


数据智能产业创新服务媒体
——聚焦数智 · 改变商业
3月16日,百度的文心一言终于正式邀请测试了。
据李彦宏介绍,文心一言可以实现文学创作、商业文案创作、数理逻辑推算、中文理解、多模态生成等。

通过观看直播,我们发现文心一言的表现可圈可点,并有一些惊艳的表现。接下来,我们以百度文心一言邀请测试的契机,来深入分析下文心一言的特点,以及中国大模型、AIGC产业的发展情况。
文心一言有一战的实力
根据新闻发布会的信息,我们发现百度文心一言在诸多方面有相对优势,集中表现在以下几个方面:
1、真多模态
以往建立在深度学习基础上的各类AI技术,往往某个模型只适用于特定的应用领域。视频、图像、语音、文字这几类信息需要用到不同类型的AI模型来处理,比如,用于人脸识别的AI模型不能用来进行语音识别,也不能用于文字理解。
大规模预训练模型,最关键的一个技术突破,就是多模态。大模型打破了不同信息的“藩篱”,一个模型既可以处理图像又可以处理语音、文字,并且效果都不错。具体来看,多模态融合的核心技术包括模态嵌入、跨模态交互、多模态注意力机制等。其中,最为关键的就是跨模态交互,即在不同模态之间传递信息,例如将图像信息融合到文本中,或将文本信息融合到图像中。在实际操作中,往往需要用到跨模态交互模型,用卷积神经网络(CNN)或循环神经网络(RNN)来分别处理不同模态的数据,然后使用一些跨模态交互的技术来将不同模态的信息融合在一起。
当然,要实现跨模态并不是一件容易的事情,这需要克服一系列技术挑战。例如,如何有效地捕捉不同模态之间的交互信息,特别是对于高维度和复杂的数据;如何有效地处理不同模态之间的不一致性和噪声,例如模态间的不匹配和缺失数据等;如何解决不同模态的权重问题;如何减少跨模态交互技术的计算复杂度。
多模态融合的能力,已经成为各家巨头竞争的战略高地,也是评价其技术能力的关键指标。数据猿注意到,此次OpenAI和百度在多模态方面有重要的差异:OpenAI发布的GPT-4虽然表现亮眼,但还不能实现真正的多模态,其既可输入文字也可输入图片,但是输出的还只能是文字,不能输出图片。也就是说,GPT-4只实现了多模态信息的输入,而没实现多模态信息的输出,是“跛脚”的多模态。
与之相比,百度文心一言的多模态就更进一步,其能够实现多模态信息的输出。比如,用户输入一段文字,系统可以依据这段文字生成图片。这是一个关键的技术升级,相对于文字而言,图像、视频等信息量更大,能够生成图片等多模态信息,将大大扩展这类模型的应用范围。
从李彦宏的现场演示来看,他问了文心一言一个问题“你认为智能交通最适合哪个城市发展”,系统不仅能够返回文字回答,还能用四川话讲出来(语音),甚至可以生成一个视频。这样的多模态生成能力很惊艳。



