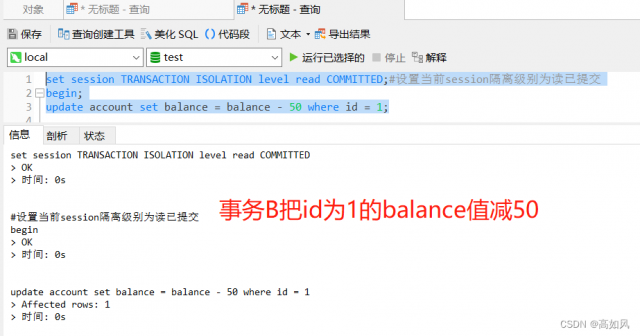
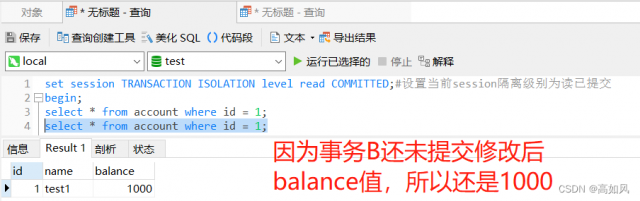
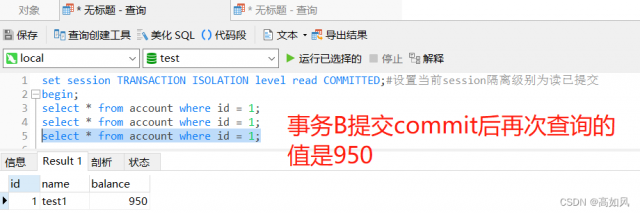
不可重复读:假设A事务在查询一次被B事务修改后的balance值后得到是950,但是事务是并发执行的,id为1的这条记录也有可能被其它事务进行修改,那么A事务如果查询多次的话,那么每次balance的值都会更改,这样对写代码非常不友好
脏写:有可能在A事务中拿到B事务提交的值进行代码运算,然后直接修改表的balance值,这样就有可能导致数据错误,这种就可以用乐观锁来解决,在表中加一个version字段,每次修改都加1,这样就可以根据读到的已提交的version字段来进行条件匹配更改,如果version不匹配那就更改不成功
3、可重复读
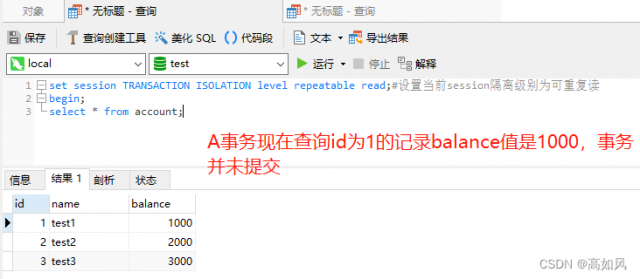
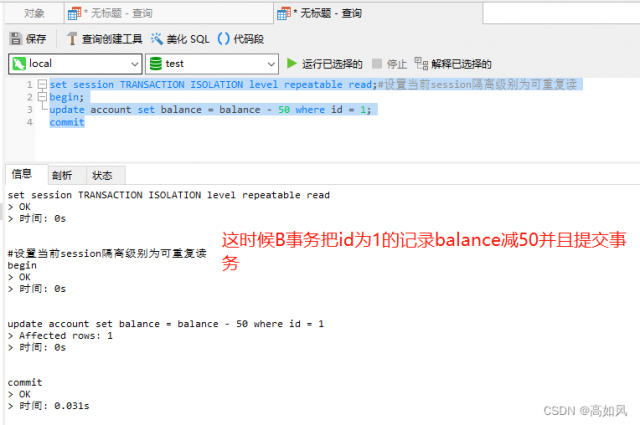
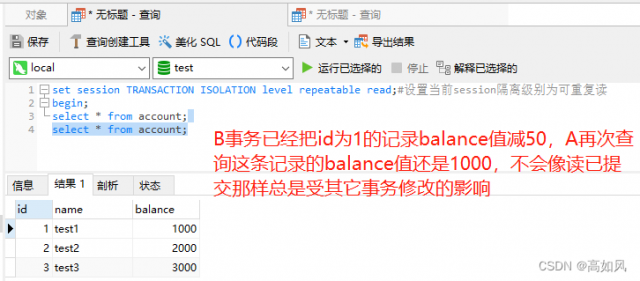
可重复读不管你修改哪个表的记录,在一个事务中还是最先读取的那个快照版本数据,其它表也是那个查询时刻的值;一个事务中更新之后,查询的是更新后的快照
幻读:事务A读取到了事务B新增的数据
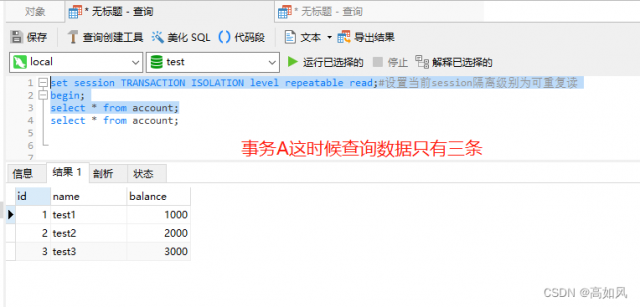
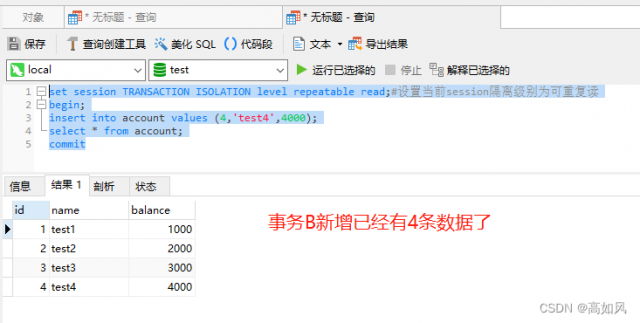
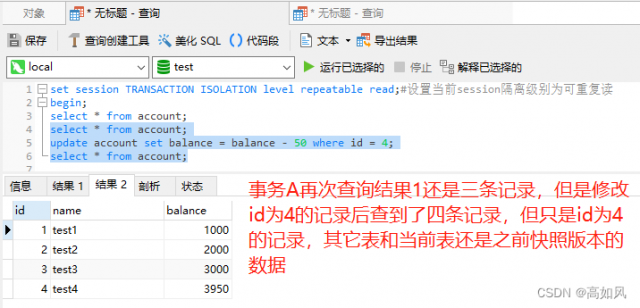
脏写:在可重复读级别不能通过乐观锁来解决脏写,因为每次读取的数据都是快照版本,中间可能有其它事务修改修改了version值,如果事务并发量特别大的情况,可能永远获取不到真实的version值
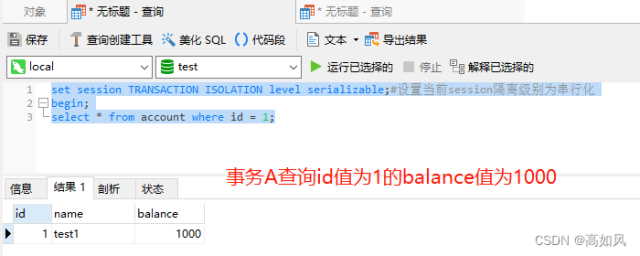
