目录
前言
最近在学习PaddlePaddle在各个显卡驱动版本的安装和使用,所以同时也学习如何在Ubuntu安装和卸载CUDA和CUDNN,在学习过程中,顺便记录学习过程。在供大家学习的同时,也在加强自己的记忆。本文章以卸载CUDA 8.0 和 CUDNN 7.05 为例,以安装CUDA 10.0 和 CUDNN 7.4.2 为例。
安装显卡驱动
禁用nouveau驱动
|
1 |
|
在文本最后添加:
|
1 2 |
|
然后执行:
|
1 |
|
重启后,执行以下命令,如果没有屏幕输出,说明禁用nouveau成功:
|
1 |
|
下载驱动
官网下载地址:https://www.nvidia.cn/Download/index.aspx?lang=cn,根据自己显卡的情况下载对应版本的显卡驱动,比如笔者的显卡是RTX2070:

下载完成之后会得到一个安装包,不同版本文件名可能不一样:
|
1 |
|
卸载旧驱动
以下操作都需要在命令界面操作,执行以下快捷键进入命令界面,并登录:
|
1 |
|
执行以下命令禁用X-Window服务,否则无法安装显卡驱动:
|
1 |
|
执行以下三条命令卸载原有显卡驱动:
|
1 2 3 |
|
安装新驱动
直接执行驱动文件即可安装新驱动,一直默认即可:
|
1 |
|
执行以下命令启动X-Window服务
|
1 |
|
最后执行重启命令,重启系统即可:
|
1 |
|
注意: 如果系统重启之后出现重复登录的情况,多数情况下都是安装了错误版本的显卡驱动。需要下载对应本身机器安装的显卡版本。
卸载CUDA
为什么一开始我就要卸载CUDA呢,这是因为笔者是换了显卡RTX2070,原本就安装了CUDA 8.0 和 CUDNN 7.0.5不能够正常使用,笔者需要安装CUDA 10.0 和 CUDNN 7.4.2,所以要先卸载原来的CUDA。注意以下的命令都是在root用户下操作的。
卸载CUDA很简单,一条命令就可以了,主要执行的是CUDA自带的卸载脚本,读者要根据自己的cuda版本找到卸载脚本:
|
1 |
|
卸载之后,还有一些残留的文件夹,之前安装的是CUDA 8.0。可以一并删除:
|
1 |
|
这样就算卸载完了CUDA。
安装CUDA
安装的CUDA和CUDNN版本:
- CUDA 10.0
- CUDNN 7.4.2
接下来的安装步骤都是在root用户下操作的。
下载和安装CUDA
我们可以在官网:CUDA10下载页面,
下载符合自己系统版本的CUDA。页面如下:
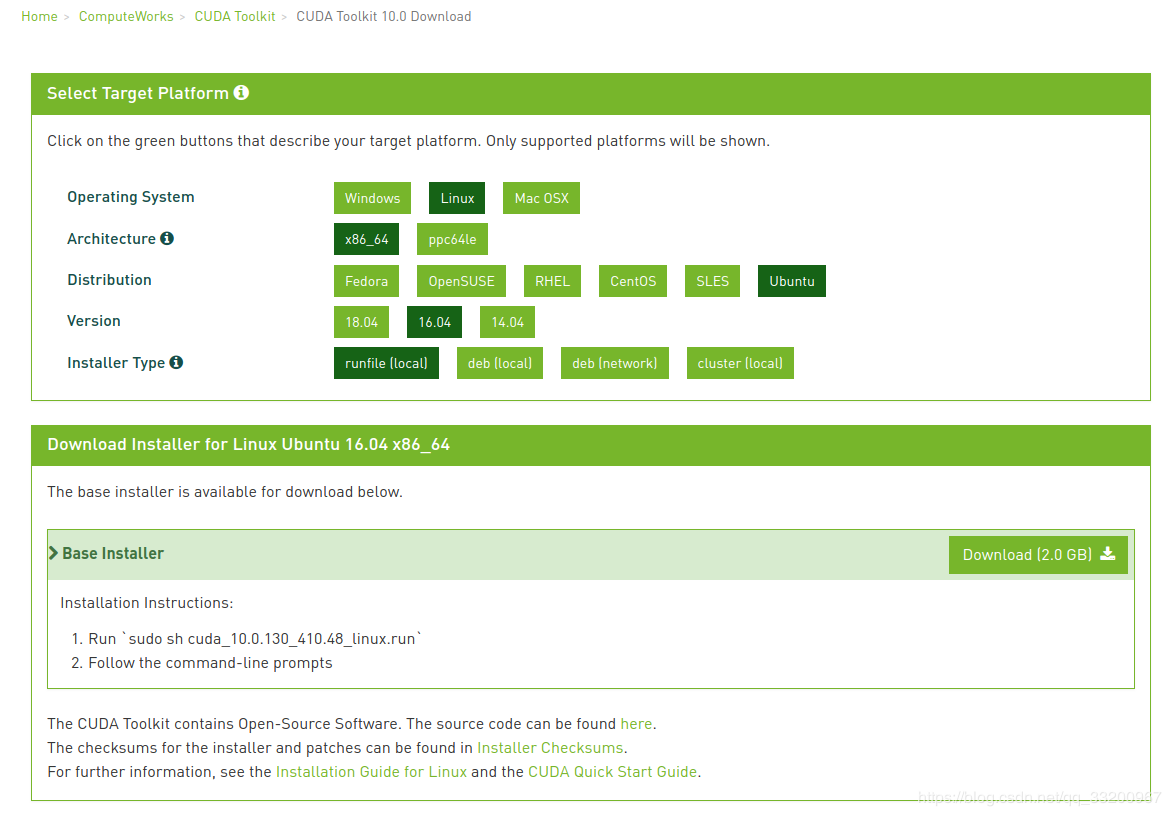
下载完成之后,给文件赋予执行权限:
|
1 |
|
