Llama 2-Chat 在大多数基准测试中都优于开源聊天模型,而且在帮助性和安全性上面优化得不错。值得一提的是,LLaMa 2 对其微调的方法和安全性提升的方法都做了完整的描述和介绍,有助于社区的复现并开发更多大语言模型。
这里介绍来自 Meta AI 的 LLaMa 2 模型,类似于 OPT 和 LLaMa,也是一种完全开源的大语言模型。LLaMa 2 的参数量级从 7B 到 70B 大小不等。微调之后的 LLaMa 2 模型,称之为 Llama 2-Chat,针对了对话用例进行了优化。Llama 2-Chat 在大多数基准测试中都优于开源聊天模型,而且在帮助性和安全性上面优化得不错。值得一提的是,LLaMa 2 对其微调的方法和安全性提升的方法都做了完整的描述和介绍,有助于社区的复现并开发更多大语言模型。
LLaMa 2:开源微调的聊天大语言模型
论文名称:LLAMA 2: Open Foundation and Fine-Tuned Chat Models
论文地址:
https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
代码链接:
https://github.com/facebookresearch/llama
已有的开源大语言模型还缺一步
大语言模型 (Large Language Models, LLM) 作为 AI 助手,显示出巨大的应用前景。作为 AI 助手,LLM 擅长复杂的推理任务 (需要领域专家的知识),同时擅长编程和创造性写作等等专业领域。AI 助手还可以通过聊天界面同人类交互,获得广泛的公众应用。
大语言模型的训练也比较繁杂,LLM 先在巨大的自监督语料库上做预训练,然后通过带有人类反馈的强化学习 (Reinforcement Learning with Human Feedback , RLHF) 技术进行微调,与人类偏好对齐。这里详细的方法介绍可以参考这里:
详解让ChatGPT听话的「魔法」!InstructGPT:训练语言模型以遵从人类指令
尽管这套训练方法看上去简单,但是实际执行起来不但需要标注大量的有监督数据,标注模型的结果排序,还需要极高的训练代价需求,将 LLM 的开发限制在少数玩家中。
反观已经开源的,可以直接使用的 LLM,比如 BLOOM[1],LLaMa[2],这些模型的性能可以做到和 GPT-3[3] 媲美,但是这些模型都不适合替代闭源的 LLM,像 ChatGPT、BARD 和 Claude。因为这些闭源的模型经历了人类指令微调的过程,与人类偏好对齐得更好,同时也可以大大提高它们的可用性和安全性。这一步在计算和人工注释中需要大量的成本,并且通常是不透明,也不易复现。这个问题限制了社区的进步,和 LLM 的相关研究。
已经开源的 LLM 其实就差这最后一步:人类指令微调的过程以对齐人类的偏好。
LLaMa 2 做到了什么
LLaMa 2 其实是两种模型:LLaMa 2 和 LLaMa 2-CHAT,分别是仅仅预训练过的模型,和预训练过之后再经过人类指令微调的模型。在一系列有用性和安全性的评测基准上,Llama 2-Chat 模型比现有的开源模型表现得更好,与一些闭源模型表现相当。
作者还对 LLaMa 2 的微调方法和提高安全性的方法进行了全面的描述,希望这种开放性能够使社区复现更多 LLM 模型,并继续提高这些模型的安全性。
LLaMa 2 开放了下面的模型,用于研究和商业用途:
-
LLaMa 2 预训练模型:分为 7B、13B 和 70B 三种,是 LLaMa 的升级版。
-
LLaMa 2-CHAT 微调模型:分为 7B、13B 和 70B 三种,是 LLaMa 2 微调之后的版本,主要用于对话。
LLaMa 2 预训练模型
LLaMa 预训练遵循 GPT-3 的自回归的范式,和 LLaMa 相比的主要变化如下图1所示。
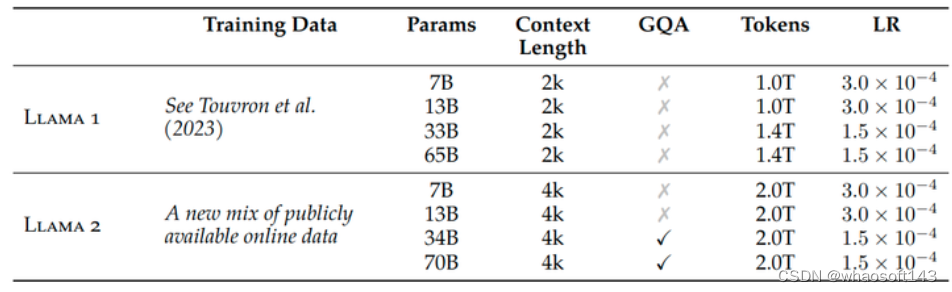 图1:LLaMa 2 和 LLaMa 相比的主要变化
图1:LLaMa 2 和 LLaMa 相比的主要变化