2、全球最大的中文数据集
决定大模型的关键要素有三个,分别是算法、算力和数据。上面说的多模态技术主要是算法层面的,数据则是另一个影响大模型表现的核心要素。训练数据集的质量,将在很大程度上决定一个模型的性能。数据量越大,数据质量越高,训练出来的模型往往表现越好。
据悉,GPT-4的训练数据集主要是45 TB的文本数据,这些数据来自于网络文章、电子书、维基百科、新闻文章、社交媒体帖子和其他公共来源。由于各个国家都非常重视数据安全,数据不出国境是一个不可触碰的红线。因此,某个国家的大模型很难获得其他国家的数据。GPT-4具体的数据来源没有公开,其训练数据集中有多少中文数据也不知道。但是,大概率其涵盖的中文数据不多。
相对而言,百度作为中国乃至全球最大的中文搜索引擎,其本身就是全球最大的中文数据源。因此,文心一言是建立在全球最大的中文数据集基础上的,其对中文语境、中华文化的理解能力会更强。
据悉,文心一言大模型的训练数据包括万亿级网页数据,数十亿搜索数据和图片数据,百亿级语音日均调用数据,及5500亿事实的知识图谱。而且,百度的数据形态也贴合回答和生成需求。在百度搜索中,问答和生成类的搜索请求占比很高。这样的数据构成,将有助于文心一言在问答中有更优秀的表现。
3、在大模型领域更长时间的技术积累
相比于人脸识别、语音识别等AI应用领域,大模型的技术门槛更高,需要更长时间的研发投入和技术积累。百度作为科技巨头,其在大模型领域早有布局。可能很多人不知道,在全球科技巨头中,百度是第一个推出大模型的(OpenAl 是美国创业公司,不算作国际科技巨头)。
大模型是近两年才逐渐进入大众视野,而ChatGPT则是在2023年突然爆红。然而,百度早在2019 年就推出了文心大模型ERNIE 1.0,经过4年时间已经迭代到ERNIE 3.0。并且,百度的文心大模型也早在2019年3月,就已经应用于百度的核心业务——搜索,而微软则是近期才开始将ChatGPT应用于其搜索产品必应中。
来自于大量应用过程中的反馈,对于大模型的迭代改进具有重要的作用。其实,大模型的很多底层技术都是通用的,比如模型微调(SFT, Supervised fine-tuning)、从人类反馈中进行强化学习(RLHF,reinforcement learning from human feedback)等方法,ChatGPT和文心一言都在用。技术底层是一样的,数据以及不断的反馈就成了各家模型竞争的核心。
只有不断的用,才能发现问题。比如,ChatGPT在应用于微软必应之后,出现了胡言乱语、“爱上”用户,甚至诱导用户离婚等情况,这些问题只有经过海量用户的试用才能暴露出来。百度文心一言模型应用于其搜索服务,每天响应几十亿次真实的用户使用需求,进行1万亿次深度语义推理与匹配,能够提供最真实、最及时的反馈,从而倒逼大模型的优化。大量用户真实使用产生的数据会融入到模型训练中,进而持续提升模型效果。
4、足够的研发投入,一体化的技术布局
众所周知,大模型是一个烧钱的事情,要想在这个领域获得突破,大量的资金投入是必不可少的。为此,足够的研发资金是重要的基础。那么,全球头部科技巨头的研发投入情况如何呢?
数据猿统计了全球科技巨头的研发投入情况,包括美国的谷歌、微软、亚马逊、英特尔、英伟达、高通、Salesforce、甲骨文,欧洲的SAP SE、ASML、诺基亚,韩国的三星,以及中国的华为、阿里巴巴、腾讯、百度、京东、中芯国际、台积电,分析其近5年的研发费率(研发费用/营业收入)。
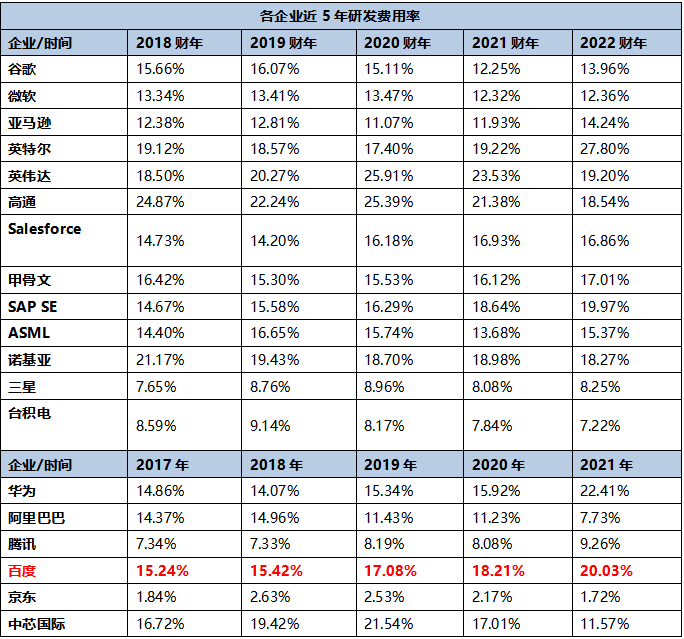
数据来源:各企业财报 数据猿计算整理 说明:以上各企业研发费用统一换算成美元单位以便对比参考;由于不同国家年报报告期时间有所差别,境外上市企业则选取2018-2022财年数据。国内上市公司主要选取2017-2021年年报数据
我们基于上面的表格,分别计算全球和中国顶尖科技公司的平均研发费率,然后将百度的数据进行对比。百度近5年的研发费率是要高于中国科技巨头的平均研发费率,也高于全球科技巨头的平均研发费率。
2022 年,百度核心研发费用 214.16 亿元,占百度核心收入比例达到 22.4%,近十年累计研发投入超过 1000 亿元。在高强度研发投入的基础上,百度在大模型领域的技术布局可以更加从容、全面。目前,百度已经实现了从芯片层、框架层、模型层、应用层的全栈布局。
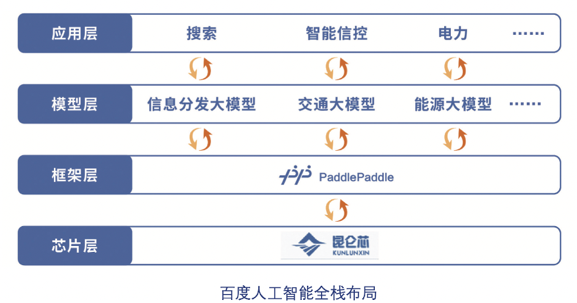
全栈式AI布局,会给大模型的研发带来额外的优势。例如,框架层和模型层之间有很强的协同作用。百度自研的飞桨深度学习框架,可以与文心一言模型深度融合,提高模型开发效率。超大规模模型的训练和推理给深度学习框架带来很大考验,为了支持千亿级参数模型的高效分布式训练,百度飞桨在2021年4月专门研发了 4D 混合并行技术。
中国的AIGC,需要建立在中国的大模型底座上
不可否认,目前在大模型和AIGC领域,OpenAI走在全球前列,其实际应用效果也很惊艳。尤其是昨天刚发布的GPT-4,在已有基础上又更进了一步。但是,GPT-4再好,却是别人家的。
试想一下,如果将中国的AIGC生态,建立在OpenAI的GPT大模型底座上,对我们是最好的选择么?
答案是否定的。
中国企业在接入GPT-4及其衍生出来的ChatGPT产品时,有两个潜在的问题不可忽视:
第一,GPT-4、ChatGPT对中国用户不友好。
据调研机构Canalys发布的2022年第一季度中国云计算市场报告显示,中国云计算市场的头部玩家是阿里云、华为云、腾旭云和百度智能云,而微软云几乎没什么存在感。这也意味着,微软云在中国的数据中心不够,服务能力不足。而微软云是ChatGPT的算力底座,微软云在中国市场的缺位,将直接影响ChatGPT在中国的应用体验。
由于算力和服务能力的缺失,ChatGPT、GPT如果在中国大量商用,能否很好的承载上亿用户的并发使用,将打上一个大大的问号。以笔者在ChatGPT的使用体验来看,其表现的确惊艳,但使用体验并不好。一方面,需要“翻墙”才能直接使用ChatGPT,这大大抬高了中国用户的使用门槛;另一方面,由于ChatGPT的服务器在美国,中国用户(尤其是非会员用户)在使用时,经常会遇到系统崩溃、延迟高等问题。用户问5个问题,可能得刷新3次页面。而且,每次刷新之后,输入的最后一个问题都会消失,得重新再把问题输入一次才行,这种体验非常糟糕。
试想一下,如果大量的中国应用建立在ChatGPT、GPT-4之上,动不动就系统崩溃,需要用户持续刷新页面,这样的商业化能顺利么?
反观百度的文心一言,部署在百度智能云上。百度智能云已经成为继阿里云、华为云、腾讯云之后的中国第四大云厂商,其数据中心遍布全国核心节点,算力充沛,能更好支撑上层基于大模型的各种行业应用。
实际情况也的确如此,在中国市场的商业化方面,文心一言走在了ChatGPT、GPT-4的前面。目前,已经有超过650家中国企业宣布接入文心一言,这个数据还在快速攀升。