执行安装包,开始安装:
|
1 |
|
开始安装之后,需要阅读说明,可以使用Ctrl + C直接阅读完成,或者使用空格键慢慢阅读。然后进行配置,我这里说明一下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
安装完成之后,可以配置他们的环境变量,在vim ~/.bashrc的最后加上以下配置信息:
|
1 2 3 |
|
最后使用命令source ~/.bashrc使它生效。
可以使用命令nvcc -V查看安装的版本信息:
|
1 2 3 4 5 |
|
测试安装是否成功
执行以下几条命令:
|
1 2 3 |
|
正常情况下输出:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
|
下载和安装CUDNN
进入到CUDNN的下载官网:https://developer.nvidia.com/rdp/cudnn-download,然点击Download开始选择下载版本,当然在下载之前还有登录,选择版本界面如下,我们选择cuDNN Library for Linux:
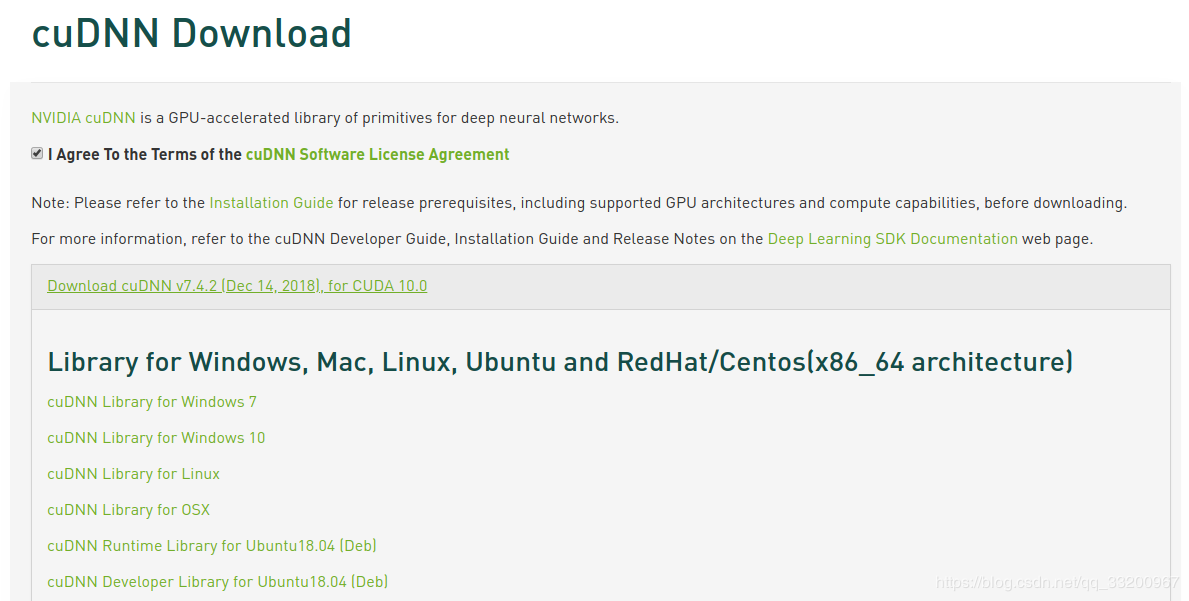
下载之后是一个压缩包,如下:
|
1 |
|
然后对它进行解压,命令如下:
|
1 |
|
解压之后可以得到以下文件:
|
1 2 3 4 5 6 |
|
使用以下两条命令复制这些文件到CUDA目录下:
|
1 2 |
|
拷贝完成之后,可以使用以下命令查看CUDNN的版本信息:
|
1 |
|
测试安装结果
到这里就已经完成了CUDA 10 和 CUDNN 7.4.2 的安装。可以安装对应的Pytorch的GPU版本测试是否可以正常使用了。安装如下:
|
1 2 |
|
然后使用以下的程序测试安装情况:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
|
如果正常输出一下以下信息,证明已经安装成了:
参考资料
https://www.cnblogs.com/luofeel/p/8654964.html
到此这篇关于Ubuntu安装和卸载CUDA和CUDNN的实现的文章就介绍到这了,更多相关Ubuntu安装和卸载CUDA和CUDNN内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文链接:https://blog.csdn.net/qq_33200967/article/details/80689543
本文链接:https://my.lmcjl.com/post/6472.html
4 评论