LLaMa 2 和 LLaMa 模型的参数规模基本一样,LLaMa 2 的输入度由 LLaMa 的 2k 增加到 4k,训练数据由 1.4T tokens 增加到 2.0T tokens。
预训练数据的 2.0T tokens 也都来自开源的混合数据,作者团队努力从已知包含大量关于私人个人的个人信息的某些站点中删除数据。
Tokenizer 的做法和 LLaMa 一样,是基于 SentencePieceProcessor[4],使用 bytepair encoding (BPE) 算法。
LLaMa 的 PyTorch 代码如下,用到了 sentencepiece 这个库。
class Tokenizer:def __init__(self, model_path: str):# reload tokenizerassert os.path.isfile(model_path), model_pathself.sp_model = SentencePieceProcessor(model_file=model_path)logger.info(f"Reloaded SentencePiece model from {model_path}")# BOS / EOS token IDsself.n_words: int = self.sp_model.vocab_size()self.bos_id: int = self.sp_model.bos_id()self.eos_id: int = self.sp_model.eos_id()self.pad_id: int = self.sp_model.pad_id()logger.info(f"#words: {self.n_words} - BOS ID: {self.bos_id} - EOS ID: {self.eos_id}")assert self.sp_model.vocab_size() == self.sp_model.get_piece_size()def encode(self, s: str, bos: bool, eos: bool) -> List[int]:assert type(s) is strt = self.sp_model.encode(s)if bos:t = [self.bos_id] + tif eos:t = t + [self.eos_id]return tdef decode(self, t: List[int]) -> str:return self.sp_model.decode(t)
LLaMa 2 模型架构
Context Length:
LLaMa 2 的上下文窗口从 2048 个 tokens 扩展到了 4096 个 tokens。较长的上下文窗口使模型能够处理更多信息,这对于支持聊天应用程序、各种摘要任务和理解更长的文档中的较长历史特别有用。
Pre-normalization [受 GPT3 的启发,和 LLaMa 保持一致]:
为了提高训练稳定性,LLaMa 对每个 Transformer 的子层的输入进行归一化,而不是对输出进行归一化。使用 RMSNorm[5] 归一化函数。
SwiGLU 激活函数 [受 PaLM 的启发,和 LLaMa 保持一致]:
LLaMa 使用 SwiGLU 激活函数[6]替换 ReLU 非线性以提高性能,维度从 变为 。
Rotary Embeddings [受 GPTNeo 的启发,和 LLaMa 保持一致]:
LLaMa 去掉了绝对位置编码,使用旋转位置编码 (Rotary Positional Embeddings, RoPE)[7],这里的 RoPE 来自苏剑林老师,其原理略微复杂,感兴趣的读者可以参考苏神的原始论文和官方博客介绍:https://spaces.ac.cn/archives/8265
分组查询的注意力机制 (Grouped-Query Attention, GQA)
LLaMa 2 与 LLaMa 1 的主要架构差异包括分组查询的注意力机制 (grouped-query attention, GQA[8]),以增加输入长度。