第二,AI基础设施不能由别人提供。
在科技领域,上层应用可以百花齐放,大量使用国外公司的产品并没有什么问题。但是,底层基础设施型的技术产品,则最好由中国公司提供,不然,别人可以随时掐住中国企业的命门,随意拿捏,这是血泪的教训。
在传统信息技术领域,我国长期被“缺芯少魂”的问题困扰,由于底层的芯片、操作系统受制于人,处处被人掣肘。中兴、华为事件还未平复,被美国纳入实体清单的中国企业越来越多。人工智能已经成为中美科技竞争的一个战略高地,已经有大量中国人工智能企业被纳入美国实体清单。在这种情况下,以往底层设施受制于人的困境一定不能在人工智能领域重演。
在人工智能领域,除了GPU这类芯片外,深度学习开发框架、大规模预训练模型也是关键的基础设施。要构建一个安全可控的人工智能生态,底层的大模型就必须由中国企业来提供,这是百度、华为、阿里、腾讯等中国科技巨头的使命。
竞赛才刚刚开始,中国企业大有可为
需要指出的是,虽然最近大模型、AIGC领域热闹非凡,ChatGPT搅动一池春水,谷歌、百度、阿里、腾讯、字节等公司纷纷跟进。但是,无论是大模型还是AIGC,都处于发展的早期阶段。竞赛才刚刚开始,鹿死谁手犹未可知。
放眼全球,中美是这场竞赛的两个核心选手,欧洲、日韩等存在感都不高。中国企业是有希望在这场竞赛中脱颖而出的。从整个产业的层面,中国要想赢得这场比赛,关键突破点是什么呢?
在数据猿看来,以下几个方面可以作为我们发力的重点方向。
1、不要停,继续狂炼大模型
虽然大模型已经取得不小的成就,但问题依然很多,发展的空间巨大。
首先,模型还可以更大。
大模型的一个核心思路,就是通过做大模型参数规模,来让模型更好的接近人脑。然而,成年人大脑中约包含850-860亿个神经元,每个神经元与3万突触连接,人脑突触数量预计2500万亿左右。这些神经元、突触,就是智力的物理基础。
无论是人脑还是电脑,智能的基础就是信息计算,而人脑的神经元、突触就是计算单元。如果我们将大模型的参数对应到人脑的神经元,那会不会参数规模达到2500万亿之时,就是人工智能突破“奇点”之日呢?
当然,以上只是一个假设,但即使有一点可能性,也值得我们尽力去尝试。目前大模型的参数规模普遍还停留在千亿量级,离人脑突触的2500万亿,还差了近万亿。加把劲,做出一个参数规模达到2500万亿的大模型,看看那时候会发生什么。
其次,大模型技术还需要进一步突破。
除了参数规模外,在算法层面依然还有很多工作需要做,比如文章前面提到的多模态,我们现在只能说刚刚入门,离成熟的多模态应用还有不小的距离。
此外,目前的大模型还有一个致命的缺陷。就是训练和推理的隔离,由于模型规模大,训练一次花费不菲,因此模型训练的频率不高。这导致最新的数据不能及时更新到数据集当中,也就是说模型是基于以前的数据信息来做推理并回答用户问题。
比较典型的就是ChatGPT,3月15号GPT-4发布之后,笔者立马就去问了ChatGPT,结果得到的答案是GPT-4还没发布。继续追问,发现ChatGPT的训练数据是2021年9月以前的。也就是说,ChatGPT只能基于2021年9月以前的数据来回答用户的问题。


