美赛一年又一年,当大家考虑如何能在美赛四天三夜的比赛中爬取关于美赛某道题的数据时,有没有考虑过爬取并统计美赛的比赛结果😄。一方面可以通过爬取美赛结果知道自己学校今年的获奖情况,另一方面可以知道身边哪些大佬又在美赛中大展身手。
第一部分:从总表中获得xx学校的所有队伍号
(1)这一部分先加载获奖的总表
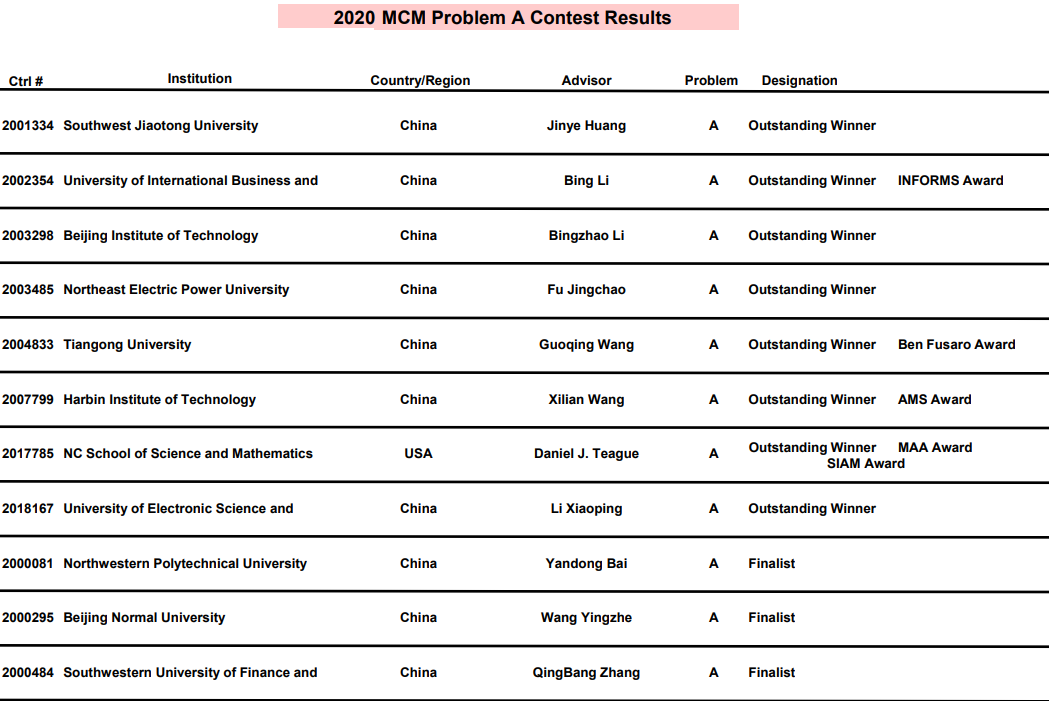
- 这里首先爬取总表的数据,总表大概就长这样,这里以2020年美赛A题的总表为例,看到在总表中可以得到队伍号、学校名称、获奖学校所属的国家、导师名、题目类型、奖项等级这几个信息,比较重要的是队伍号、学校名称和奖项等级。ps: 因为想知道获奖大佬的名字,因此爬到这里不能结束,但是如果只是想知道各学校获奖情况,只要处理这几份总表就可以了。
import requests
import time
from tqdm import notebooktime_start=time.time()
year = "2020" #定义年代为2020年
#将MCM与ICM做简单的区分
problem_type_MCM = ['A','B','C']
problem_type_ICM = ['D','E','F']
#这是总表的位置
general_download_pdf_url = "https://www.comap.com/undergraduate/contests/mcm/contests/"
#这是总表下载存储的位置
general_save_pdf_path = "/data/python大作业/totalpdf/"
#该函数实现下载pdf的功能
def download_pdf(file_url,problem):try:pdf_html = requests.get(file_url, stream=True) #首先得到目标url文件pdf_html.raise_for_status #检测是否正常total_size = int(pdf_html.headers.get("Content-Length")) #获取总长度,作为下面进度条长度的参考with open(general_save_pdf_path + problem + '.pdf', "wb") as pdf: with notebook.tqdm(total=total_size, desc='{}题下载进程'.format(problem)) as pbar: for chunk in pdf_html.iter_content(chunk_size=1024): # 一个chunk一个chunk的读取全部文件if chunk:pdf.write(chunk) # 写入到本地文件中pbar.update(len(chunk))return Trueexcept:return False
#下载MCM的PDF
for item in problem_type_MCM:#组成该文件的URLspecial_type = general_download_pdf_url + year + "/results/" \+ year + "_MCM_Problem_" + item + "_Results.pdf"#下载PDFif download_pdf(special_type,item) == True:print("MCM题目:{}下载完成".format(item))else:print("MCM题目:{}下载失败".format(item))#下载ICM的PDF
for item in problem_type_ICM:#组成该文件的URLspecial_type = general_download_pdf_url + year + "/results/" \+ year + "_ICM_Problem_" + item + "_Results.pdf"#下载PDFif download_pdf(special_type,item) == True:print("ICM题目:{}下载完成".format(item))else:print("ICM题目:{}下载失败".format(item))
time_end=time.time()
print('time cost',time_end-time_start,'s')
(2)这一部分将PDF转化成txt文本
- 为了方便后续进行信息的读取与处理,这里需要提前把 pdf 转化成 txt 文本。
import urllib
import importlib,sys
importlib.reload(sys)
from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.pdfdevice import PDFDevice
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed#下面给出一般路径
#这个表示读取总PDF的位置
general_read_pdf_path = r'/data/python大作业/totalpdf/'
#这个表示存储转化后的txt的位置
