目录
一、前言
二、Selenium反反爬操作
2.1、隐藏“正在受到自动软件的控制”
2.2、禁用 Blink 渲染引擎
2.3、Cookies 和 UA伪装
2.4、控制已打开的浏览器
三、自动化操作
3.1、问题遍历
3.2、获取回答
四、源码
一、前言
近日, ChatGPT在圈内大火。那么什么是ChatGPT呢?
ChatGPT是一种自然语言生成模型,由OpenAI开发。它基于GPT(Generative Pre-training Transformer)的技术架构,旨在更好地模拟人类的自然语言表达方式。
与GPT相比,ChatGPT具有更强的上下文感知能力,可以在继续对话的基础上生成文本。它的应用包括聊天机器人、对话系统、智能邮件助手等。
ChatGPT通过对大量的自然语言文本进行预训练,然后使用这些预训练权重来解决具体的任务。这种基于预训练的方法可以在计算资源有限的情况下获得很好的效果。
值得注意的是,ChatGPT仅是一种技术,并不能独立于特定的应用场景或者产品中使用。开发人员需要根据自己的需求设计应用程序,并使用ChatGPT来实现自然语言生成功能。

二、Selenium反反爬操作
2.1、隐藏“正在受到自动软件的控制”
当我们在使用webdriver时,浏览器上方总会出现 “正在受到自动软件控制” 字样
from selenium import webdriver
from selenium.webdriver.chrome.options import Optionsoptions = Options()
# 隐藏 正在受到自动软件的控制 这几个字
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
2.2、禁用 Blink 渲染引擎
"--disable-blink-features" 是一个命令行标志,可以传递给 Chrome 浏览器以禁用 Blink 渲染引擎的某些功能。Blink 渲染引擎被 Chrome 和其他基于 Chromium 的浏览器用来显示网页内容。
"--disable-blink-features" 标志接受一个由逗号分隔的要禁用的功能列表。可以使用此标志禁用的一些功能示例包括:
"AutomationControlled":禁用仅在 Chrome 由自动化控制时启用的功能(例如,在无头模式下运行或在 Selenium 控制下运行)。
"PreciseMemoryInfo":禁用准确测量内存使用情况的能力。
"PreciseTimeInfo":禁用准确测量时间的能力。
opt = webdriver.ChromeOptions()
# opt.add_argument("--incognito")
# opt.add_experimental_option('excludeSwitches', ['enable-automation'])
# opt.add_experimental_option('useAutomationExtension', False)
opt.add_argument("--disable-blink-features")
opt.add_argument("--disable-blink-features=AutomationControlled")2.3、Cookies 和 UA伪装
这个很简单,爬虫基本都会用到两者,通过添加Cookies可以让你的程序省去登陆步骤
cookies = {'domain': ".chat.openai.com",'name': '__Secure-next-auth.session-token','value': 'xxx','expires': 'Sat, 23-Dec-23 04:23:54 GMT','path': '/','HttpOnly': True,# 'HostOnly': True,'Secure': True,'SameSite': None
}
driver.get('https://chat.openai.com/chat')
driver.add_cookie(cookie_dict=cookies)2.4、控制已打开的浏览器
当使用一个新的web驱动器时会遇到很多问题,不如直接去控制一个已经打开的浏览器,就不用去设置那么多繁琐的参数。
首先,在你的谷歌输入如下网址
chrome://version/ 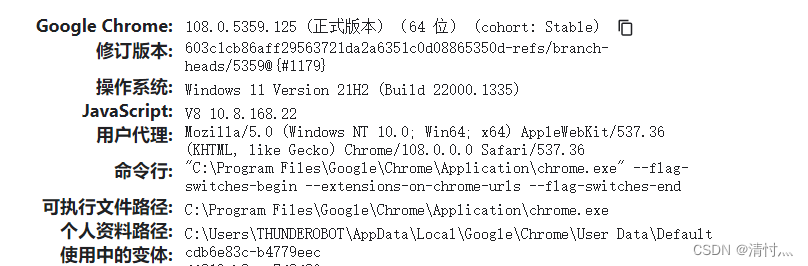
找到可执行文件路径,就是你的驱动器安装地址,在CMD中输入
"C:\Program Files\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222此时,你的谷歌就会打开一个新的窗口,下面在程序中输入
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.chrome.options import Optionsoptions = Options()
options.add_experimental_option("debuggerAddress", "localhost:9222")driver = webdriver.Chrome(executable_path=r"C:\Users\THUNDEROBOT\PycharmProjects\douban\Mr.Ding\chromedriver.exe", chrome_options=options)这样你就可以直接控制一个已打开的浏览器了。
三、自动化操作
3.1、问题遍历
观察网页结构,不难发现,类似于大多数网站输入,通过Key实现。这时我们可以想到用Selenium来实现

