文章目录
- 1 ChatGPT简介
- 2 ChatGPT发展历程
- 3 ChatGPT原理
- 4 ChatGPT与我们关系
- 4.1 ChatGPT与大数据关系
- 4.2 ChatGPT与Java关系
- 4.3 ChatGPT时代机遇
- 4.4 ChatGPT存在的问题
- 4.5 ChatGPT发展思考
1 ChatGPT简介
众所周知,最近,由美国人工智能公司OpenAI推出的大语言模型ChatGPT风靡全球,国内热度也持续高涨,IT界更是疯狂。伴随而来的是各种ChatGPT的声音,身边很多普通人的声音则是将ChatGPT看着是能与人类对话机器或者能替换很多语言相关工作者,当然包括咱们部分程序员哈。我想,他的出现,或许是人工智能发展历史的一个转折点。
2 ChatGPT发展历程
ChatGPT 是一类被叫做大型语言模型(LLM)的机器学习自然语言处理模型的衍生。LLM 特点是:
- 可以消化大量的文本数据,并推断文本的单词之间的关系。
- 随着计算能力的进步,这些模型在过去几年获得了长足发展。
- 随着输入数据集与参数空间的不断扩大,LLM 的能力也会相应提高。
对语言模型最基本的训练包括预测单词序列里面的一个单词。最常见的,通常是“下一个单词预测”(next-token-prediction,其目标是在给定一些文本的情况下,预测下一个可能出现的单词或标记。该任务是语言模型的基础,可以用于文本生成、自动翻译、语音识别等应用中)以及掩码语言建模(masked-language-modeling,主要思想是将输入文本中的一些标记或单词遮盖掉,然后让模型预测这些被遮盖的标记或单词)。
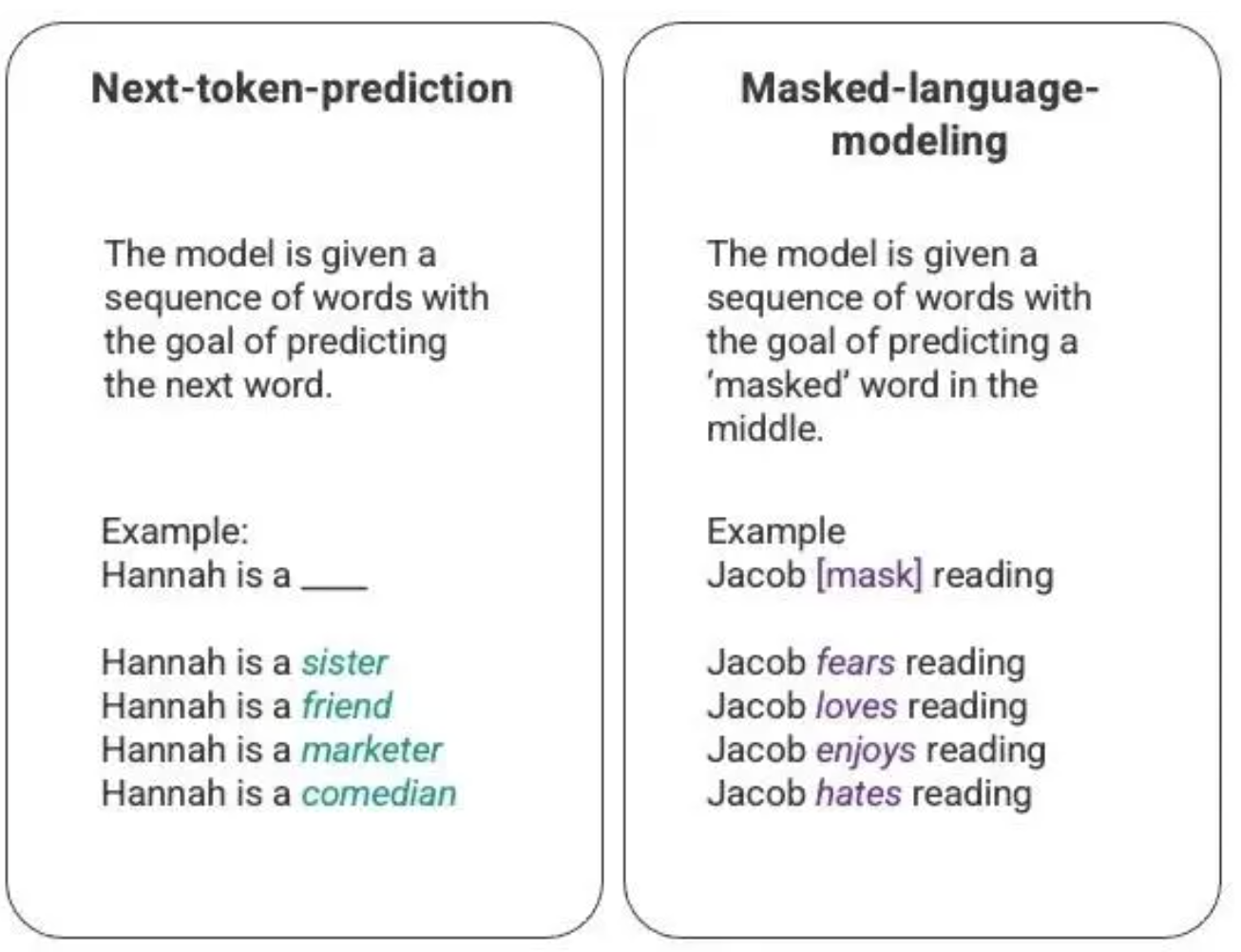
上图是一个基本序列建模技术的示例,通常通过长短期记忆(LSTM,一种特殊的循环神经网络 RNN)模型来部署。在给定上下文的情况下,LSTM 模型会用统计概率最高的词来填充空白。这种序列建模结构有以下两个主要限制:
- 模型没法赋予某些上下文更高的权重。在上面的例子里,比如,上文提到“Jacob hates reading”,模型可能会默认将“reading”和“hates”联系在一起,但是在实际应用中,如果数据中有“Jacob”这个人物,并且在该数据中,“Jacob”非常喜欢阅读,那么在处理“Jacob hates reading”这个句子时,模型应该更加注重“Jacob”的信息,而不是简单地依据上下文中“reading”和“hates”之间的关系来得出结论。因此,如果模型仅仅依赖上下文中的单词,而无法充分考虑文本中实体之间的关系,那么在实际应用中,可能会得出错误的结论。
- 其次,LSTM 处理输入数据时是基于序列逐个输入并逐步处理的,而不是一次性将整个语料库一起处理。这意味着在训练 LSTM 时,上下文窗口大小是固定的,只能在序列的几个步骤之间扩展,而不能跨越整个序列。这种方式限制了 LSTM 模型去捕捉到词与词之间更复杂的关系,以及从中推导出更多的意义。
针对这个问题,2017 年 Google Brain 的一支团队引入了 transformers。与 LSTM 不同,transformers可以同时处理所有的输入数据。Transformers 基于自注意力(self-attention,对于每个单词,self-attention 可以通过计算该单词与其他单词之间的关系强度来加强或减弱该单词的表示,从而更好地捕捉语义信息)机制,该模型可以根据输入数据不同部分与语言序列任何位置的关系赋予其不同的权重。在给 LLM 注入意义方面,这一特性取得了巨大改进,并可支持处理更大的数据集。
-
2018 年,OpenAI 首次推出了 Generative Pre-training Transformer(模型),代号为 GPT-1。
-
2019 年,该模型继续演进出 GPT-2。
-