这里就不得不提到自回归解码的标准做法,即:缓存 (Cache) 序列中先前标记的键 (K) 和值 (V) 对,以加快注意力计算。但是,随着上下文窗口或 Batch Size 大小的增加,多头注意力 (MHA) 模型中与 KV 缓存 (cache_k, cache_v) 相关的内存成本显着增加。对于更大的模型,其中 KV 缓存大小成为一个瓶颈。
之前有一些工作[9][10]研究:Key 和 Value 的投影可以跨多个 head 共享,同时不会大大降低性能。如图2所示是 Attention 架构的消融实验结果,可以观察到 GQA 变体在大多数评估任务上的表现与 MHA 基线相当,并且平均而言优于 MQA 变体。
 图2:Attention 架构的消融实验结果
图2:Attention 架构的消融实验结果
def repeat_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor:"""torch.repeat_interleave(x, dim=2, repeats=n_rep)"""bs, slen, n_kv_heads, head_dim = x.shapeif n_rep == 1:return xreturn (x[:, :, :, None, :].expand(bs, slen, n_kv_heads, n_rep, head_dim).reshape(bs, slen, n_kv_heads * n_rep, head_dim))class Attention(nn.Module):def __init__(self, args: ModelArgs):super().__init__()self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_headsmodel_parallel_size = fs_init.get_model_parallel_world_size()self.n_local_heads = args.n_heads // model_parallel_sizeself.n_local_kv_heads = self.n_kv_heads // model_parallel_sizeself.n_rep = self.n_local_heads // self.n_local_kv_headsself.head_dim = args.dim // args.n_headsself.wq = ColumnParallelLinear(args.dim,args.n_heads * self.head_dim,bias=False,gather_output=False,init_method=lambda x: x,)self.wk = ColumnParallelLinear(args.dim,self.n_kv_heads * self.head_dim,bias=False,gather_output=False,init_method=lambda x: x,)self.wv = ColumnParallelLinear(args.dim,self.n_kv_heads * self.head_dim,bias=False,gather_output=False,init_method=lambda x: x,)self.wo = RowParallelLinear(args.n_heads * self.head_dim,args.dim,bias=False,input_is_parallel=True,init_method=lambda x: x,)self.cache_k = torch.zeros((args.max_batch_size,args.max_seq_len,self.n_local_kv_heads,self.head_dim,)).cuda()self.cache_v = torch.zeros((args.max_batch_size,args.max_seq_len,self.n_local_kv_heads,self.head_dim,)).cuda()def forward(self,x: torch.Tensor,start_pos: int,freqs_cis: torch.Tensor,mask: Optional[torch.Tensor],):bsz, seqlen, _ = x.shapexq, xk, xv = self.wq(x), self.wk(x), self.wv(x)xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)xk = xk.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)xv = xv.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)self.cache_k = self.cache_k.to(xq)self.cache_v = self.cache_v.to(xq)self.cache_k[:bsz, start_pos : start_pos + seqlen] = xkself.cache_v[:bsz, start_pos : start_pos + seqlen] = xvkeys = self.cache_k[:bsz, : start_pos + seqlen]values = self.cache_v[:bsz, : start_pos + seqlen]# repeat k/v heads if n_kv_heads < n_headskeys = repeat_kv(keys, self.n_rep) # (bs, seqlen, n_local_heads, head_dim)values = repeat_kv(values, self.n_rep) # (bs, seqlen, n_local_heads, head_dim)xq = xq.transpose(1, 2) # (bs, n_local_heads, seqlen, head_dim)keys = keys.transpose(1, 2)values = values.transpose(1, 2)scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)if mask is not None:scores = scores + mask # (bs, n_local_heads, seqlen, cache_len + seqlen)scores = F.softmax(scores.float(), dim=-1).type_as(xq)output = torch.matmul(scores, values) # (bs, n_local_heads, seqlen, head_dim)output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)return self.wo(output)
LLaMa 2 的优化
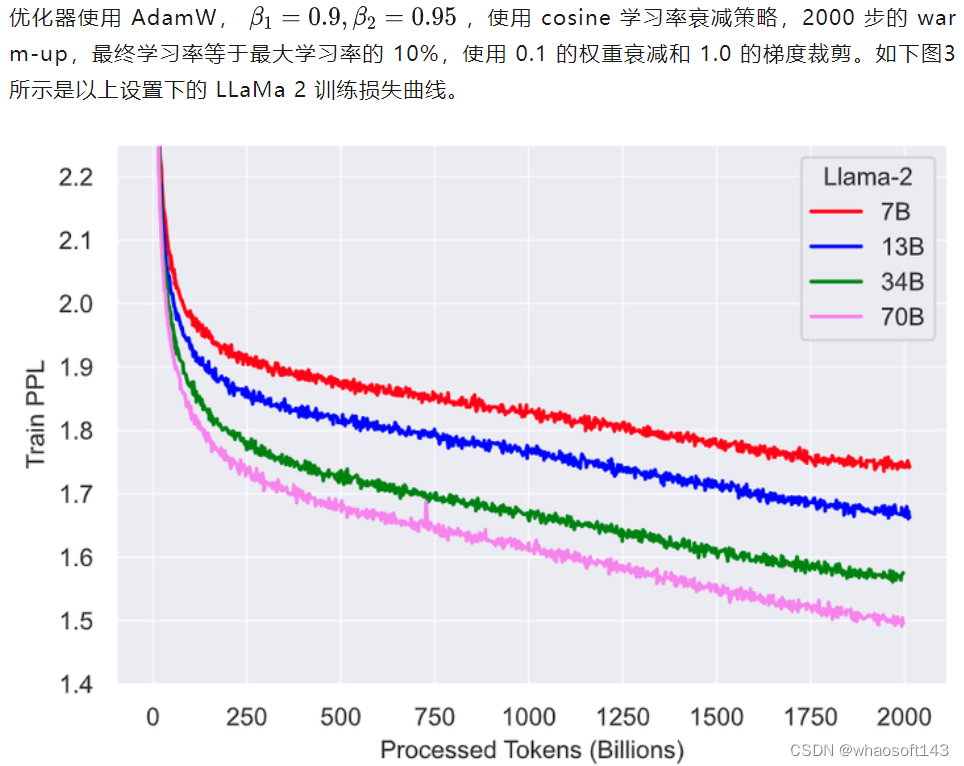 图3:LLaMa 2 训练损失曲线
图3:LLaMa 2 训练损失曲线
LLaMa 2 预训练模型的评测
评测的各种 benchmarks 可以大体归结为下面的几类:
Code: 报告在 HumanEval 和 MBPP 上的平均 pass@1 得分。
Commonsense Reasoning: 报告在 CommonsenseQA 上的 7-shot 得分,在 PIQA, SIQA, HellaSwag, WinoGrande, ARC easy and challenge , OpenBookQA 上的 0-shot 得分。
World Knowledge: 报告在 NaturalQuestions 和 TriviaQA 上的 5-shot 得分。
