1.给出现实生活中需要排序的一个例子或者现实生活中需要计算凸壳的一个例子。
文心一言:
现实生活中需要排序的一个例子:
在一个商店里,顾客需要购买一些商品。他们需要按照价格从低到高排序,以便更容易地找到他们想要的商品。
现实生活中需要计算凸壳的一个例子:
在一个建筑工地上,工人需要计算一个凸壳的面积。他们需要知道凸壳的高度和宽度,以便计算它的面积。凸壳的面积是指它的底面积加上它的凸出部分的面积。
这些例子都是现实生活中需要排序或计算凸壳的例子。在实际应用中,排序和计算凸壳的问题可能会更加复杂,需要更多的数学知识和计算技能。

chatgpt:
一个现实生活中需要排序的例子是图书馆中书籍的分类和排列。在一个大型的图书馆中,可能有成千上万本书,这些书籍需要按照一定的规则进行分类并排列。例如,可以按照作者、主题、出版时间等方面进行分类,并按照字母顺序或者其他方式进行排列,以便读者能够快速地找到自己感兴趣的书籍。
另一个现实生活中需要计算凸壳的例子是在工业生产中对零部件进行检测和分类。在工业生产中,需要对大量的零部件进行检测,以保证其符合质量标准。为了方便处理,可以将这些零部件表示为平面上的点,并利用计算凸壳的方法对它们进行分类和筛选。凸壳可以帮助我们快速地找到最外层的零部件,并进行进一步的检测和处理。

2.除速度外,在真实环境中还可能使用哪些其他有关效率的量度?
文心一言:
除了速度之外,在真实环境中还可能使用其他有关效率的量度,例如:
(1).持续时间(Time to Complete Task):完成任务所需的时间与总工作时间之比。
(2).工作量(Workload):单位时间内完成的工作量,与总工作量之比。
(3).生产率(Productivity):单位时间内生产的产品数量与总工作量之比。
(4).能源效率(Energy Efficiency):单位能量消耗所产生的产品数量与总工作量之比。
(5).投入产出比(Return on Investment):投入的资源与所产生的收益之比。
这些量度可以帮助我们评估不同方案的效率,从而选择最优的方案。

chatgpt:
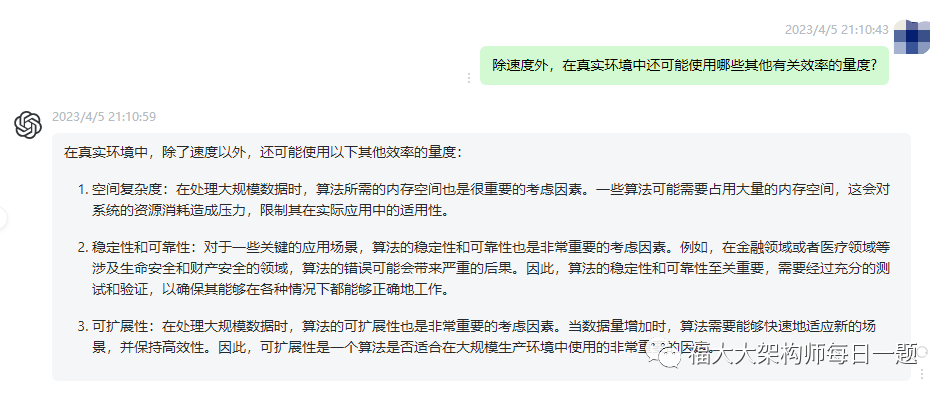
在真实环境中,除了速度以外,还可能使用以下其他效率的量度:
(1).空间复杂度:在处理大规模数据时,算法所需的内存空间也是很重要的考虑因素。一些算法可能需要占用大量的内存空间,这会对系统的资源消耗造成压力,限制其在实际应用中的适用性。
(2).稳定性和可靠性:对于一些关键的应用场景,算法的稳定性和可靠性也是非常重要的考虑因素。例如,在金融领域或者医疗领域等涉及生命安全和财产安全的领域,算法的错误可能会带来严重的后果。因此,算法的稳定性和可靠性至关重要,需要经过充分的测试和验证,以确保其能够在各种情况下都能够正确地工作。
(3).可扩展性:在处理大规模数据时,算法的可扩展性也是非常重要的考虑因素。当数据量增加时,算法需要能够快速地适应新的场景,并保持高效性。因此,可扩展性是一个算法是否适合在大规模生产环境中使用的非常重要的因素。
3.选择一种你以前已知的数据结构,并讨论其优势和局限。
文心一言:
以前我已知的数据结构是数组,它是一种线性数据结构,可以存储相同类型的元素。它的优势是它具有固定的大小,并且可以直接在内存中进行操作。例如,一个数组可以存储整数、浮点数或字符串。它的局限性是,它不能存储大量的数据,因为它只能存储固定大小的元素。

