
大型语言模型(LLM)已成功地作为各种自然语言任务的通用接口,只要我们能够将输入和输出转换为文本,就可以将基于LLM的接口适应任务。尽管在自然语言处理中取得了成功的应用,但仍然难以将LLM用于处理多模态数据,例如图像和音频。
本论文提出了Kosmos-1,一种多模态大语言模型(MLLM),Kosmos-1可以感知常见模态,遵循指令和上下文学习。其目标是将视觉感知与LLM对齐,以便模型能够“看”和“说”。
多模态感知能力对于LLMs至关重要,因为它可以使LLMs获得文本描述之外的常识知识,解锁多模态输入大大扩展了语言模型的应用范围,涉及多模态机器学习,文档智能和机器人等高价值领域。
概括
作者使用大规模的多模态语料库对KOSMOS-1进行了从零开始的训练,包括任意交错的文本和图像、图像标题对和文本数据。作者在各种任务上进行了评估,包括零样本、少样本和多模态思维链提示,而且不需要任何梯度更新或微调。
除了各种自然语言任务外,KOSMOS-1模型本身还可以处理广泛的感知密集型任务,包括视觉对话、视觉解释、视觉问答、图像标注、简单数学方程等,
MLLMs具备感知能力后,可以直接从屏幕读取信息或从收据中提取数字,实现多个API的统一。
看题作答,轻松搞定~不仅能“看懂”图像,还能对答如流,并且能进行一定的数学计算。
甚至,看图进行连续对话功能也实现了。
作者还发现,MLLMs可以从跨模态转移中受益,即从语言到多模态和从多模态到语言的知识转移。此外,作者还介绍了一个Raven IQ测试数据集,用于诊断MLLMs的非语言推理能力。
Multimodal Large Language Model (MLLM)
KKOSMOS-1是基于Transformer语言模型,通过自回归方式学习生成文本。除了文本外,其他模态转成embedding后喂给模型。该模型在多模态语料库上进行训练,包括单模态数据、交叉模态配对数据。
该框架可以灵活处理各种数据类型,只要我们可以将输入表示为向量即可。MLLMs完美地融合了两大优势:1、语言模型自然地继承了上下文学习和指令跟随的能力。2、通过在多模态语料库上训练,补齐了语言模型的多模态感知能力。
MLLMs作为通用接口,可以处理自然语言和多模态输入。对于输入格式,我们使用 <s>和</s> 来表示序列的开始和结束。特殊标记<image>和</image>表示图像嵌入的开始和结束。例如,“<s> document </s>”是一个文本输入,“<s> paragraph <image> Image Embedding </image> paragraph </s>”是一个图像文本输入。获得输入序列后,将它们输入到Transfomer的解码器中,使用Softmax分类器来生成下一个预测。
我们使用MAGNETO(Transformer的变体)作为模型的主要结构,因为它训练稳定且非常适合多模态场景,它为每个子层引入额外的layernorm,且理论上拥有更好的初始化方法。为了更好地进行长序列建模,采用了名为 XPOS 的相对位置编码技术。该方法能够更好地适应不同长度的训练和测试序列,并且能够优化注意力分辨率,从而能够更精确地捕捉位置信息。
