什么是pix2pix Gan


普通的GAN接收的G部分的输入是随机向量,输出是图像
;D部分接收的输入是图像(生成的或是真实的),输出是对或
者错。这样G和D联手就能输出真实的图像。
对于图像翻译任务来说,它的G输入显然应该是一张图x,
输出当然也是一张图y。
不需要添加随机输入。
对于图像翻译这些任务来说,输入和输出之间会共享很多
的信息。比如轮廓信息是共享的。
如果使用普通的卷积神经网络,那么会导致每一层都承载
保存着所有的信息,这样神经网络很容易出错。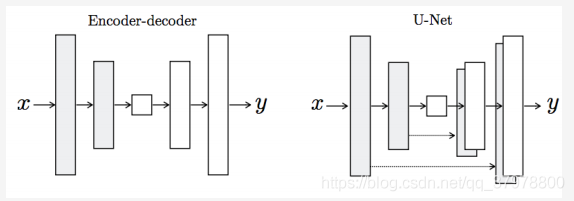
U-Net也是Encoder-Decoder模型,是变形的EncoderDecoder模型。
所谓的U-Net是将第i层拼接到第n-i层,这样做是因为第i层
和第n-i层的图像大小是一致的,可以认为他们承载着类似
的信息。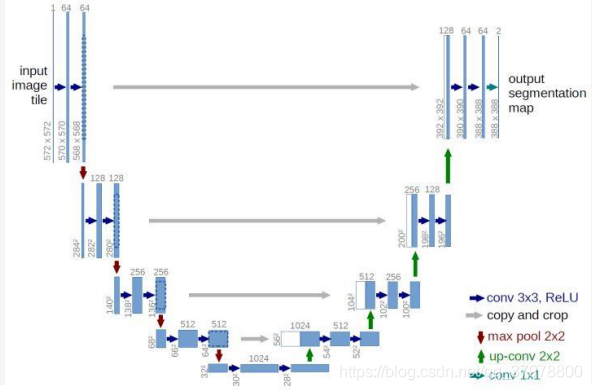
但是D的输入却应该发生一些变化,因为除了要生成真实图
像之外,还要保证生成的图像和输入图像是匹配的。
于是D的输入就做了一些变动。
D中要输入成对的图像。这类似于conditonal GAN

Pix2Pix中的D被论文中被实现为Patch-D,所谓Patch,是
指无论生成的图像有多大,将其切分为多个固定大小的
Patch输入进D去判断。
这样设计的好处是: D的输入变小,计算量小,训练速度快。
D网络损失函数:
输入真实的成对图像希望判定为1.
输入生成图像与原图像希望判定为0 G网络损失函数:
输入生成图像与原图像希望判定为1
对于图像翻译任务而言,G的输入和输出之间其实共享了很
多信息,比如图像上色任务,输入和输出之间就共享了边信
息。因而为了保证输入图像和输出图像之间的相似度,还加
入了L1 Loss
cGAN,输入为图像而不是随机向量
U-Net,使用skip-connection来共享更多的信息
Pair输入到D来保证映射
Patch-D来降低计算量提升效果
L1损失函数的加入来保证输入和输出之间的一致性.


(论文地址: https://phillipi.github.io/pix2pix/)
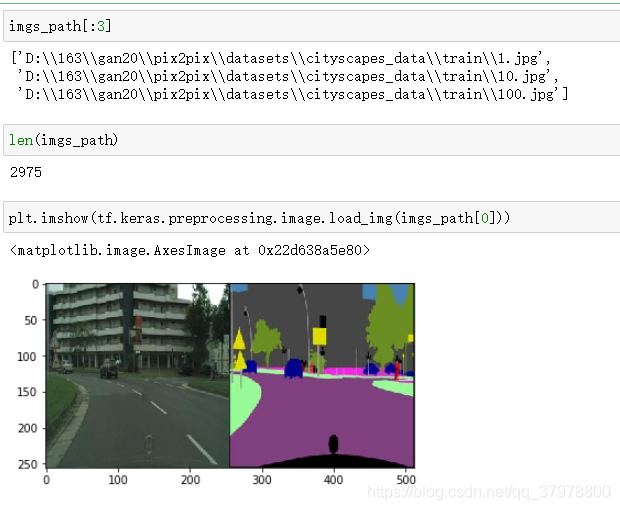
所使用的版本,是原数据集的一部分。
数据集中 语义分割图 与 原始图像 一起显示在图片中。这是
用于语义分割任务的最佳数据集之一。
数据集包含 2975 张训练图片和 500 张验证图片。
每个图像文件是 256x512 像素,每张图片都是一个组合,
图像的左半部分是原始照片,
右半部分是标记图像(语义分割输出)
代码
import tensorflow as tf
import os
import glob
from matplotlib import pyplot as plt
%matplotlib inline
import time
from IPython import display
imgs_path = glob.glob(r'D:163gan20pix2pixdatasetscityscapes_datatrain*.jpg')
def read_jpg(path):
img = tf.io.read_file(path)
img = tf.image.decode_jpeg(img, channels=3)
return img
def normalize(input_image, input_mask):
input_image = tf.cast(input_image, tf.float32)/127.5 - 1
input_mask = tf.cast(input_mask, tf.float32)/127.5 - 1
return input_image, input_mask
def load_image(image_path):
image = read_jpg(image_path)
w = tf.shape(image)[1]
w = w // 2
input_image = image[:, :w, :]
input_mask = image[:, w:, :]
input_image = tf.image.resize(input_image, (64, 64))
input_mask = tf.image.resize(input_mask, (64, 64))
if tf.random.uniform(()) > 0.5:
input_image = tf.image.flip_left_right(input_image)
input_mask = tf.image.flip_left_right(input_mask)
input_image, input_mask = normalize(input_image, input_mask)
return input_mask, input_image
dataset = tf.data.Dataset.from_tensor_slices(imgs_path)
train = dataset.map(load_image, num_parallel_calls=tf.data.experimental.AUTOTUNE)