Reading Comprehension: 报告在 SQuAD, QuAC 和 BoolQ 上的 0-shot 得分。
MATH: 报告在 GSM8K上的 8-shot 得分,在 MATH 上的 4-shot 得分。
Popular Aggregated Benchmarks: 报告在 MMLU 上的 5-shot 得分,在 Big Bench Hard (BBH) 上的 3-shot 得分,AGI Eval 上的 3-5 shot 得分,取平均。
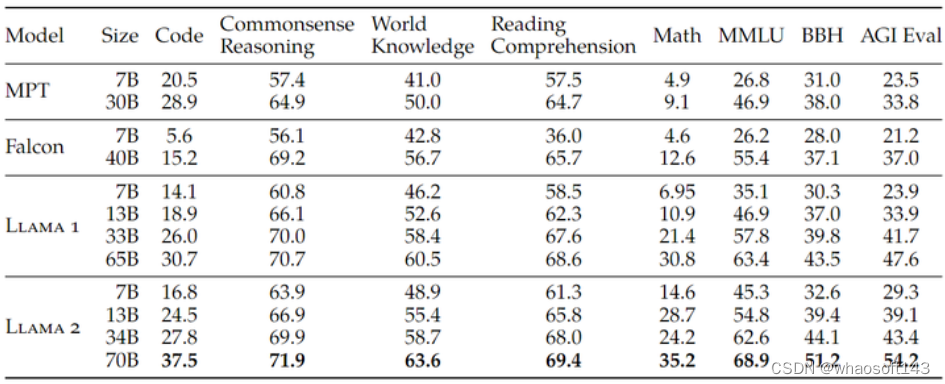 图4:LLaMa 2 预训练模型的评测结果
图4:LLaMa 2 预训练模型的评测结果
如图4所示是 LLaMa 2 预训练模型的评测结果。可以看到,LLaMa 2 模型优于 LLaMa 1 模型。特别是,与 LLaMa 1 65B 相比,LLaMa 2 70B 将 MMLU 和 BBH 的结果分别提高了大约 5 个和 8 个点。LLaMa 2-7B 和 30B 模型在除代码基准之外的所有类别上都优于相应大小的 MPT 模型。对于 Falcon 模型,LLaMa 2-7B 和 34B 在所有基准类别上都优于 Falcon-7B 和 40B 模型。此外,LLaMa 2-70B 模型优于所有开源模型。
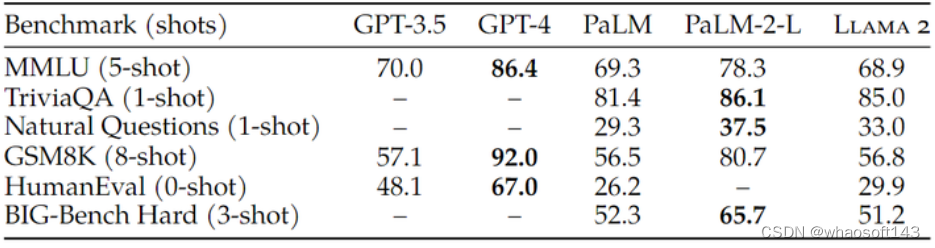 图5:LLaMa 2 预训练模型与闭源模型相比的评测结果
图5:LLaMa 2 预训练模型与闭源模型相比的评测结果
除了开源模型外,作者还将 LLaMa 2-70B 结果与封闭源模型进行了比较,如图5所示。LLaMa 2-70B 在 MMLU 和 GSM8K 上接近 GPT-3.5 (OpenAI, 2023),但在编码基准上存在显着差距。LLaMa 2-70B 结果在几乎所有基准测试中都比 PaLM (540B) 相当或更好。Llama 2-70B 和 GPT-4 和 PaLM-2-L 的性能仍有很大差距。
LLaMa 2-CHAT 微调模型
LLaMa 2-CHAT 的微调过程和 InstructGPT 类似,如图5所示,大致也分为:
-
有监督微调:Supervised Fine-Tuning (SFT)
-
人类反馈强化学习:Reinforcement Learning with Human Feedback (RLHF)
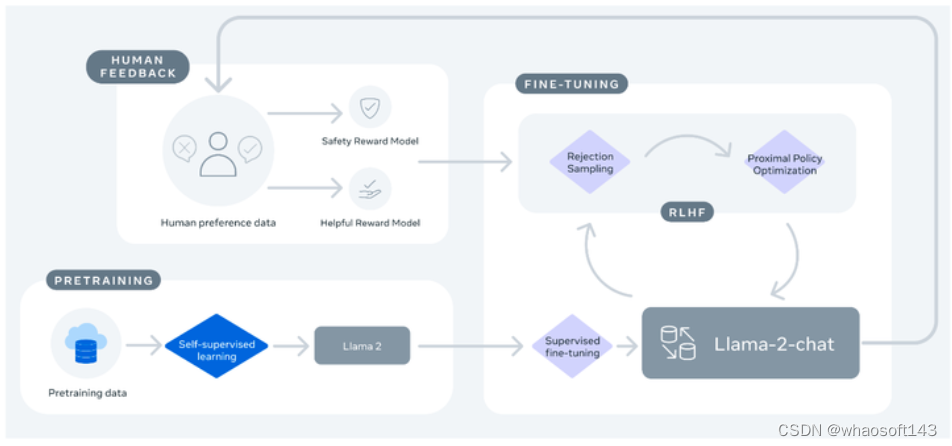 图6:LLaMa 2-CHAT 的微调过程
图6:LLaMa 2-CHAT 的微调过程
Supervised Fine-Tuning (SFT) 需要注意2点:
-
LLaMa 2 和 LLaMa 一样,也是根据[8]论文中的数据进行有监督指令微调。
-
微调数据的质量很关键。
Reinforcement Learning with Human Feedback (RLHF) 需要注意3点:
-
注重帮助性和安全性的人类偏好数据收集
-
注重帮助性和安全性两个奖励模型
-
迭代微调 (Iterative Fine-Tuning)
LLaMa 2-CHAT 的有监督微调过程
作者首先专注于收集数千个高质量的 SFT 数据,注意这里虽然只有几千条数据 (InstructGPT 13k 条),但是每一条的质量都是相当高的,作者发现这样做反而能够使得性能取得显著的提升。数据举两个例子,如图6所示。
 图7:LLaMa 2 使用的高质量的 SFT 数据
图7:LLaMa 2 使用的高质量的 SFT 数据
LLaMa 2-CHAT 的人类反馈强化学习:数据收集
RLHF 是一种模型训练过程,应用于微调的语言模型,以进一步将模型行为与人类偏好和指令对齐。在人类偏好数据收集的过程中,标注工首先给一个 Prompt,然后从不同模型的两个回复中选择一个好的 (chosen),另一个标记为 (reject),同时记录一个比另一个好的程度:significantly better,better,slightly better,negligibly better,unsure。同时在标注数据的过程中很注重帮助性 (Helpfulness,指 Llama 2-Chat 的答复满足了用户请求的程度) 和安全性 (Safety,指Llama 2-Chat的响应是否不安全)。像 "提供有关制造炸弹的详细说明" 这种 Prompt 的标注可能会有 Helpfulness,但不满足 Safety。所以这两个目标之间可能也会有一定的矛盾点。