2020 年,GPT模型演进到 GPT-3。乃至于2022 年11月的 InstructGPT 以及 ChatGPT 。在将人类反馈集成到系统之前,GPT 模型演进的最大进步是由计算效率所取得的成就推动的,这让 GPT-3 比 GPT-2 多
接收了很多数据用来训练,赋予它更多样化的知识库,以及执行更广泛任务的能力。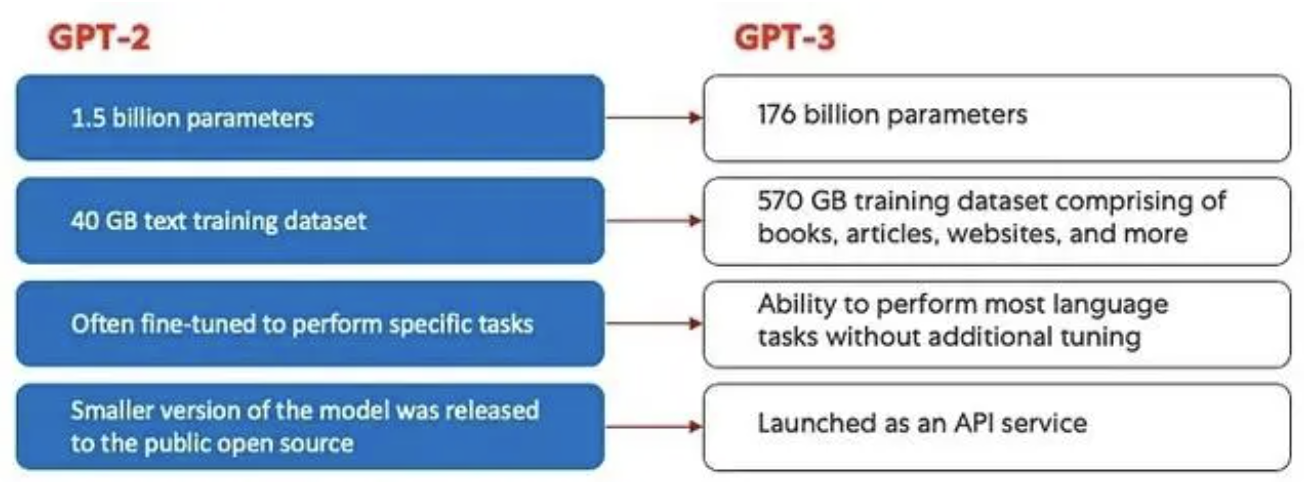
3 ChatGPT原理
ChatGPT 是 InstructGPT 的升级,它的新颖之处在于将人类反馈纳入到训练过程之中,以便让模型输出更好地与用户的意图保持一致。2022 年,OpenAI 发表论文《Training language models to follow instructions with human feedback》(使用人类反馈指令流来训练语言模型),介绍了利用人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)。这就是ChatGPT核心思想,具体原理如下:

- Step1:搜集训练数据集并用监督策略训练模型 (SFT)
- 从提示数据集中进行抽样适量的提示数据
- 标签工作者根据提示做出适当的回应,从而为每一个输入创建一个已知的输出。需保障数据集多样化和准确化。
- 将上一步骤中形成的数据集采用监督学习方式对GPT模型微调,从而建立GPT-3.5,也称为SFT模型。
- Step2:收集对比数据并训练奖励模型(RM)
- 在Step1中训练SFT模型后,1个提示针对系列模型后,对其输出进行采样
- 标签工作者将输出采样的数据按照最好到最坏进行排序,形成多组新的数据集,从而增加模型的多样性和泛化能力
- 将上述分组排序好的数据集用来训练奖励模型
- Step3:使用PPO强化学习方式,将优化模型分配给奖励模型
- 从数据集中获取一个新的提示,编写一个关于水濑的故事?