BATCH_SIZE = 8
BUFFER_SIZE = 100
train_dataset = train.shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
train_dataset = train_dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
plt.figure(figsize=(5, 2))
for img, musk in train_dataset.take(1):
plt.subplot(1,2,1)
plt.imshow(tf.keras.preprocessing.image.array_to_img(img[0]))
plt.subplot(1,2,2)
plt.imshow(tf.keras.preprocessing.image.array_to_img(musk[0]))
imgs_path_test = glob.glob(r'D:163gan20pix2pixdatasetscityscapes_dataval*.jpg')

dataset_test = tf.data.Dataset.from_tensor_slices(imgs_path_test)
def load_image_test(image_path):
image = read_jpg(image_path)
w = tf.shape(image)[1]
w = w // 2
input_image = image[:, :w, :]
input_mask = image[:, w:, :]
input_image = tf.image.resize(input_image, (64, 64))
input_mask = tf.image.resize(input_mask, (64, 64))
input_image, input_mask = normalize(input_image, input_mask)
return input_mask, input_image
dataset_test = dataset_test.map(load_image_test)
dataset_test = dataset_test.batch(BATCH_SIZE)
plt.figure(figsize=(5, 2))
for img, musk in dataset_test.take(1):
plt.subplot(1,2,1)
plt.imshow(tf.keras.preprocessing.image.array_to_img(img[0]))
plt.subplot(1,2,2)
plt.imshow(tf.keras.preprocessing.image.array_to_img(musk[0]))