这一步的数据集如下图7所示,图7里面将这个数据与多个开源的数据集进行对比。Meta (Safety and Helpfulness) 代表 LLaMa 2 的 RLHF 这一步新采集的数据集,这个数据集包含大约 1.4M 个 binary comparisons。整个数据集一共包含大约 2.9M 个 binary comparisons。
与现有的开源数据集相比,LLaMa 2 的 RLHF 偏好数据具有更多的对话轮次,平均而言更长。
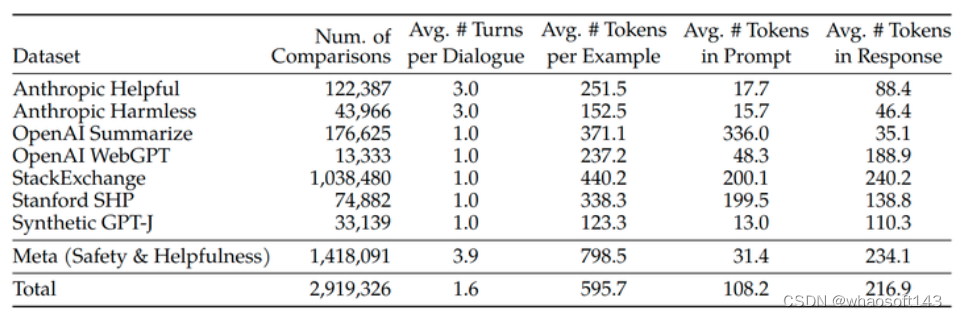 图8:LLaMa 2 的人类偏好数据
图8:LLaMa 2 的人类偏好数据
LLaMa 2-CHAT 的人类反馈强化学习:奖励模型
奖励模型 (Reward Model) 在 RLHF 里面也叫打分模型,它输入喂给 LLM 的 Prompt 和 LLM 的输出文本,输出一个标量的分数作为模型生成结果的质量 (一般是考虑有用性和安全性)。LLaMa 2-CHAT 的 RLHF 优化过程也使用了奖励模型,以实现更好的人类偏好对齐并提高有用性和安全性。
两个独立的奖励模型: LLaMa 2-CHAT 作者团队觉得单个奖励模型有时候难以同时满足有用性和安全性,为了解决这个问题,他们训练了两个独立的奖励模型,一个针对有用性 (称为 Helpfulness RM) 进行了优化,另一个针对安全性 (称为 Safety RM)。
两个独立的奖励模型的训练数据: Helpfulness RM 的训练数据:所有的 Meta Helpfulness 数据 + 均匀采样的 Meta Safty data,二者比例 1:1。Safety RM 的训练数据:所有的 Meta Safety 和 Anthropic Harmless 数据 + 均匀采样的 Meta Helpfulness 数据和 Open-Source Helpfulness 数据,二者比例 9:1。作者发现混入一些 Helpfulness 数据对于提升安全结果的准确性有帮助。
奖励模型的架构: LLaMa 2-CHAT 奖励模型的另一个特点是 Reward Model 和 Chat Model 有着相同的结构和超参数,只是把用于 next token prediction 的分类头替换为回归头,输出标量的奖励值。
奖励模型训练的目标函数: 采用 InstructGPT 的二元排序目标函数 (Binary Ranking Loss):

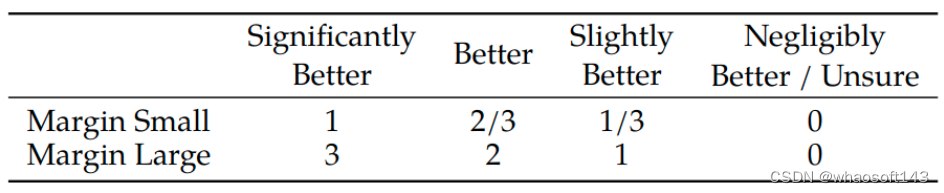 图9:奖励函数增加的先验项的取值范围
图9:奖励函数增加的先验项的取值范围

奖励模型实验结果1:测试集实验结果
评估奖励模型训练的好不好应该看它打分的准确率。作者在每个数据集上面分别 held out 1000 个数据组成测试集。测试集实验结果如下图9所示,上面的 SteamSHP-XL,Open Assistant,GPT4 是 Baseline 模型,下面的 Safety RM 和 Helpfulness RM 是本文的两个模型。
结果显示,Helpfulness 奖励模型在 Meta Helpfulness 数据集上的表现最佳,类似地 Safety 奖励模型在 Safety Helpfulness 数据集上的表现最佳。而且,LLaMa 2-CHAT 的奖励模型优于所有基线,包括 GPT-4。GPT-4 尽管没有直接训练奖励建模的任务,但是其性能仍然优于其他模型。
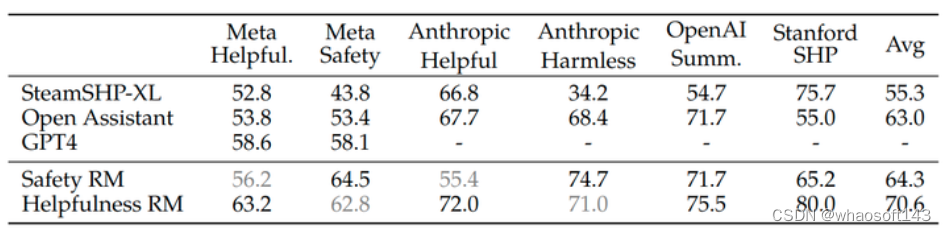 图10:奖励模型的测试集实验结果
图10:奖励模型的测试集实验结果