general_save_txt_path = r'/data/python大作业/totaltxt/'def parse(DataIO, save_path):#用文件对象创建一个PDF文档分析器parser = PDFParser(DataIO)#创建一个PDF文档doc = PDFDocument()#分析器和文档相互连接parser.set_document(doc)doc.set_parser(parser)#提供初始化密码,没有默认为空doc.initialize()#检查文档是否可以转成TXT,如果不可以就忽略if not doc.is_extractable:raise PDFTextExtractionNotAllowedelse:#创建PDF资源管理器,来管理共享资源rsrcmagr = PDFResourceManager()#创建一个PDF设备对象laparams = LAParams()#将资源管理器和设备对象聚合device = PDFPageAggregator(rsrcmagr, laparams=laparams)#创建一个PDF解释器对象interpreter = PDFPageInterpreter(rsrcmagr, device)#循环遍历列表,每次处理一个page内容#doc.get_pages()获取page列表for page in doc.get_pages():interpreter.process_page(page)#接收该页面的LTPage对象layout = device.get_result()#这里的layout是一个LTPage对象 里面存放着page解析出来的各种对象#一般包括LTTextBox,LTFigure,LTImage,LTTextBoxHorizontal等等一些对像#想要获取文本就得获取对象的text属性for x in layout:try:if(isinstance(x, LTTextBoxHorizontal)):with open('%s' % (save_path), 'a') as f:result = x.get_text()f.write(result + "\n")except:print("Failed")#读出该文件夹下面所有文件
filenames = os.listdir(general_read_pdf_path)for filename in notebook.tqdm(filenames):#解析本地PDF文本,保存到本地TXTwith open(general_read_pdf_path + filename,'rb') as pdf_html:parse(pdf_html, general_save_txt_path + filename[0] + '.txt')
(3)这一部分查找每个PDF中的xx学校的队伍号

- 这里的关键在于正则表达式的书写
model = re.compile(r"(?i)20\d{5}@@Xi'an Jiaotong University"),其中(?i)表示不区分大小写(有的人会把学校名称都整成小写的),后面20是根据队伍编号的特征来的,后面的@@是根据代码中s = '@'.join(ls)即采用了@作为分割符,因此在查找时需要加入,具体的连接后的情况如下。
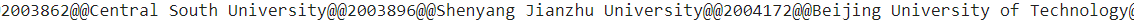
import re
import os
#一般的路径
general_read_txt_path = r'/data/python大作业/totaltxt/'
# 这个给出了查找学校的正则表达式(以西电为例)
model = re.compile(r"(?i)20\d{5}@@Xidian University")
# model = re.compile(r"(?i)20\d{5}@@Xi'an Jiaotong University")
# 这个列表存储所有该学校队伍的编号
team_member = []def detect_team_member(problem_kind):ls = []# 这里打开转化成txt的总表bat = open(general_read_txt_path + problem_kind, 'r')#这里将数据进行整合for line in bat:line = line.replace("\n","")ls.append(line) bat.close()#将上面查到的信息以@作为分割存储到字符串中s = '@'.join(ls) #找到所有符合条件的字符串all_xd = re.findall(model,s)#最后给出所有队伍的队伍号for item in all_xd:team_member.append(str(item).split('@@')[0])#读出该文件夹下面所有文件
filenames = os.listdir(general_read_txt_path)
for filename in filenames:team_member.append(filename[0])detect_team_member(filename)
print(team_member)
#最终队号存储在 team_member 这个变量中
第二部分:获取xx学校所有美赛证书的PDF
- 这部分比较简单,只要根据上面整理出来的该学校的队伍号,拼接上前缀 url 就可以了。
import requests
import os
import time
from tqdm import notebook
total_need_number = len(team_member) - 6time_start=time.time()
general_partpdf_download_url = "http://www.comap-math.com/mcm/2020Certs/"
