背景介绍
在微服务横行的时代,服务化思维逐渐成为了程序员的基本思维模式,但是,由于绝大部分项目只是一味地增加服务,并没有对其妥善管理,当接口出现问题时,很难从错综复杂的服务调用网络中找到问题根源,从而错失了止损的黄金时机。

而链路追踪的出现正是为了解决这种问题,它可以在复杂的服务调用中定位问题,还可以在新人加入后台团队之后,让其清楚地知道自己所负责的服务在哪一环。

除此之外,如果某个接口突然耗时增加,也不必再逐个服务查询耗时情况,我们可以直观地分析出服务的性能瓶颈,方便在流量激增的情况下精准合理地扩容。
链路追踪
“链路追踪”一词是在2010年提出的,当时谷歌发布了一篇Dapper论文,介绍了谷歌自研的分布式链路追踪的实现原理,还介绍了他们是怎么低成本实现对应用透明的。
其实Dapper一开始只是一个独立的调用链路追踪系统,后来逐渐演化成了监控平台,并且基于监控平台孕育出了很多工具,比如实时预警、过载保护、指标数据查询等。
除了谷歌的dapper,还有一些其他比较有名的产品,比如阿里的鹰眼、大众点评的CAT、Twitter的Zipkin、Naver(著名社交软件LINE的母公司)的pinpoint以及国产开源的skywalking等。
基本实现原理
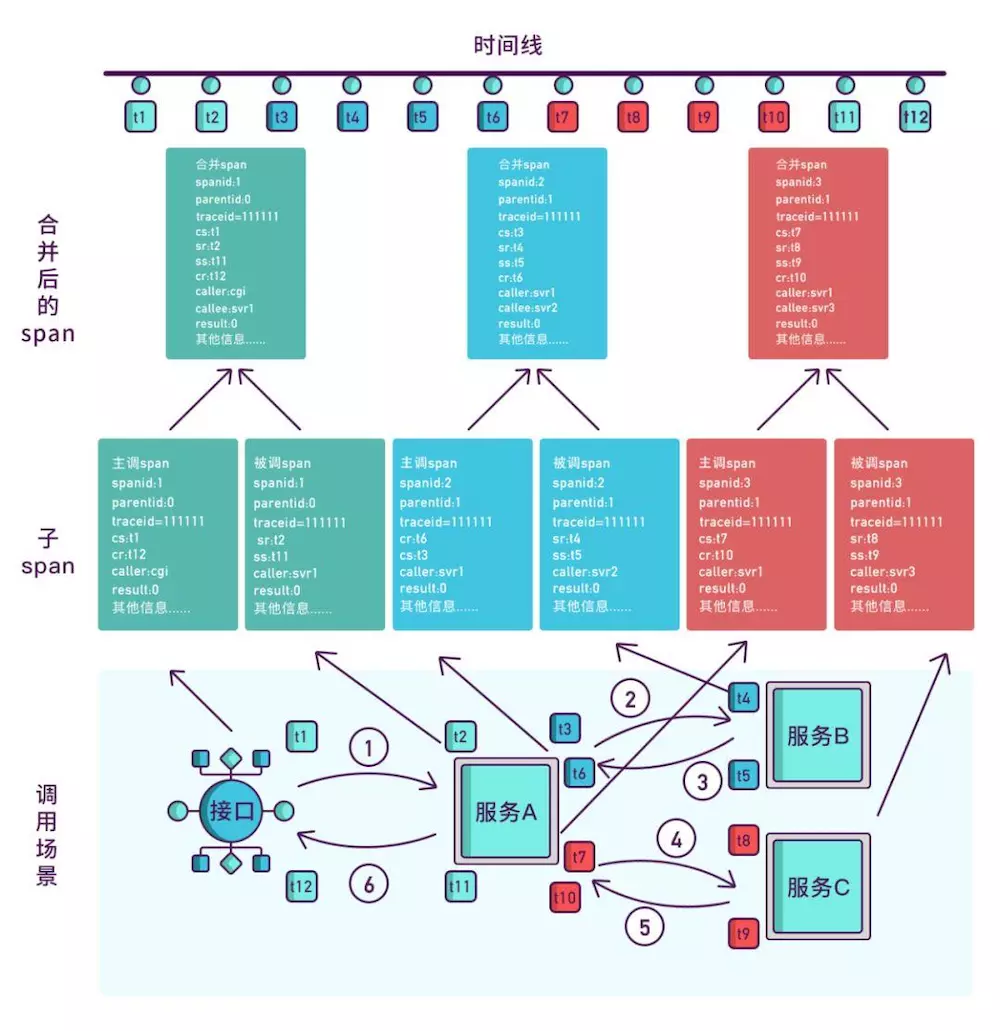
如果想知道一个接口在哪个环节出现了问题,就必须清楚该接口调用了哪些服务,以及调用的顺序,如果把这些服务串起来,看起来就像链条一样,我们称其为调用链。
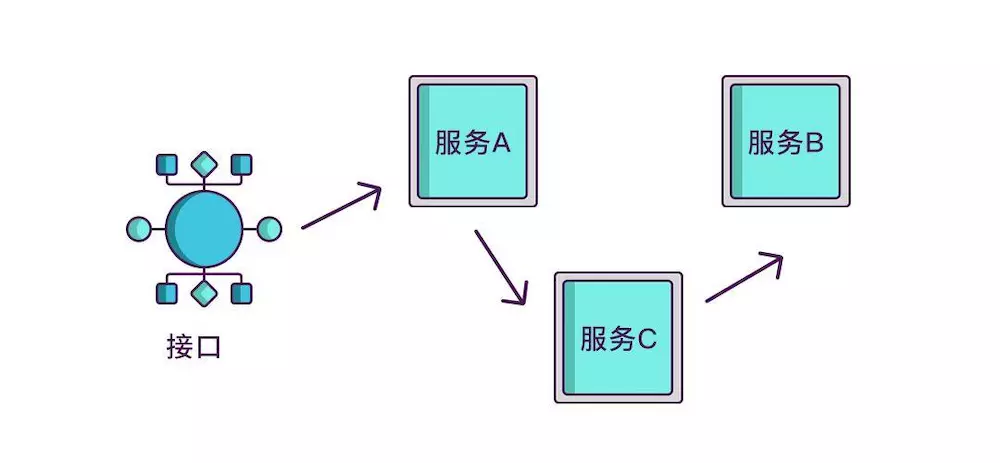