chatgpt:
我选择哈希表(Hash Table)数据结构。
优势:
(1).插入、查找、删除等操作的平均时间复杂度为 O(1)。由于哈希表使用哈希函数将键值映射到桶中,可以快速地进行元素的插入、查找和删除等操作,这使得哈希表成为一种非常高效的数据结构。
(2).哈希表可以存储大量的数据并保证查询时间不会随着数据量的增加而增加。在处理大规模数据时,哈希表比其他数据结构更为高效。
(3).支持高效的动态扩容。当哈希表负载因子超过一定阈值时,可以通过动态扩容来调整桶的数量,并重新分配元素的位置,以保证哈希表的性能。
(4).哈希表的实现较为简单,容易理解和实现。相对于其他的数据结构,哈希表的实现较为简单,只需要实现哈希函数和桶的数据结构即可。
局限:
(1).哈希表在空间利用率方面存在问题。由于哈希表需要预留一定的空间用于存储桶和链表等数据结构,当哈希表中的元素数量较少时,可能会存在大量的空间浪费。
(2).哈希表对哈希函数的质量要求较高。哈希表的效率和正确性与哈希函数的选择密切相关,而选择一个好的哈希函数是一项非常困难的任务,需要考虑多种因素,如哈希冲突的概率、哈希函数的计算复杂度等。
(3).哈希表在处理哈希冲突时可能会存在性能问题。当哈希表中出现哈希冲突时,需要使用链表或其他数据结构来解决冲突。然而,在散列表中,如果出现大量的哈希冲突,链表就会变得非常长,从而导致查询效率降低。为了解决这个问题,需要使用更加高级的散列技术,如开放寻址法和再哈希法等。

4.前面给出的最短路径与旅行商问题有哪些相似之处?又有哪此不同?
文心一言:
最短路径问题和旅行商问题都是经典的动态规划问题。它们的相似之处在于:
目标:最短路径问题的目标是找到一条从源点到目标点的最短路径;旅行商问题的目标是找到一条从起点到目标点的最短路径,中间经过多个节点,且每个节点的路径长度不确定。
算法:最短路径问题使用Dijkstra算法或A算法;旅行商问题使用Dijkstra算法或A算法。
时间复杂度:最短路径问题的时间复杂度为O(V+E),其中V表示节点数,E表示边数;旅行商问题的时间复杂度为O(V2+E2),其中V表示节点数,E表示边数。
不同之处在于:
初始状态:最短路径问题的初始状态为起点到源点的最短路径;旅行商问题的初始状态为起点到源点的最短路径,中间经过多个节点,且每个节点的路径长度不确定。
搜索算法:最短路径问题使用Dijkstra算法或A算法;旅行商问题使用Dijkstra算法或A算法。
搜索方向:最短路径问题的搜索方向是从起点到目标点;旅行商问题的搜索方向是从起点到目标点,中间经过多个节点,且每个节点的路径长度不确定。
优先级:最短路径问题的优先级为速度(V);旅行商问题的优先级为路径长度(E)。
解的稳定性:最短路径问题的解是唯一的;旅行商问题的解是不稳定的,因为每个节点的路径长度不确定。
总之,最短路径问题和旅行商问题虽然有一些相似之处,但它们的目标、算法和时间复杂度都不同。