OUTPUT_CHANNELS = 3
def downsample(filters, size, apply_batchnorm=True):
# initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2D(filters, size, strides=2, padding='same',
use_bias=False))
if apply_batchnorm:
result.add(tf.keras.layers.BatchNormalization())
result.add(tf.keras.layers.LeakyReLU())
return result
def upsample(filters, size, apply_dropout=False):
# initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2DTranspose(filters, size, strides=2,
padding='same',
use_bias=False))
result.add(tf.keras.layers.BatchNormalization())
if apply_dropout:
result.add(tf.keras.layers.Dropout(0.5))
result.add(tf.keras.layers.ReLU())
return result
def Generator():
inputs = tf.keras.layers.Input(shape=[64,64,3])
down_stack = [
downsample(32, 3, apply_batchnorm=False), # (bs, 32, 32, 32)
downsample(64, 3), # (bs, 16, 16, 64)
downsample(128, 3), # (bs, 8, 8, 128)
downsample(256, 3), # (bs, 4, 4, 256)
downsample(512, 3), # (bs, 2, 2, 512)
downsample(512, 3), # (bs, 1, 1, 512)
]
up_stack = [
upsample(512, 3, apply_dropout=True), # (bs, 2, 2, 1024)
upsample(256, 3, apply_dropout=True), # (bs, 4, 4, 512)
upsample(128, 3, apply_dropout=True), # (bs, 8, 8, 256)
upsample(64, 3), # (bs, 16, 16, 128)
upsample(32, 3), # (bs, 32, 32, 64)
]
# initializer = tf.random_normal_initializer(0., 0.02)
last = tf.keras.layers.Conv2DTranspose(OUTPUT_CHANNELS, 3,
strides=2,
padding='same',
activation='tanh') # (bs, 64, 64, 3)
x = inputs
# Downsampling through the model
skips = []
for down in down_stack:
x = down(x)
skips.append(x)
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
x = tf.keras.layers.Concatenate()([x, skip])
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
generator = Generator()
#tf.keras.utils.plot_model(generator, show_shapes=True, dpi=64)
LAMBDA = 10
def generator_loss(disc_generated_output, gen_output, target):
gan_loss = loss_object(tf.ones_like(disc_generated_output), disc_generated_output)
# mean absolute error
l1_loss = tf.reduce_mean(tf.abs(target - gen_output))
total_gen_loss = gan_loss + (LAMBDA * l1_loss)
return total_gen_loss, gan_loss, l1_loss
def Discriminator():
# initializer = tf.random_normal_initializer(0., 0.02)
inp = tf.keras.layers.Input(shape=[64, 64, 3], name='input_image')
tar = tf.keras.layers.Input(shape=[64, 64, 3], name='target_image')
x = tf.keras.layers.concatenate([inp, tar]) # (bs, 64, 64, channels*2)
down1 = downsample(32, 3, False)(x) # (bs, 32, 32, 32)
down2 = downsample(64, 3)(down1) # (bs, 16, 16, 64)
down3 = downsample(128, 3)(down2) # (bs, 8, 8, 128)
conv = tf.keras.layers.Conv2D(256, 3, strides=1,
padding='same',
use_bias=False)(down3) # (bs, 8, 8, 256)
batchnorm1 = tf.keras.layers.BatchNormalization()(conv)
leaky_relu = tf.keras.layers.LeakyReLU()(batchnorm1)
last = tf.keras.layers.Conv2D(1, 3, strides=1)(leaky_relu) # (bs, 8, 8, 1)
return tf.keras.Model(inputs=[inp, tar], outputs=last)
discriminator = Discriminator()
#tf.keras.utils.plot_model(discriminator, show_shapes=True, dpi=64)
loss_object = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(disc_real_output, disc_generated_output):
real_loss = loss_object(tf.ones_like(disc_real_output), disc_real_output)
generated_loss = loss_object(tf.zeros_like(disc_generated_output), disc_generated_output)
total_disc_loss = real_loss + generated_loss
return total_disc_loss
generator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
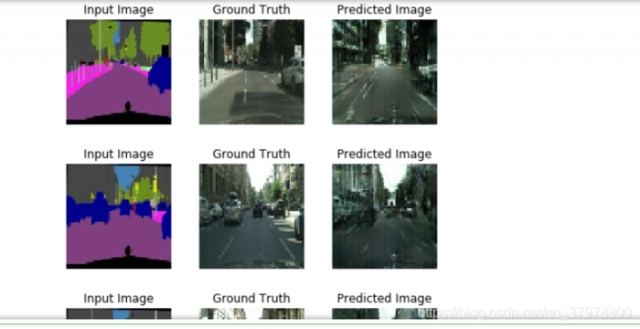
def generate_images(model, test_input, tar):
prediction = model(test_input, training=True)
plt.figure(figsize=(7, 2))
display_list = [test_input[0], tar[0], prediction[0]]
title = ['Input Image', 'Ground Truth', 'Predicted Image']
for i in range(3):
plt.subplot(1, 3, i+1)
plt.title(title[i])
# getting the pixel values between [0, 1] to plot it.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
for example_input, example_target in dataset_test.take(1):
generate_images(generator, example_input, example_target)

EPOCHS = 110
@tf.function
def train_step(input_image, target, epoch):
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
gen_output = generator(input_image, training=True)
disc_real_output = discriminator([input_image, target], training=True)
disc_generated_output = discriminator([input_image, gen_output], training=True)
gen_total_loss, gen_gan_loss, gen_l1_loss = generator_loss(disc_generated_output, gen_output, target)
disc_loss = discriminator_loss(disc_real_output, disc_generated_output)
generator_gradients = gen_tape.gradient(gen_total_loss,
generator.trainable_variables)
discriminator_gradients = disc_tape.gradient(disc_loss,
discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(generator_gradients,
generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(discriminator_gradients,
discriminator.trainable_variables))
def fit(train_ds, epochs, test_ds):
for epoch in range(epochs+1):
if epoch%10 == 0:
for example_input, example_target in test_ds.take(1):
generate_images(generator, example_input, example_target)
print("Epoch: ", epoch)
for n, (input_image, target) in train_ds.enumerate():
if n%10 == 0:
print('.', end='')
train_step(input_image, target, epoch)
print()
fit(train_dataset, EPOCHS, dataset_test)



AD_EPOCHS = 50
fit(train_dataset, AD_EPOCHS, dataset_test)


generator.save('pix2pix.h5')
for input_image, ground_true in dataset_test:
generate_images(generator, input_image, ground_true)

本文链接:https://my.lmcjl.com/post/16525.html
4 评论