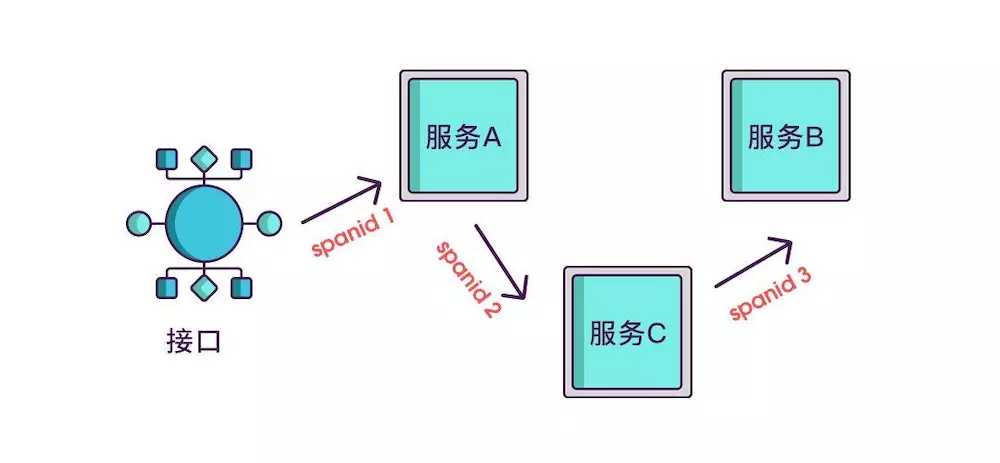
想要实现调用链,就要为每次调用做个标识,然后将服务按标识大小排列,可以更清晰地看出调用顺序,我们暂且将该标识命名为spanid。
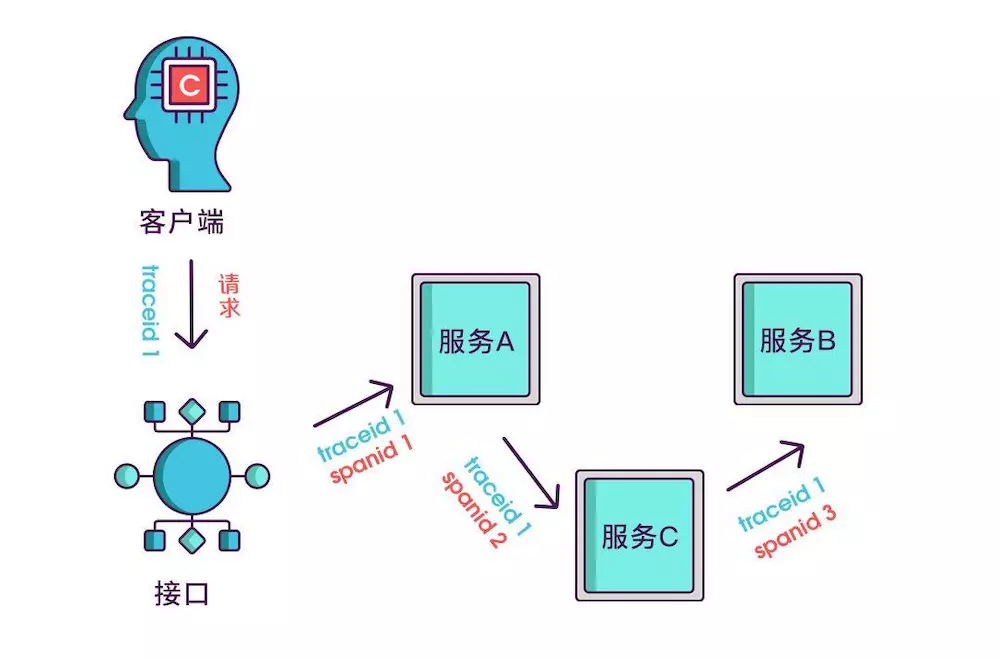
实际场景中,我们需要知道某次请求调用的情况,所以只有spanid还不够,得为每次请求做个唯一标识,这样才能根据标识查出本次请求调用的所有服务,而这个标识我们命名为traceid。
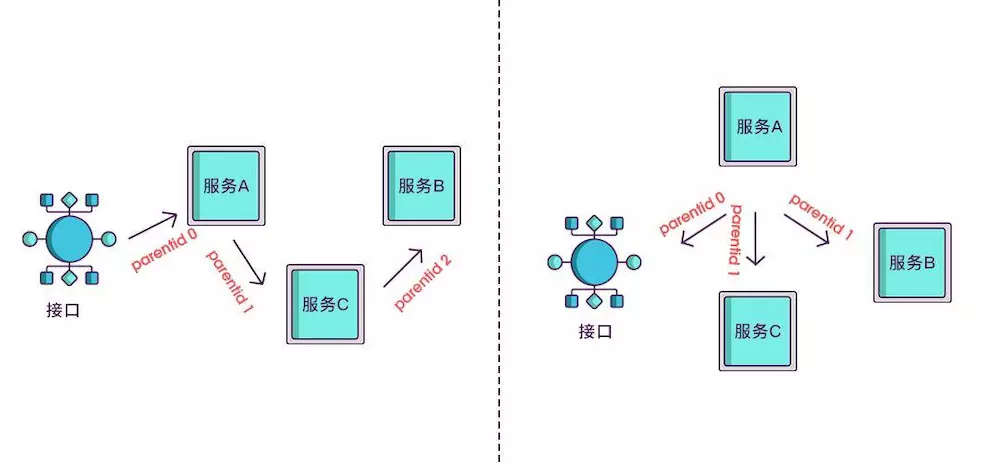
现在根据spanid可以轻易地知道被调用服务的先后顺序,但无法体现调用的层级关系,正如下图所示,多个服务可能是逐级调用的链条,也可能是同时被同一个服务调用。
