论文和源码见个人主页:https://download.csdn.net/download/qq_45874683/85002721
(论文加源码)基于DEAP数据集的1D-CNN和RNN情感分类(GRU和LSTM)
摘要:
在这里,我们研究了脑电情绪的分类方法,并提出了两种模型来解决这一问题,它们是两种深度学习结构的混合:一维卷积神经网络(CNN-1D)和循环神经网络(RNN)。我们在RNN体系结构中实现了递归单元(GRU)和长短时记忆(LSTM),这是专门为解决消失梯度问题而设计的,消失梯度问题通常成为时间序列数据集中的一个问题。我们使用该模型从价-觉醒平面对四个情绪区域进行分类:高价-高觉醒(HVHA)、高价-低觉醒(HVLA)、低价-高觉醒(LVHA)和低价-低觉醒(LVLA)。也就是四分类代码。这个实验是在著名的DEAP数据集上实现的。实验结果表明,该方法在1DCNN-GRU模型和1DCNN-LSTM模型中的训练准确率分别为96.3%和97.8%。因此,这两种模型对执行这种情绪分类任务都非常好。
简介:
在这项研究中,我们建议使用更简单的信号处理方法来准备DEAP数据集,然后再将其输入到我们的模型中。我们还提出了两种神经网络结构的组合作为我们的模型,即CNN和RNN。我们选择一维CNN作为CNN架构,对于RNN,我们将评估GRU和LSTM的性能,我们将与1D-CNN结合在一起。随后,将比较1D-CNN+GRU和1D-CNN+LSTM两种模型在训练、验证和测试过程中的准确性和损失值。
实验方法:
首先,本节将详细阐述本研究中使用的数据集的细节,以及如何对数据进行分类。然后,将详细讨论所提出的实验方法。
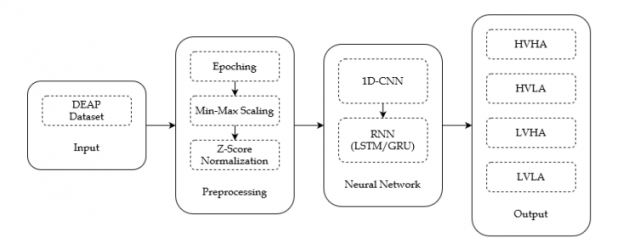
如图1所示,本研究的框架由两个主要过程组成,即数据预处理部分和神经网络部分。每个过程的细节将在下一节中解释。
在这项研究中,我们使用了DEAP数据集的预处理版本。这一版本的信号已被下采样至128 Hz,并通过带宽为4-45 Hz的带通滤波器进行滤波。EOG伪影也被移除。每个视频/试验的评分从1分到9分。评分越低,情绪越弱,评分越高,情绪越强烈。根据效价阈值和唤醒值将数据集分为4类,然后将其分为以下四类:高价高唤醒(HVHA)、高价低唤醒(HVLA)、低价高唤醒(LVHA)和低价低唤醒(LVLA)。该分类中使用的阈值为5。如果该值大于5,则将其归类为高,否则为低。

为了降低本研究的计算成本,并非所有通道都被选择。只有14个通道可以进一步处理情绪分类任务。这种通道选择基于代表情绪状态的大脑区域的重要性。表3列出了这些频道。这项任务是在我们将标签分为四类后完成的:HVHA、HVLA、LVHA、LVLA。因此,它将提高训练精度,同时减少验证损失。

数据预处理
为了在将DEAP数据集输入我们提出的模型之前准备好它,必须首先对其进行处理,以获得更好的训练结果。在下面的章节中,我们将详细描述我们的数据预处理方法。
Epoching:
Epoching是从连续的脑电信号中提取特定时间窗的过程。首先,这个任务是通过用2秒的时间步长提取每个信号的2秒波长来完成的。因此,它将为每个通道提供31个信号,每个epoch有256个数据点,代表信号的2秒。
Epoching过程后的信号示例:

标准化处理
本研究中使用的数据集中的每个信号将首先通过两种方法进行标准化:z分数标准化,然后是最小-最大缩放。执行这两个过程是为了防止过度拟合,并提高模型的精度。
最终数据格式:
在本研究中,我们使用了32名受试者的所有预处理DEAP数据集。预处理后的数据集经过进一步的预处理过程和标签分类。然后,我们以60:20:20的比例将数据集随机分成训练、验证和测试数据。我们实验的数据形状如表所示。

