这本Python网络数据爬取及分析从入门到精通(分析篇)图书,是2018-06-01月由北京航空航天大学出版社所出版的,著作者信息: 杨秀璋,颜娜 著,本版是第1次印刷, ISBN:9787512427136,品牌:北京航空航天大学出版社, 这本书的包装是小全开平装,所用纸张为胶版纸,全书页数未知,字数有万字, 是本值得推荐的Python软件开发图书。此书内容摘要Python网络数据爬取及分析从入门到精通(分析篇)本书采用通俗易懂的语言、丰富多彩的实例,详细介绍了使用Python语言进行网络数据 继续阅读
Search Results for: 爬取数据
查询到最新的12条
python实战项目scrapy管道学习爬取在行高手数据
爬取目标站点分析 本次采集的目标站点为:https://www.zaih.com/falcon/mentors,目标数据为在行高手数据。 本次数据保存到 MySQL 数据库中,基于目标数据,设计表结构如下所示。 对比表结构,可以直接将 scrapy 中的 items.py 文件编写完毕。 class ZaihangItem(scrapy.Item): # define the fields for your item he 继续阅读
为什么微博用jsoup爬取不出来东西_用Python爬取历年基金数据
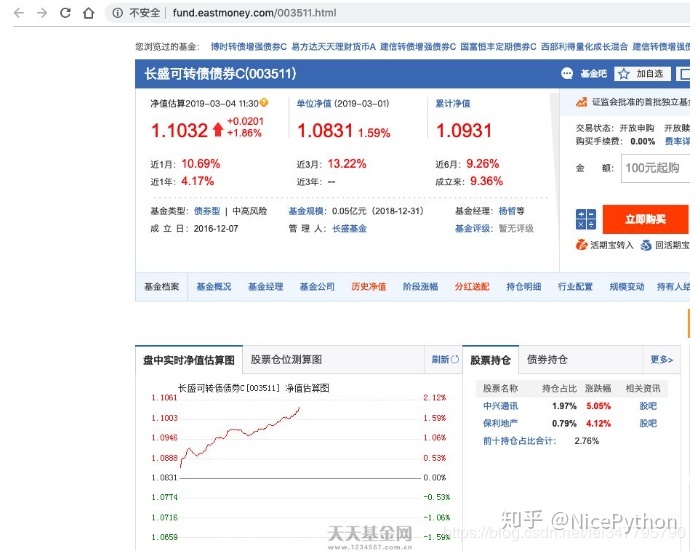
接口分析爬数据需要先思考从哪里爬?经过一番搜索和考虑,我发现天天基金网的数据既比较全,又十分容易爬取,所以就从它入手了。首先,随便点开一支基金,我们可以看到域名就是该基金的代码,十分方便,其次下面有生成的净值图。 基金详情打开chrome的开发者调试,选择Network,然后刷新一下,很快我们就能发现我们想要的东西了。可以看到,这 继续阅读
php爬取天猫和淘宝商品数据
一、思路 最近做了一个网站用到了从网址爬取天猫和淘宝的商品信息,首先看了下手机端的网页发现用的react,不太了解没法搞,所以就考虑从PC入口爬取数据,但是当爬取URL获取数据时并没有获取价格,库存等的信息,仔细研究了下发现是异步请求了另一个接口,但是接口要使用refer才能获取数据,于是就通过以下方式写了一个简单的爬虫,用于爬取商品预览图和商品的第一个分类的价格、库存等。 二、实现 代码如下: php;" > function crawlUrl($url){ impor 继续阅读
python scrapy拆解查看Spider类爬取优设网极细讲解
目录 拆解 scrapy.Spider scrapy.Spider 属性值 scrapy.Spider 实例方法与类方法 爬取优设网 Field 字段的两个参数: 拆解 scrapy.Spider 本次采集的目标站点为:优设网 每次创建一个 spider 文件之后,都会默认生成如下代码: 继续阅读
Chatgpt-3 使用的提取数据集技术、数据集自动化处理和保证数据质量
为了积累数据集,ChatGPT-3使用了一系列技术来从不同来源的文本中提取数据。其中最常用的技术包括: Web scraping:ChatGPT-3使用Web scraping技术从互联网上的网页中提取文本。它可以自动化抓取网页,并从中提取出需要的信息。 数据库查询:ChatGPT-3使用数据库查询系统来收集从各种来源收集到的数据。这是一种常用的技术,在大型网站和应用程序中广泛使用。 API收集ÿ 继续阅读
Python3以GitHub为例来实现模拟登录和爬取的实例讲解