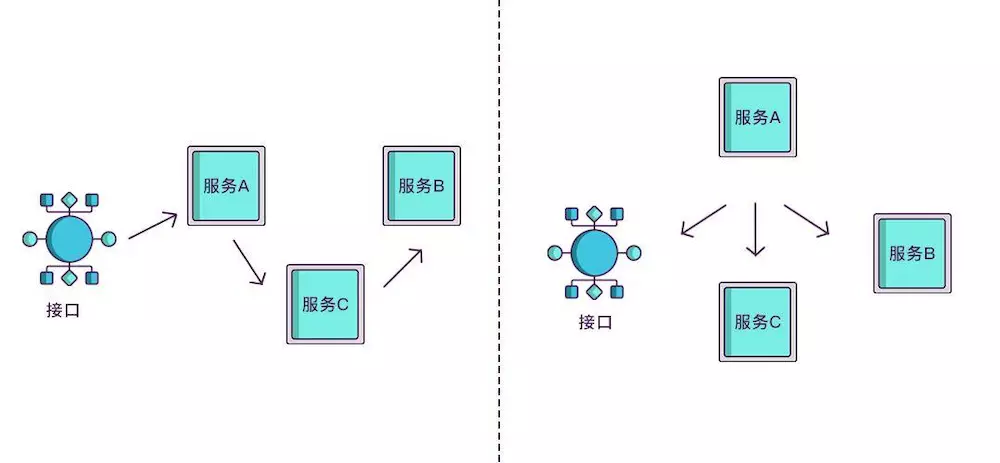
所以应该每次都记录下是谁调用的,我们用parentid作为这个标识的名字。
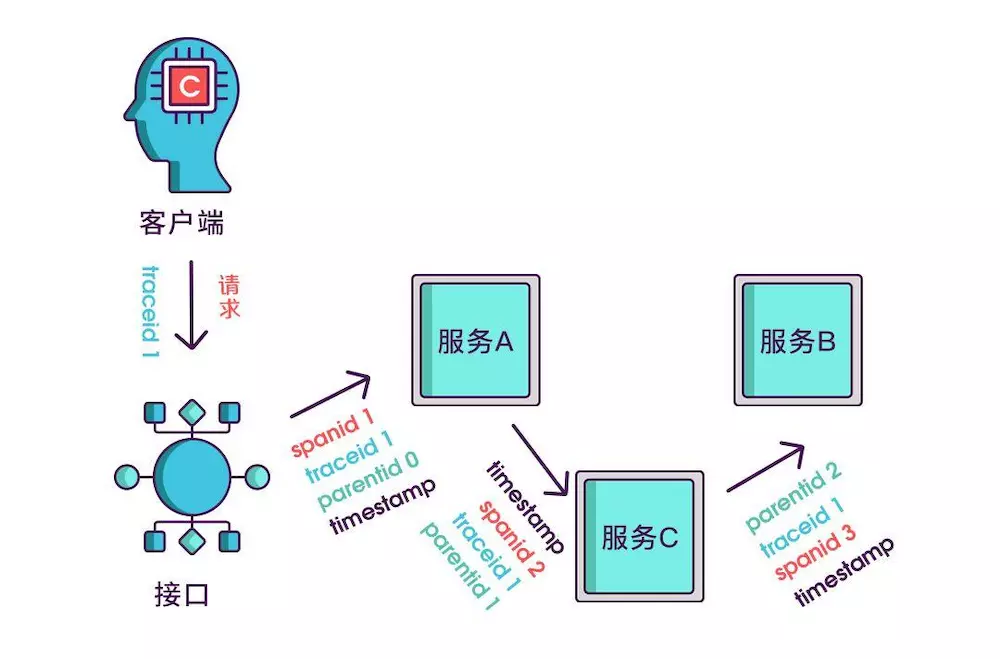
到现在,已经知道调用顺序和层级关系了,但是接口出现问题后,还是不能找到出问题的环节,如果某个服务有问题,那个被调用执行的服务一定耗时很长,要想计算出耗时,上述的三个标识还不够,还需要加上时间戳,时间戳可以更精细一点,精确到微秒级。
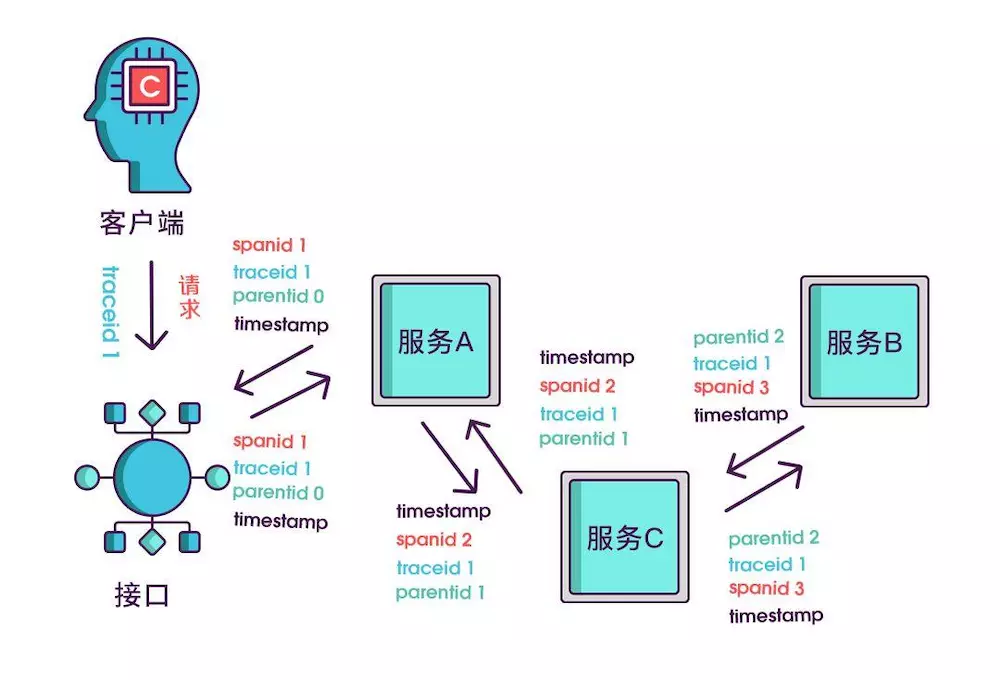
只记录发起调用时的时间戳还算不出耗时,要记录下服务返回时的时间戳,有始有终才能算出时间差,既然返回的也记了,就把上述的三个标识都记一下吧,不然区分不出是谁的时间戳。