调整超参数
为了得到好的结果,必须对超参数进行充分的调整。我们的体系结构最终确定的批量大小是256,使用的优化器是Adam。在反向传播过程中,用于更新权重的损失函数是分类交叉熵,因为我们使用多标签数据集。此外,我们使用值为10的回调方法来监控验证损失值。因此,两个模型的时间段将根据验证损失值而变化。

使用的平台框架:
所有实验都是使用Tensorflow框架版本2.5.0和Python版本3.7.10实现的。使用的工作站是MSI GF65 Thin 10SDR,其中包括Intel i7-10750H(12个CPU@2.6 GHz)、用于GPU加速的NVIDIA GeForce GTX 1660 Ti、500 GB SSD和8 GB RAM。
神经网络模型:
该方法采用的神经网络结构是一维卷积神经网络和循环神经网络。
1D-CNN – GRU:
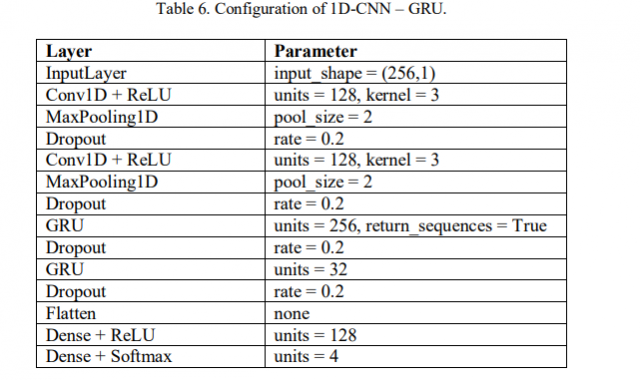
该模型由两种深度学习模型组成:1D-CNN和GRU。模型的结构如表6所示。网络的输入大小为256 x 1,对应于包含256个数据点的记录信号的两秒钟。我们将卷积滤波器的数量设置为128个,使用ReLU作为其激活层。在第一个卷积层之后是池大小为2的最大池层。我们在最大池层后设置了0.2的落差,以减少过度拟合的可能性。第二个卷积层与第一个卷积层相同。
卷积层之后是包含256个单元和32个单元的GRU层。在每个GRU层之后,我们还将退出层设置为0.2。在连接到稠密单元之前,执行展平操作以将特征转换为一维特征向量。使用ReLU激活功能将密集层单位设置为32。最后一层是4个单元密集层,代表四个分类标签。这个致密层的激活函数是softmax。该模型的可训练参数数量为378.820。
1D-CNN – LSTM:

该模型的配置与1D-CNN–GRU相同。唯一的区别是,我们用LSTM层替换GRU层。该模型的可训练参数为485.764,大于1DCNN-GRU模型。
实验结果
首先,我们将根据模型的准确性和损失值详细说明本研究中使用的两种模型的性能。接下来,我们将比较本实验中使用的GRU和LSTM的结果。稍后,将详细解释实验的总体结果和分析。
评估1D-CNN–GRU模型在情绪分类任务中的性能:
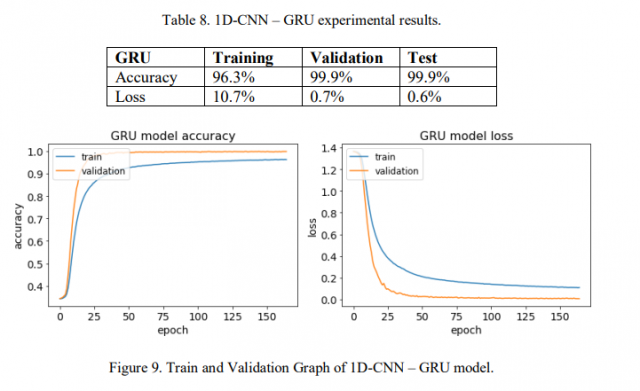
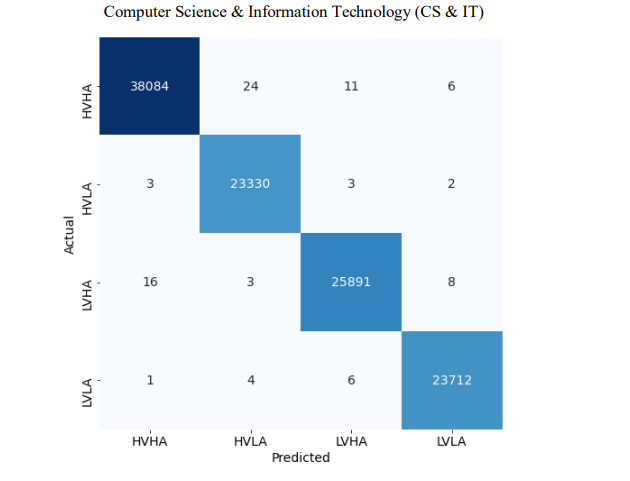
结果如表8所示。我们获得了96.3%的训练准确率,以及99%以上的验证和测试准确率。此外,我们还获得了10.7%、0.7%和0.6%的训练、验证和测试损失。与以往的相关工作相比,该模型表现出了很好的性能。如图9所示,训练图和验证图显示了每个epoch的精度和损耗变化的期望值。没有出现过拟合,训练过程在165轮停止。每个epoch的平均训练时间为50秒。此外,我们还制作了一个混淆矩阵来分析预测值和实际值之间的差异(图10)。此外,该技术很好地应用于多标签分类性能的测量。我们得到了F1分数和召回值1,这表明该模型的质量良好。
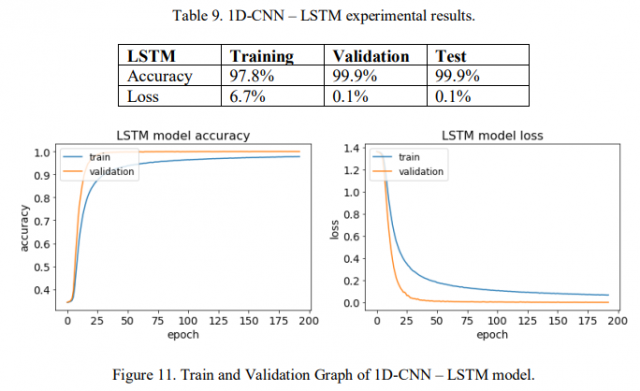
评估1D-CNN–LSTM模型执行情绪分类任务的性能:
表9显示了该实验的结果。我们获得了97.8%的训练准确率。该模型的验证和测试精度分别为99.9%和99.9%,高于第一个模型。除此之外,我们获得了6.7%的培训损失,验证和测试损失分别为0.1%和0.1%。
结论、局限性和未来工作:
在本文中,我们提出了更简单的信号处理方法以及1D-CNN–RNN混合模型来在DEAP数据集上执行情绪分类任务。两种模型的结果都表明,所提出的模型能够根据四种情绪状态(HVHA、HVLA、LVHA和LVLA)对脑电信号进行非常高的分类精度。1DCNN-LSTM体系结构的分类准确率为97.8%,略高于1DCNN-GRU体系结构的分类准确率为96.3%。1D-CNN结构在提取脑电信号特征方面表现出了良好的性能,而RNN结构GRU和LSTM能够很好地学习和处理时间序列信号的序列数据。
我们提出的模型的优点之一是简单。因此,该模型在输入模型之前不需要进行大量的信号预处理。
虽然该模型在情感分类任务中取得了显著的效果,但我们仍需要在其他数据集中对其进行进一步评估,并提高模型的鲁棒性。仍有一些局限性需要在下一步工作中加以解决。更具体地说,该模型仅使用DEAP数据集进行训练,尚未在其他受试者中进行测试。因此,在我们未来的工作中,我们打算使用另一个用于情绪识别研究的EEG数据集,如DREAMER和AMIGOS,对该模型进行重新训练和测试。此外,我们计划在下一步工作中实施k-折叠交叉验证,以便更准确地估计我们提出的方法的性能。
论文和源码见个人主页:https://download.csdn.net/download/qq_45874683/85002721
(论文加源码)基于DEAP数据集的1D-CNN和RNN情感分类(GRU和LSTM)
本文链接:https://my.lmcjl.com/post/18722.html
4 评论