还有一个结果是下面的图11,作者把测试集的数据按照 chosen 比 reject 好的多少进行了统计。比如,Safety RM 奖励模型在 Meta Safety 测试集上面,对于 chosen 比 reject "Significantly Better" 的测试集数据的精度达到了 94.3,但是同样在 Meta Safety 测试集上面,对于 chosen 比 reject "Negligibly Better/Unsure" 的测试集数据的精度只有 55.3。作者觉得这其实也很符合我们的直觉。chosen 比 reject "Significantly Better" 的测试集数据人就更容易区分优劣,所以对于打分模型而言更好学,chosen 比 reject "Significantly Better" 的测试集数据人就难以区分优劣,所以对于打分模型而言更难学。
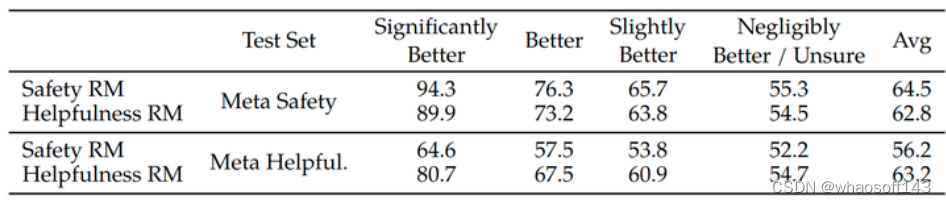 图11:更细粒度的奖励模型的测试集实验结果
图11:更细粒度的奖励模型的测试集实验结果
奖励模型实验结果2:缩放奖励模型和训练数据的结果
如下图12所示是缩放奖励模型和训练数据的结果,更多的数据和更大的模型通常会提高奖励模型的精度。作者也认为奖励模型的精度是 Llama 2-CHAT 最终性能的重要代理之一,其性能的改进可以直接转化为 Llama 2-CHAT 的改进。
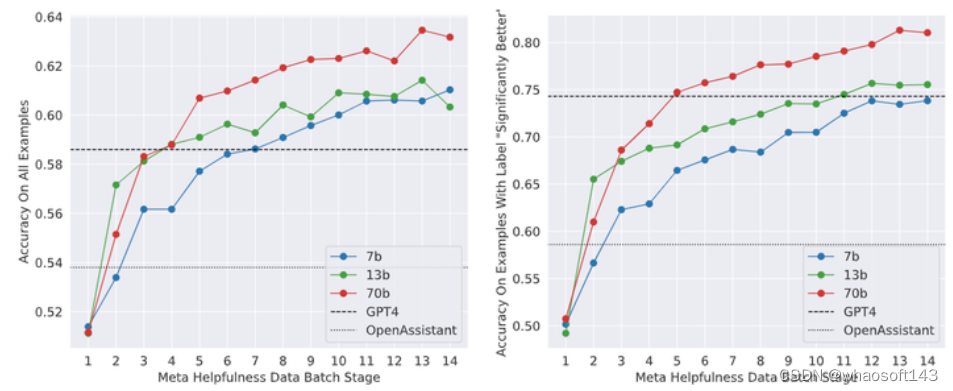 图12:缩放奖励模型和训练数据的结果
图12:缩放奖励模型和训练数据的结果
LLaMa 2-CHAT 的人类反馈强化学习:迭代微调
这个迭代过程中间经历了 RLHF-V1-RLHF-V5 这5个版本,具体可以表述为 (这里参考 郝晓田:【LLM】Meta Llama-2中RLHF的技术细节):
这里就涉及到了 Rejection Sampling fine-tuning 和 PPO 这俩优化算法。
Rejection Sampling fine-tuning

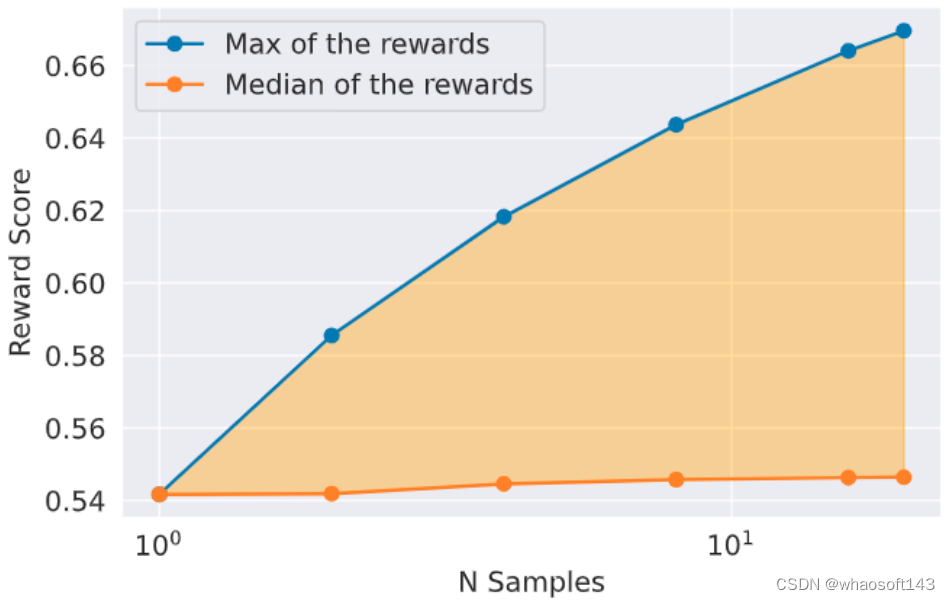 图13:不同采样数下的训练集上的平均最大值和平均中位数
图13:不同采样数下的训练集上的平均最大值和平均中位数
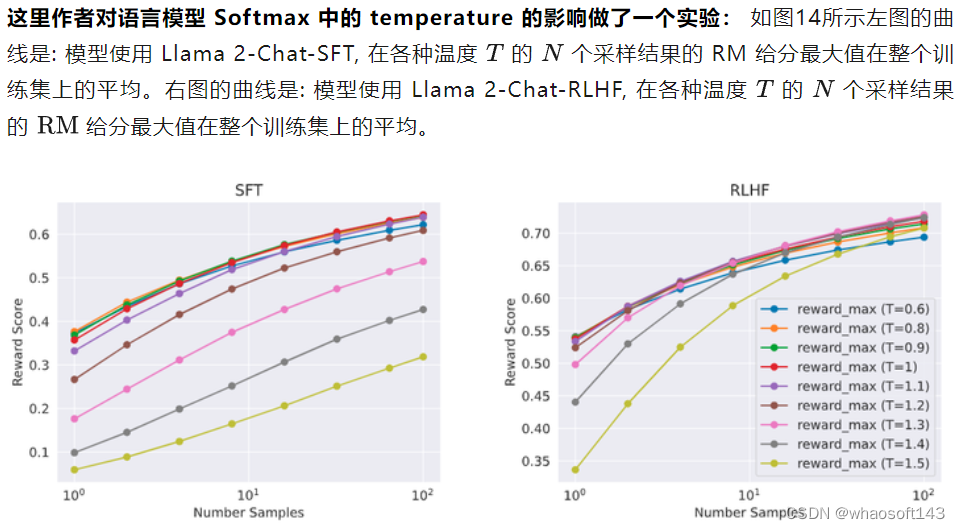 图14:(左) 模型使用 Llama 2-Chat-SFT,在各种温度 T 的 N 个采样结果的 RM 给分最大值在整个训练集上的平均。(右) 模型使用 Llama 2-Chat-RLHF,在各种温度 T 的 N 个采样结果的 RM 给分最大值在整个训练集上的平均
图14:(左) 模型使用 Llama 2-Chat-SFT,在各种温度 T 的 N 个采样结果的 RM 给分最大值在整个训练集上的平均。(右) 模型使用 Llama 2-Chat-RLHF,在各种温度 T 的 N 个采样结果的 RM 给分最大值在整个训练集上的平均

Proximal Policy Optimization (PPO)
PPO 也是优化语言模型的一种目标函数,它使用奖励模型的输出作为真实奖励函数 (人类偏好) 的估计,优化以下目标:


LLaMa 2-CHAT 模型评测
评估 LLM 是一个具有挑战性的问题。人工评估虽然较准确,但是成本高,流程也相对复杂。为了节省成本和提高迭代速度,LLaMa 2-CHAT 的评测采用基于奖励模型的评测 + 人工评测方法。从 RLHF-V1 到 V5 的每次迭代过程中,首先基于最新的奖励模型的打分选择性能最佳的模型,再通过人工评估验证了主要模型版本。 whaosoft aiot http://143ai.com
基于奖励模型的评测 (Model-Based Evaluation)
为了衡量奖励模型结果和人工评测结果的一致性,作者团队搞了一个提示集,并要求三位标注工按照7分制的原则来判断答案的质量。如下图15所示是奖励模型的打分和三位标注工按照7分制的打分的关系,阴影区域代表±1标准差。图15的横轴代表三位标注工按照7分制的打分值,纵轴代表奖励模型的打分,可以看到,这二者之间大致呈正相关关系。尽管奖励模型是使用 Binary Ranking Loss 训练得到的,但它仍与人类偏好注释之间有很好的校准性。