训练数据
训练数据集包括文本语料库、图像标题对和交错的图像和文本数据。
文本语料库我们用The Pile和Common Crawl (CC)训练我们的模型。The Pile是一个用于训练大规模语言模型的大型英文文本数据集,排除了来自GitHub、arXiv、Stack Exchange和PubMed Central的数据。还使用了Common Crawl快照(2020-50和2021-04)数据集、CC-Stories和RealNews数据集。已经去重并且过滤掉了下游任务数据。
图像标题对数据集,包括英文LAION-2B、LAION-400M、COYO-700M 和Conceptual Captions。图像文本数据是从Common Crawl快照中收集的多模态数据,这是一个公开可用的网页存档,从原始2B网页中选择约71M网页,从网页的HTML中提取文本和图像。对于每个文档,我们将图像的数量限制为五个,以减少噪声和冗余。
模型细节
KKOSMOS-1模型有24层,32个注意力头,Hidden size是2048,FFN隐层是8192维,大约有1.3B个参数,使用Magneto的初始化。为了更快的收敛,图像编码模型用CLIP ViT-L/14模型。我们在训练期间冻结除最后一层外的CLIP模型参数。所以KOSMOS-1的总参数数量约为1.6B。
Batchsize大小设置为120万个token(文本语料库500万,图像标题对500万,来自文本图像交错数据200万),训练了300k步,过了约3600亿个token。
为了更好地将KOSMOS-1与人类指令对齐,我们进行语言指令微调。具体来说,我们继续使用(指令,输入和输出)格式的指令数据对模型进行训练。指令数据是纯语言的,与训练语料混合在一起。将Unnatural Instructions和FLANv2 结合起来作为我们的指令数据集。Unnatural Instructions是使用大型语言模型为各种自然语言处理任务生成指令的数据集,有68,478个指令输入输出三元组。FLANv2是一系列涵盖各种类型语言理解任务的数据集,例如阅读理解,常识推理和封闭式问答。我们从FLANv2中随机选择54k个指令示例来增强我们的指令数据集。
实验效果
我们评估了KOSMOS-1在各种类型的任务上的表现,包括:
• 语言任务:语言理解、语言生成、无OCR文本分类
• 跨模态转移:常识推理
• 非语言推理 :智商测试
• 视觉-语言任务:图像标注、视觉问答、网页问答
• 视觉任务:zero-shot图像分类、带描述的zero-shot图像分类
非语言推理能力测试
非语言推理能力通常反映了个人的智商 (IQ)。模型在没有明确微调的情况下进行零样本非语言推理。RavenIQ测试类似于语言模型的上下文学习,区别在于上下文是非语言的还是语言的。为了推断出答案,模型必须识别抽象概念并识别给定图像的潜在模式。因此,IQ任务是衡量非语言情境学习能力的一个很好的测试平台。图4显示了一个示例,给定在 3 × 3 矩阵中呈现的八张图像,任务是从六个相似的候选者中识别出正确图形。


多模态思维链提示测试