虽然能计算出从服务调用到服务返回的总耗时,但是这个时间包含了服务的执行时间和网络延迟,有时候我们需要区分出这两类时间以方便做针对性优化。那如何计算网络延迟呢?我们可以把调用和返回的过程分为以下四个事件。
-
Client Sent简称cs,客户端发起调用请求到服务端。
-
Server Received简称sr,指服务端接收到了客户端的调用请求。
-
Server Sent简称ss,指服务端完成了处理,准备将信息返给客户端。
-
Client Received简称cr,指客户端接收到了服务端的返回信息。
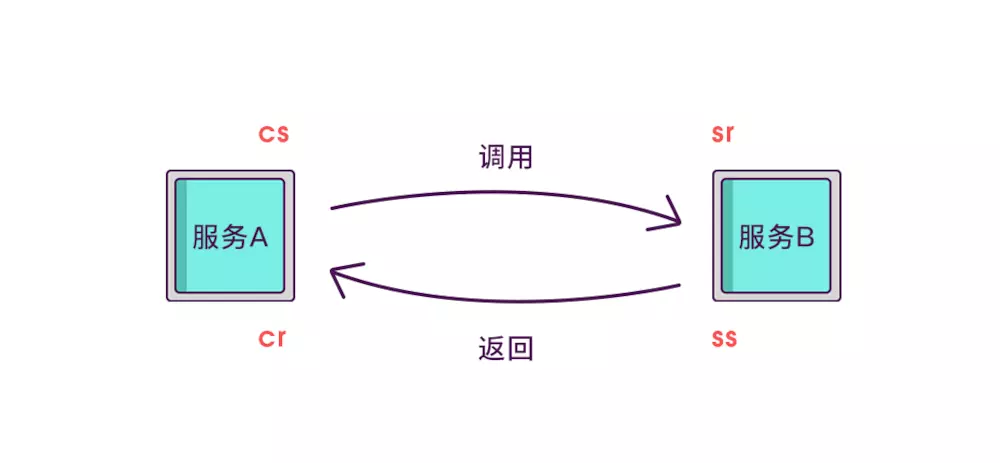