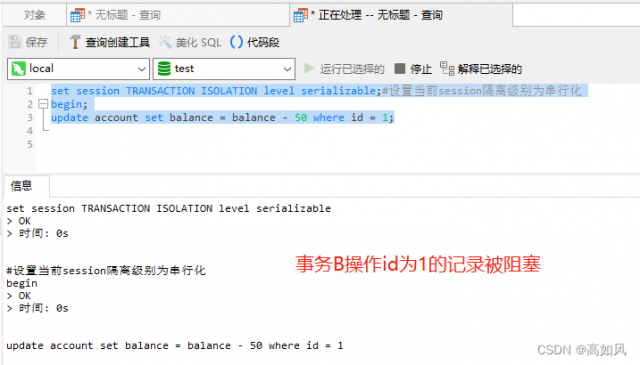
4、串行化
串行化会在操作行加把锁,如果是读会阻塞写(插入、修改和删除),写会阻塞写和读,这种就可以避免幻读,读的话会阻塞写
5、读锁和写锁
- 读锁(共享锁 S锁)select ... lock in share mode;
多个事务可以同时读取这条锁定数据,但是不允许修改
- 写锁(排它锁 X锁)select ... for update;
insert、update、delete都会加写锁,写锁会阻塞其它事务的写和读
读锁和写锁合起来就是串行化的实现
6、查询操作要不要加事务
读未提交容易导致数据出问题,串行化事务操作慢,在工作中一般用的就是读已提交和可重复读,如果是可重复读级别,为了达到可重复读级别效果需要加一个事务,因为如果不加事务,再读一次数据已经被修改了,不是一个时间节点的数据了,可重复读的目的就是在一个事务中读取的是瞬时数据,其它事务再做任何修改都还是之前那份数据;如果是读已提交或者没事务,那加不加事务其实差不多,因为事务是并发执行的,数据是不断修改提交的,两个查询在一个事务中都不是一个时间维度,所以不加还好点,这样可以提高性能
7、大事务影响
- 并发量大情况下,占用大量连接
- 锁定数据太多,造成大量阻塞和锁超时
- 执行时间长,容易造成主从延迟
- undo log膨胀
- 回滚时间长
- 容易导致死锁
8、事务优化
- 将查询数据操作放到事务外
- insert和update,update在后insert在前,因为update是更改已经存在的行记录,为了避免其它事务等待锁,所以放到后面
- 事务内远程调用要设置超时时间,避免长时间占用资源
- 大事务可以分解成多个小事务
- 能异步处理尽量异步处理
- 不用事务,在代码中保证事务,手动回滚事务,效率是非常快(不推荐)
本文链接:https://my.lmcjl.com/post/13860.html
4 评论