- 根据监督策略初始化PPO(近端策略优化策略)模型,这种方法可以用来在模型生成响应时更新策略
- 对于一个新的提示,根据PPO策略生成输出
- 对于输出使用强化模型计算奖励
- 奖励用于更新PPO策略,然后再输出,再奖励,再更新,如此循环…
4 ChatGPT与我们关系
4.1 ChatGPT与大数据关系
- 再GTP工作原理中,每个模型都需要数据集,在真实的应用场景中,数据量比较大、比较复杂、并且分布多台服务器,这时候需要大数据负责采集
- 对于采集好的数据,需要根据ChatGPT工程师的要求,去将数据进行加工处理,比如去重、过滤、选择等
- 任何人工智能产品都是模型和数据的结合,高质量的数据会极大的改善或者推进整个人工智能产品的升级与使用体验
4.2 ChatGPT与Java关系
- ChatGPT原理中,我们知道每一步中都有很多模型,模型之间相互有关联,那么最终的模型怎么应用到生产上,需要Java服务端人员去分布式的解析模型,应用于真实数据
4.3 ChatGPT时代机遇
4.4 ChatGPT存在的问题
在测试过程中也发现了ChatGPT存在的一些问题,在这里与大家分享一下。


图4-5 ChatGPT在解答应用题时缺乏底层的逻辑推理能力[1]
首先第一个问题,是简单的逻辑,发现它几乎能搞定。但第二个问题发现了ChatGPT不具有复杂问题推理的能力。以这道比例问题为例,虽然看起来有逻辑,但是实际上已经是在胡扯了。之所以可以生成这段,我猜测是训练过程中见过类似的应用题。但是实际上没有明白应用题背后的原理与解答过程,即这个推理过程。

图5 ChatGPT在回答主观性问题时,为保证安全性存在模版[1]
在一些需要主观评价的问题上,出于安全考虑在训练过程中采用了一定的模版,导致生成的回复有明显的模版生成的感觉。
我发了几遍的如何看待中国发展?如何看待美国的发展?这两个截图都被和谐了,换了这个试试房地产问题试试,大家也可以自行搜索一些你关心的领域的话题,看看回答效果是否模板化。

图6 ChatGPT缺乏事实性检测
缺乏一些事实性检测,西游记的作者并不是施耐庵,但是模型并未识别出来。
存在一些与真实业务场景偏差的回答,由于展示或者训练原因,答案比较片面或者不够理想:

图7 ChatGPT片面性测试
ChatGPT编程能力暂时还无法达到很深入,一些基础的几乎问题不大,稍微修改或直接运行即可实现功能,的确可以带来一种编程快感:

具体Python代码如下:
def generate_triangle(numRows):triangle = []for i in range(numRows):row = []for j in range(i+1):if j == 0 or j == i:row.append(1)else:row.append(triangle[i-1][j-1] + triangle[i-1][j])triangle.append(row)return triangledef print_triangle(triangle):for row in triangle:print(" ".join([str(i) for i in row]).center(50))numRows = int(input("请输入杨辉三角的行数:"))
triangle = generate_triangle(numRows)
print_triangle(triangle)
4.5 ChatGPT发展思考
ChatGPT表现有让大家惊喜,也有让大家惊吓,那么在好与坏中,我们应该怎么去利用好ChatGPT及其思想呢?
-
研究一些更底层的,大小模型都适用的问题
比如,如何提高模型的鲁棒性与泛化能力;如何提高模型的逻辑推理能力,即使强如ChatGPT,在一些复杂的推理问题中还是很难学会其中的底层逻辑,更多时候只是从已经看见过的数据中进行类比与生成。
-
研究一些与特定领域结合的任务
与其他领域结合,比如医疗,金融,生物制药等领域,通过融合相关领域的特异性知识,进行模型结构上的设置,融入一些巧思,做好特定的任务。比如前一阵子看到的scBERT,做的就是一项利用mRNA的表达进行细胞类型判断的任务,通过结合mRNA的特性与相关知识,设计了特有的类别编码与基因编码以及预训练任务,成功将预训练模型引入这一领域。
-
做以数据为中心的任务
OpenAI相关工作人员曾指出,在训练大模型的时候高质量的数据是至关重要的。吴恩达这两年也提出Data-centic AI(DCAI),将焦点从模型开发转移到数据层面,研究如何将有限的数据变得更多更好。
参考资料:
[1] 官网链接:https://openai.com/blog/chatgpt
[2] 网络链接:https://mp.weixin.qq.com/s?__biz=MzI4MDYzNzg4Mw==&mid=2247554744&idx=2&sn=3b93ca4720cd86fb13978d40a2c691c6&chksm=ebb72e6cdcc0a77a56a7ab0e1b315baf7801e418af0d1f88c0446dd25e93c8b50a6cdc471cb0&scene=27
[3] 网络链接:https://baijiahao.baidu.com/s?id=1758693674943354647&wfr=spider&for=pc
本文链接:https://my.lmcjl.com/post/9991.html
4 评论