假如在这四个事件发生时记录下时间戳,就可以轻松计算出耗时,比如sr减去cs就是调用时的网络延迟,ss减去sr就是服务执行时间,cr减去ss就是服务响应的延迟,cr减cs就是整个服务调用执行的时间。
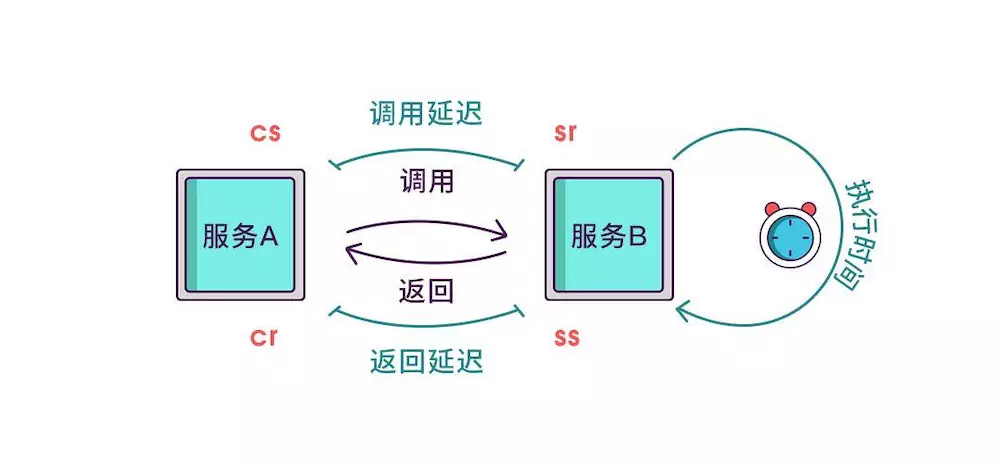
其实span块内除了记录这几个参数之外,还可以记录一些其他信息,比如发起调用服务名称、被调服务名称、返回结果、IP、调用服务的名称等,最后,我们再把相同spanid的信息合成一个大的span块,就完成了一个完整的调用链。感兴趣的同学可以去深入了解一下链路追踪,希望本文对你有所帮助。
作者: 平也
出处:https://www.cnblogs.com/pingyeaa/p/10987438.html
本文链接:https://my.lmcjl.com/post/4943.html
4 评论