chatgpt:
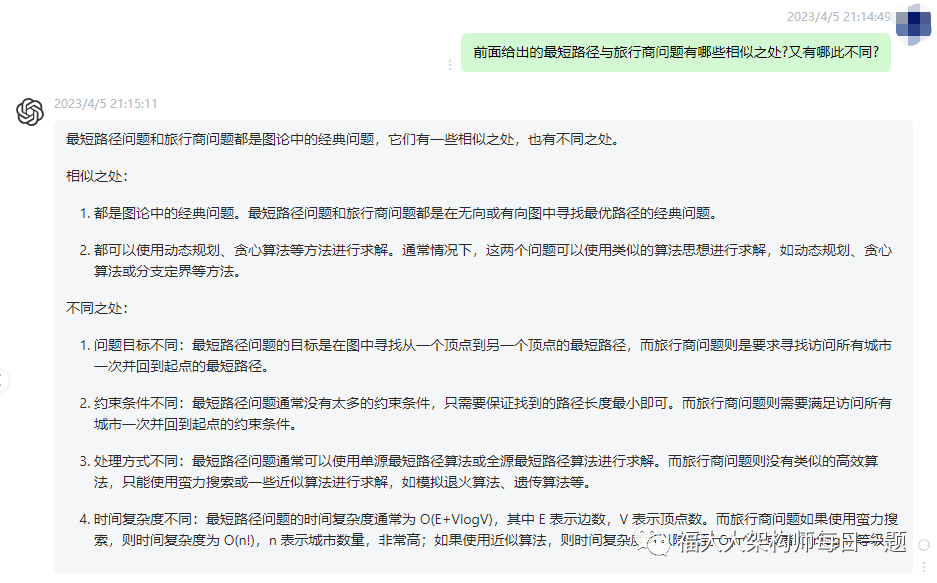
最短路径问题和旅行商问题都是图论中的经典问题,它们有一些相似之处,也有不同之处。
相似之处:
都是图论中的经典问题。最短路径问题和旅行商问题都是在无向或有向图中寻找最优路径的经典问题。
都可以使用动态规划、贪心算法等方法进行求解。通常情况下,这两个问题可以使用类似的算法思想进行求解,如动态规划、贪心算法或分支定界等方法。
不同之处:
问题目标不同:最短路径问题的目标是在图中寻找从一个顶点到另一个顶点的最短路径,而旅行商问题则是要求寻找访问所有城市一次并回到起点的最短路径。
约束条件不同:最短路径问题通常没有太多的约束条件,只需要保证找到的路径长度最小即可。而旅行商问题则需要满足访问所有城市一次并回到起点的约束条件。
处理方式不同:最短路径问题通常可以使用单源最短路径算法或全源最短路径算法进行求解。而旅行商问题则没有类似的高效算法,只能使用蛮力搜索或一些近似算法进行求解,如模拟退火算法、遗传算法等。
时间复杂度不同:最短路径问题的时间复杂度通常为 O(E+VlogV),其中 E 表示边数,V 表示顶点数。而旅行商问题如果使用蛮力搜索,则时间复杂度为 O(n!),n 表示城市数量,非常高;如果使用近似算法,则时间复杂度可以降低到 O(n^2) 或者 O(nlogn) 等级。
5.提供一个现实生活的问题,其中只有最佳解才行。然后提供一个问题,其中近似最佳的一个解也足够好。
文心一言:
现实生活中只有最佳解才行的问题:
问题:在一个长度为n的河流中,有三个岛屿A、B和C,要求将河流分成两个部分,使得从A到C的距离最短,从B到C的距离最长。请问应该如何分割河流?
近似最佳解:可以将河流分成两段,一段从A到B,另一段从B到C,其中A到B的距离最短,B到C的距离最长。
问题:在一个长度为n的图中,有n个节点,每个节点都有一个权值,请问如何选择一些节点,使得它们形成的集合最大?
近似最佳解:可以选择一些节点,使得它们所在的连通分量最大,从而得到一个最大集合。
需要注意的是,上述两个问题的算法实现方式不同,一个是使用Dijkstra算法或A*算法,另一个是使用贪心算法。

chatgpt:
现实生活中的最佳解问题:设计一架高速列车,使得旅客从起点城市到终点城市所需时间最短。在这个问题中,最佳解即为使得旅客到达终点城市所需时间最少的方案。因为任何一个比最佳解更慢的方案都可能导致旅客错过重要的约会、会议或其他事项,对其造成不良的影响。
现实生活中的近似最佳解问题:假设你是一名快递员,需要在城市中派送包裹。你需要规划一条路线,以便在尽可能短的时间内完成所有派送任务。由于城市中有许多道路和交通限制等因素,很难找到确切的最优路线。然而,在实际情况中,近似最佳的路线也足够好,只要可以在尽可能短的时间内完成大部分的派送任务即可,因为时间对于快递员来说非常宝贵,他们希望能够快速地完成任务并回到快递站,以便接下来继续处理其他任务。因此,在这种情况下,使用一些近似算法,如贪心算法或遗传算法等,可以快速地得到一个近似最优的路线,从而提高工作效率。

本文链接:https://my.lmcjl.com/post/8026.html
4 评论