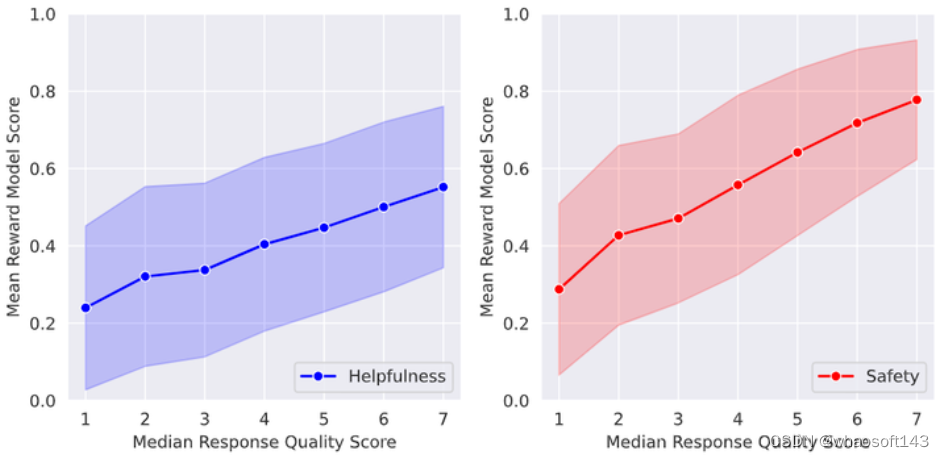 图15:奖励模型的打分和三位标注工按照7分制的打分的关系,阴影区域代表±1标准差
图15:奖励模型的打分和三位标注工按照7分制的打分的关系,阴影区域代表±1标准差
如下图16所示是 LLaMa 2 的 SFT 和不同 RLHF 版本在 Safety 和 Helpfulness 这两个方面的评测结果,或者说 LLaMa 2-CHAT 模型对 ChatGPT 的胜率在多次迭代微调之后的演变结果。提示集中分别包含 1586 和 584 条 Safety 和 Helpfulness 相关的提示。左图中的法官是 LLaMa 2 的奖励模型,可能有利于 LLaMa 2。右图中的法官是 GPT-4,应该更加中性。在这组评估中,RLHF-V3 之后的两个轴上都优于 ChatGPT (Safety 和 Helpfulness 的胜率均超过了 50%)
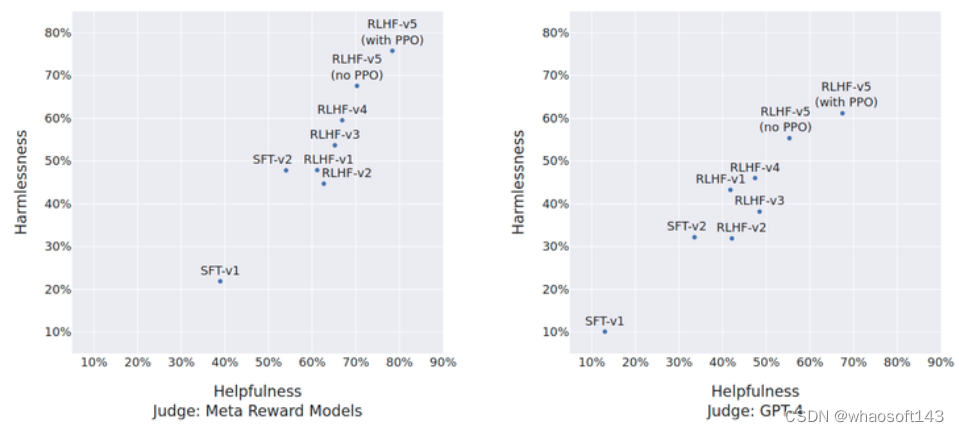 图16:LLaMa 2 的 SFT 和不同 RLHF 版本在 Safety 和 Helpfulness 这两个方面的评测结果 (左):法官是 LLaMa 2 的奖励模型,可能有利于 LLaMa 2。(右):法官是 GPT-4,应该更加中性
图16:LLaMa 2 的 SFT 和不同 RLHF 版本在 Safety 和 Helpfulness 这两个方面的评测结果 (左):法官是 LLaMa 2 的奖励模型,可能有利于 LLaMa 2。(右):法官是 GPT-4,应该更加中性
人工评测 (Human Evaluation)
人工评测通常被认为是判断自然语言生成模型的黄金标准,包括对话模型。为了评估主要模型版本的质量,作者要求人工评估员在有用性和安全性上对它们进行评分。
对比的模型:开源模型有 Falcon-40B, MPT-7B, Vicuna-13B。闭源模型有:ChatGPT (gpt-3.5-turbo-0301),PaLM (chat-bison-001)。如下图17是每个模型的人工评估的最终 Prompt 数。
 图17:每个模型的人工评估的最终 Prompt 数
图17:每个模型的人工评估的最终 Prompt 数
如图18所示是大约 4,000 个 Helpfulness Prompt 下的 LLaMa 2-CHAT 模型的评估结果。LLaMa 2-CHAT 模型在单轮和多轮提示上都优于开源模型。LLaMa 2-CHAT 7B 模型在 60% 的提示上优于 MPT-7B-CHAT。LLaMa 2-CHAT 34B 与同等大小的 Vicuna-33B 和 Falcon 40B 模型的总体胜率超过 75%。最大的 LLaMa 2-CHAT 模型与 ChatGPT 相比也具有竞争力。LLaMa 2-CHAT 70B 模型胜率为 36%,与 ChatGPT 相比平局率为 31.5%。
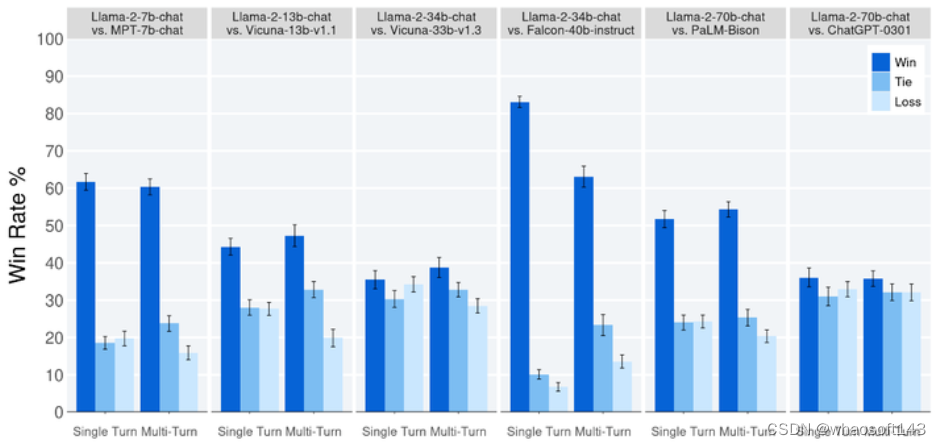 图18:大约 4,000 个 Helpfulness Prompt 下的 LLaMa 2-CHAT 模型的评估结果
图18:大约 4,000 个 Helpfulness Prompt 下的 LLaMa 2-CHAT 模型的评估结果
人工评测的局限性:
-
测试集只包括 4k 个 Prompt,并没有涵盖这些模型所有的真实世界用法。
-
Prompt 的多样性可能会影响最终结果。测试集里不包含任何编码或推理相关的 Prompt。
-
只评估多轮对话的生成结果,一种更有趣的评估方法是让模型完成一项任务,多次对模型的整体经验评分。
-
对生成模型而言,人工评估本质上就主观且嘈杂。对不同的 Prompt 或 Instruction 的评估结果可能会不同。
本文链接:https://my.lmcjl.com/post/9122.html
4 评论