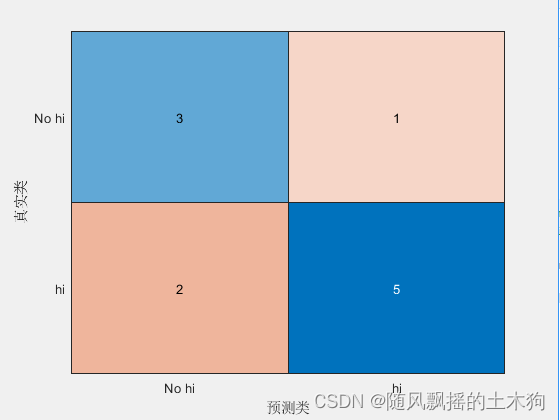
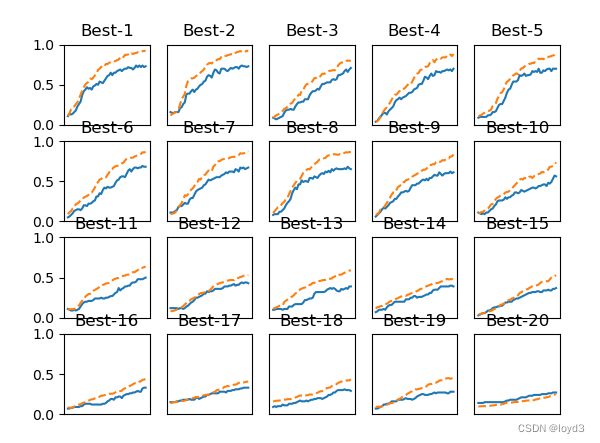
机器学习的问题中,过拟合是一个很常见的问题。过拟合指的是只能拟合训练数据,但不能很好地拟合不包含在训练数据中的其他数据的状态。机器学习的目标是提高泛化能力,即便是没有包含在训练数据里的未观测数据也希望模型可以进行正确的识别。 发生过拟合的原因,主要有以下两个: 模型拥有大量参数、表现力强。训练数据少。 那么如何来抑制过拟合 正则化是有效方法之一,它不仅可以有效降低高方差,还有利于降低偏差。何为 继续阅读
【深度学习】5-4 与学习相关的技巧 - 正则化解决过拟合(权值衰减,Dropout)