思维链是模型发展到一定智能水平才突现出的高级能力,思维链提示允许大型语言模型生成一系列推理步骤并将复杂问题分解为多个子步骤解决。受思维链提示的启发,我们研究了KOSMOS-1的多模态思维链提示能力。
将感知语言任务分解为两个步骤:给定图像,使用提示引导模型生成描述,然后再进行问答。下面一个例子中,如果直接提问,模型给出了错误答案,但如果先提示模型:请描述下图片里的内容,然后再提问就会得到正确答案了。

视觉-语言任务测试
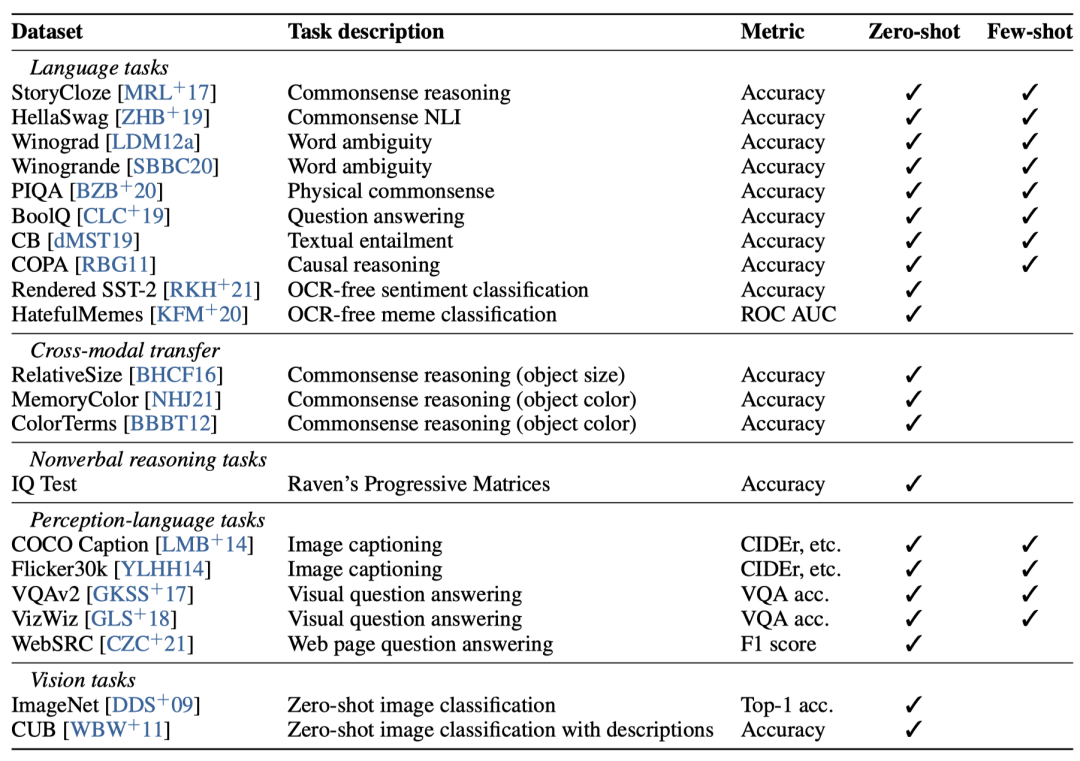
在zero-shot设置下,KOSMOS-1在两个图像标注数据集上取得了显着的效果。 k=2,4,8的few-shot设置下的指标
k=2,4,8的few-shot设置下的指标
作者还测试了图像分类、视觉问答等多个任务上的模型表现,KOSMOS-1都有显著的提升。具体任务测试有兴趣可以去看下原文。
跨模态迁移
跨模态可转移性允许模型从一种模态(如文本、图像、音频等)中学习,并将知识转移到其他模态。这种技能可以使模型在不同模态下执行各种任务。我们评估了KOSMOS-1在几个基准测试中的跨模型可转移性。
从语言到多模态的转移:仅语言指令调整
为了评估仅用语言指令调整的效果,我们使用了四个数据集进行消融研究:COCO、Flickr30k、VQAv2和VizWiz。这些数据集包括图像标注和视觉问答。评估指标为:COCO/Flickr30k的CIDEr分数和VQAv2/VizWiz的VQA准确性。
实验表明,仅语言指令调整可以显着提高模型在不同模态下的指令跟随能力。结果还表明,我们的模型可以将指令跟随能力从语言转移到其他模态。
从多模态到语言的转移:视觉常识推理
视觉常识推理任务需要理解现实世界中日常物品的属性,如颜色、大小和形状。这些任务对于语言模型来说是具有挑战性的,因为它们可能需要更多有关物体属性的信息,而这些信息在文本中并不容易获取。为了研究视觉常识能力,我们比较了KOSMOS-1和LLM在视觉常识推理任务上的零样本性能,使用纯文本作为输入,不包含任何图像。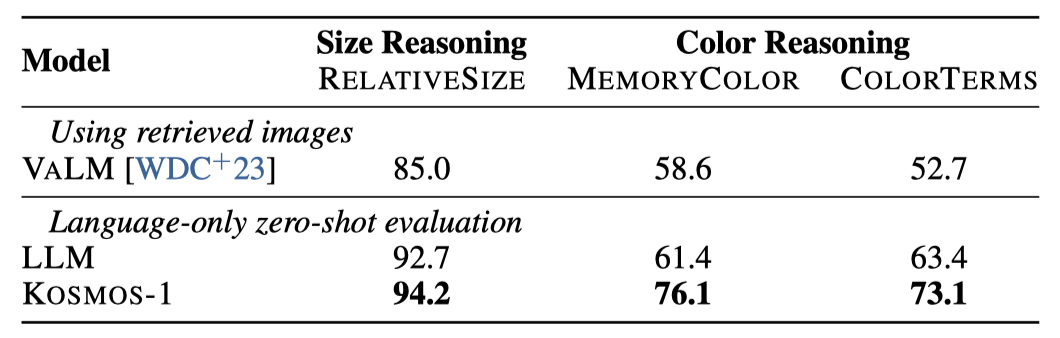
通过对比,结果表明KOSMOS-1在三个数据集上的表现均优于LLM,相对大小数据集上提高了1.5%,记忆颜色数据集上提高了14.7%,颜色术语数据集上提高了9.7%。这表明KOSMOS-1可以从视觉知识中获益,完成相应的视觉常识推理任务,而LLM只能依靠文本知识和线索来回答视觉常识问题,这限制了其推理物体属性的能力。
结论
语言和多模态感知的大融合是实现通用人工智能的关键一步。本文提出了KOSMOS-1,一个多模态大型语言模型,它可以感知多种模态,遵循指令,并进行上下文学习。通过在多模态语料库上进行训练,实现从LLM到MLLM的转变。未来可能的工作包括提高KOSMOS-1的模型规模,并将语音能力整合到其中。此外,KOSMOS-1可以作为多模态学习的统一接口,例如,可以使用指令和示例来控制文本到图像的生成。
本文链接:https://my.lmcjl.com/post/3712.html
4 评论