由此可以得到核心代码
question = driver.find_element(by=By.XPATH, value='//*[@id="__next"]/div/div/main/div[2]/form/div/div[2]/textarea').send_keys('hello')
进入对话框,同样观察网页结构,进行Xpath定位,可以得到如下的核心代码。其中,我们可以把要遍历的问题通过csv存储。

question_from_csv = driver.find_element(by=By.XPATH, value='//*[@id="__next"]/div/div/main/div[2]/form/div/div[2]/textarea').send_keys(df['问题'][i]3.2、获取回答
当输入问题后,GPT就会进行回答,那如何判断是否回答完成并且可以进行下一个问题的提问呢
观察右下角,当GPT在回答问题时,右下角是省略号,表示在进行回答;在回答完毕时,右下角是发送箭头,如下所示

可以通过检测是否存在该发送箭头来判断是否回答完毕
有如下核心代码
if driver.find_element(by=By.XPATH, value='//*[@id="__next"]/div/div/main/div[2]/form/div/div[2]/button') == True:当然,有时回答问题时间过长,我们可能只获取了一部分消息,那如何去获取完整的信息呢
睡眠嘛
回答一个问题大概时间是在一分钟多一点,我们可以让程序睡眠2个60s,来判断是否输出完成
四、源码
欢迎评论区技术交流哦~
# -*- coding = utf-8 -*-# "C:\Program Files\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222
import time
import pandas as pd
import time
import os
from docx import Document
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.chrome.options import Optionsoptions = Options()options.add_experimental_option("debuggerAddress", "localhost:9222")driver = webdriver.Chrome(executable_path=r"C:\Users\THUNDEROBOT\PycharmProjects\douban\Mr.Ding\chromedriver.exe", chrome_options=options)
# driver.implicitly_wait(10)
print("hello")
driver.get('https://chat.openai.com/chat')df = pd.read_csv('./问题合集.csv')
print(df['问题'][0])
print('等个5s')
print('Waiting........')
time.sleep(5)
question = driver.find_element(by=By.XPATH, value='//*[@id="__next"]/div/div/main/div[2]/form/div/div[2]/textarea').send_keys('hello')
botton = driver.find_element(by=By.XPATH, value='//*[@id="__next"]/div/div/main/div[2]/form/div/div[2]/button').click()
print('再等个5s, 还没出来')
print('Waiting........')
time.sleep(5)
if driver.find_element(by=By.XPATH, value='//*[@id="__next"]/div/div/main/div[2]/form/div/div[2]/button') == True:answer = driver.find_element(by=By.XPATH, value='//*[@id="__next"]/div/div/main/div[1]/div/div/div/div[2]/div/div[2]/div[1]/div/div/p').textprint(answer)
else:print('第三个15s')print('Waiting........')time.sleep(15)answer = driver.find_element(by=By.XPATH, value='//*[@id="__next"]/div/div/main/div[1]/div/div/div/div[2]/div/div[2]/div[1]/div/div/p').textprint(answer)print('Waiting........')
for i in range(0, 20):# 提问save_path = os.path.join(r"C:\Users\THUNDEROBOT\Desktop\百度文库", df['问题'][i] + ".docx")# 创建一个新的文档document = Document()question_from_csv = driver.find_element(by=By.XPATH, value='//*[@id="__next"]/div/div/main/div[2]/form/div/div[2]/textarea').send_keys(df['问题'][i] + ' (详细描述并用中文回答,不要让我说继续,一口气说完)')# time.sleep(5)# 点击发送botton_new = driver.find_element(by=By.XPATH, value='//*[@id="__next"]/div/div/main/div[2]/form/div/div[2]/button').click()# 主页面回答问题time.sleep(50)if driver.find_element(by=By.XPATH, value='//*[@id="__next"]/div/div/main/div[2]/form/div/div[2]/button') == True:answer_1 = driver.find_element(by=By.XPATH, value='//*[@id="__next"]/div/div/main/div[1]/div/div/div/div[{}]/div'.format(4+i*2)).textprint(answer_1)document.add_paragraph(answer_1)document.save(save_path)print('在第一个30s内完成')print('Waiting........')else:time.sleep(60)answer_1 = driver.find_element(by=By.XPATH, value='//*[@id="__next"]/div/div/main/div[1]/div/div/div/div[{}]/div'.format(4+i*2)).textprint(answer_1)document.add_paragraph(answer_1)document.save(save_path)print('在第二个30s内完成')print('Next question')本文链接:https://my.lmcjl.com/post/2296.html
4 评论