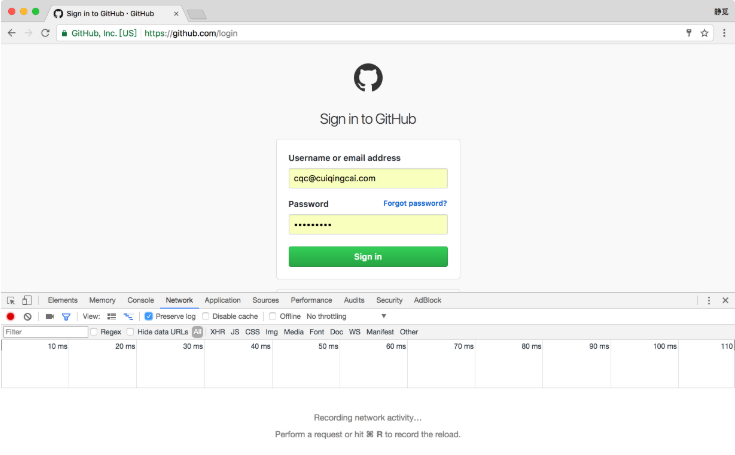
我们先以一个最简单的实例来了解模拟登录后页面的抓取过程,其原理在于模拟登录后 Cookies 的维护。 1. 本节目标 本节将讲解以 GitHub 为例来实现模拟登录的过程,同时爬取登录后才可以访问的页面信息,如好友动态、个人信息等内容。 我们应该都听说过 GitHub,如果在我们在 Github 上关注了某些人,在登录之后就会看到他们最近的动态信息,比如他们最近收藏了哪个 Repository,创建了哪个组织,推送了哪些代码。但是退出登录之后,我们就无 继续阅读
SAP获取采购订单相关数据
1.在 ABAP 中获取采购订单(Purchase Order,即 PO)数据,可以使用函数模块 BAPI_PO_GETDETAIL1 或者查询 SAP 数据库中的 EKKO 表和 EKPO 表来实现。下面分别简要介绍这两种方法。 2.使用函数模块 BAPI_PO_GETDETAIL1 3.使用函数模块 BAPI_PO_GETDETAIL1 可以获取 PO 的详细信息,包括 PO 的头部信息和行项目信息。以下是一个简单的示例: REPORT z_test_po_info.DATA: lt_p 继续阅读
用Python爬取指定关键词的微博
前几天学校一个老师在做微博的舆情分析找我帮她搞一个用关键字爬取微博的爬虫,再加上最近很多读者问志斌微博爬虫的问题,今天志斌来跟大家分享一下。 一、分析页面 我们此次选择的是从移动端来对微博进行爬取。移动端的反爬就是信息校验反爬虫的cookie反爬虫,所以我们首先要登陆获取cookie。 登陆过后我们就可以获取到自己的cookie了,然后我们来观察用户是如何搜索微博内容的。 平时我们都是在这个地方输入关键字,来进行搜索微博。 继续阅读
Python爬虫中Requests设置请求头Headers的方法
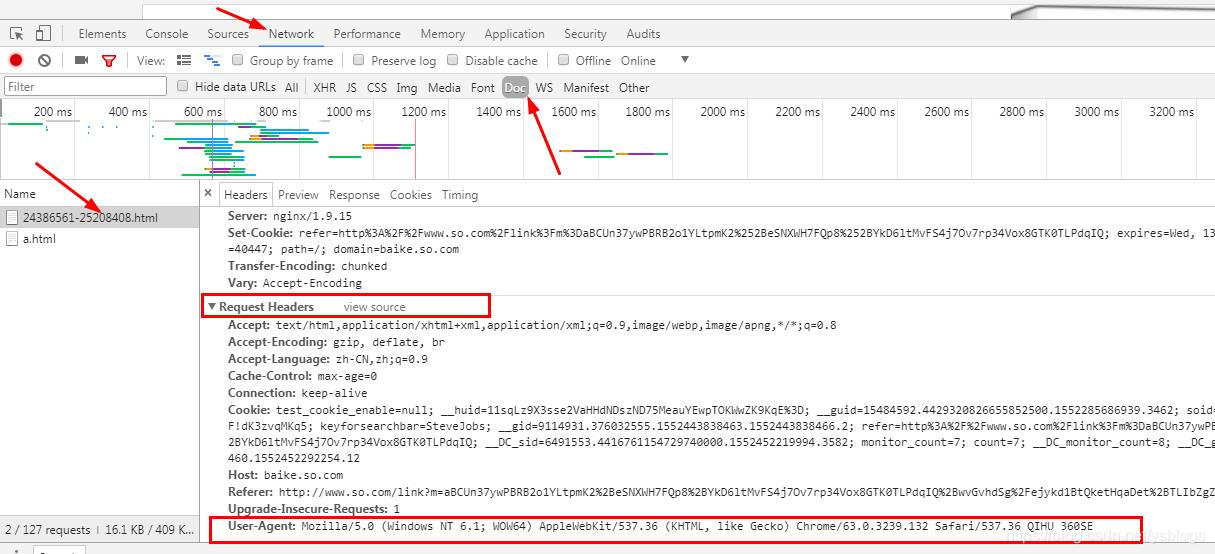
1、为什么要设置headers? 在请求网页爬取的时候,输出的text信息中会出现抱歉,无法访问等字眼,这就是禁止爬取,需要通过反爬机制去解决这个问题。 headers是解决requests请求反爬的方法之一,相当于我们进去这个网页的服务器本身,假装自己本身在爬取数据。 对反爬虫网页,可以设置一些headers信息,模拟成浏览器取访问网站 。 2、 headers在哪里找? 谷歌或者火狐浏览器,在网页面上点击:右键–> 继续阅读
解析Python网络爬虫:核心技术、Scrapy框架、分布式爬虫
编程书籍推荐:解析Python网络爬虫:核心技术、Scrapy框架、分布式爬虫,由中国铁道出版社2018-08-01月出版,本书发行作者信息: 黑马程序员 著此次为第1次发行, 国际标准书号为:9787113246785,品牌为中国铁道出版社, 这本书采用平装开本为16开,附件信息:未知,纸张采为胶版纸,全书共有272页字数万 字,值得推荐的Python Book。此书内容摘要 网络爬虫是一种按照一定的规则,自动请求万维网网站并提取网络数据的程序或脚本,它可以代替人 继续阅读
Python爬虫 从小白到高手 Urllib
Urllib 1.什么是互联网爬虫? 如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的数据 解释1:通过一个程序,根据Url(http://www.taobao.com)进行爬取网页,获取有用信息 解释2:使用程序模拟浏览器,去向服务器发送请求,获取响应信息 继续阅读