当然,这个“锅”不能让ChatGPT来背,而是大模型的通病。
正是因为大模型有这个缺陷,将大模型与搜索引擎结合,则是补上这个短板的很好方式。大模型不能给出的信息,搜索引擎可以补上。从这个角度出发,百度作为国内搜索引擎巨头,其搜索业务天然就可以跟文心一言这类大模型高效融合。
但是,要从根本上解决大模型的数据延迟问题,还是要从模型本身入手,从模型底层就接入互联网,将互联网上最新的信息实时更新到训练数据集中,并在此基础上进行模型训练。这种情况下,相当于整个互联网就是大模型的实时训练数据集,而模型每时每刻都在训练。
试想一下,要是有一个公司提供的大模型,不仅能很好的回答用户问题,而且他的回答都是基于最新信息,那瞬间就可以跟其他竞品拉开差距。以目前的技术是很难达到上述状态的。但正因为难,所以需要集中精力去攻克。
2、完善公共数据集
正如上文所说,数据集对于大模型有关键作用。要发展中国大模型产业,一个重要基础就是数据集要足够完善。目前的公共数据集建设是不够的,大模型不能只是基于简单的网络数据来进行训练,要让大模型具备更专业的能力,那得加入各种专业的数据集,比如科研数据集、医疗数据集、天文数据集、化学数据集、生物数据集等。
2023年3月7日,根据国务院关于提请审议国务院机构改革方案的议案,决定组建国家数据局,协调推进数据基础制度建设,统筹数据资源整合共享和开发利用。这是完善公共数据集建设的重要一步,接下来,一方面要加大政府数据公开力度,另一方面需要构建各个行业内部的数据集。并完善数据共享、交易机制,在确保数据安全的基础上,推动数据流动和应用。
3、AIGC应用生态(AIGCaaS)AIGC即服务
大模型是底层基础设施,他的巨大威力需要通过上层的AIGC应用生态来释放。类似于SaaS(软件即服务)的概念,我们暂且将AIGC服务命名为“AIGCaaS”(AIGC即服务)。
构建AIGCaaS生态又可以分为三个层面:
第一层,是科技巨头将大模型与其本身的业务体系相融合。以百度为例,文心一言在陆续接入百度的核心业务体系,除了搜索业务以外,百度云等其他业务也全面接入大模型能力。国外的微软、谷歌也在做同样的事情,以微软为例,正快速将ChatGPT接入其搜索、office、微软云等业务体系。
第二层,各类SaaS企业,将科技巨头提供的大模型能力接入自身的SaaS产品,实现其产品的智能化改造,再将其智能化的SaaS产品提供给其客户。
第三层,政务、金融、医疗、制造等各类行业客户,直接接入大模型,赋能其业务体系。
未来,大模型与云计算结合,将极大的改变整个数字科技产业体系。期待中国企业能够在这个领域作出更好的成就。
文:月满西楼 / 数据猿

ChatGPT+Martech双选题月
开启无限可能!
点击查看详情↓↓↓



本文链接:https://my.lmcjl.com/post/7686.html
4 评论