general_partpdf_save = "/data/python大作业/partpdf/" def download_pdf(file_url,pdf_name):try:pdf_html = requests.get(file_url, stream=True)#首先得到目标url文件pdf_html.raise_for_status()with open(general_partpdf_save + pdf_name, "wb") as pdf:for chunk in pdf_html.iter_content(chunk_size=1024): # 一个chunk一个chunk的读取全部文件if chunk:pdf.write(chunk) # 写入到本地文件中pdf.close()print("\033[1;31m下载完成:{}\033[0m".format(pdf_name))return Trueexcept requests.HTTPError:print("下载失败:{}".format(pdf_name))return Falseexcept Exception as ex:print("出现如下异常:{}".format(ex))return False#这里下载全部PDF,打印对应的下载成功的信息并且用进度条显示总进度
with notebook.tqdm(total=total_need_number, desc='全部PDF下载进程') as pbar: for item in team_member:if item in ['A','B','C','D','E','F']:item_temp = itemcontinueMS_pdf_type = item + '.pdf'file_url = general_partpdf_download_url + MS_pdf_typeif download_pdf(file_url,item_temp + MS_pdf_type) == True:pbar.update(1)time_end=time.time()
print('花费的总时间为:',time_end-time_start,'s')
第三部分:将美赛证书转换成PNG文件并切割
(1)这一部分完成多个PDF文件向PNG文件的转换
- 这里只需要注意一点就是在转换时应将图片进行缩放从而提高图片的分辨率,方便后面通过 OCR 识别里面的内容。
import fitz
import time
time_start=time.time()
general_partpdf_read_path = "/data/python大作业/partpdf/"
general_partpng_save_path = "/data/python大作业/partpng/"#这个函数实现将 PDF文件转换成 PNG文件
def PDF_to_imgs(PDF_path, save_path):doc = fitz.open(PDF_path) # 打开PDF文件,生成一个对象page = doc[0] #由于只有一页,因此直接将这一页存于 page 变量中rotate = int(0)# 每个尺寸的缩放系数为2,这将为我们生成分辨率提高4倍的图像。zoom_x = 2zoom_y = 2trans = fitz.Matrix(zoom_x, zoom_y).preRotate(rotate)pm = page.getPixmap(matrix=trans, alpha=False)pm.writePNG(save_path)#这里直接遍历该文件夹下面所有文件
filenames = os.listdir(general_partpdf_read_path)
for filename in filenames:PDF_to_imgs(general_partpdf_read_path + filename, general_partpng_save_path + filename[0:-4] + '.png')
time_end=time.time()
print('花费的总时间为:',time_end-time_start,'s')
(2)这一部分完成多个PNG文件的切割
- 这里进行图片的切割,需要注意的一点是,这里图片切割的坐标是试出来的,而且 MCM 和 ICM 是不同的。
import time
import os
from PIL import Image
general_partpng_read_path = "/data/python大作业/partpng/"
general_croppng_save_path = "/data/python大作业/croppng/"
crop_tab_MCM = [(500, 330, 1170, 500),(500, 550, 1170, 600),(300,760, 1170, 920)]
crop_tab_ICM = [(500, 330, 1170, 480),(500, 530, 1170, 600),(300,760, 1170, 920)]time_start=time.time()
filenames = os.listdir(general_partpng_read_path)
for filename in filenames:img = Image.open(general_partpng_read_path+ filename)if filename[0] in ['A','B','C']:for i in range(len(crop_tab_MCM)):cropped = img.crop(crop_tab_MCM[i]) # (left, upper, right, lower)cropped.save(general_croppng_save_path + filename[0:-4] + '%' + str(i) + ".png")elif filename[0] in ['D','E','F']:for i in range(len(crop_tab_ICM)):cropped = img.crop(crop_tab_ICM[i]) # (left, upper, right, lower)cropped.save(general_croppng_save_path + filename[0:-4] + '%' + str(i) + ".png")
time_end=time.time()
print('花费的总时间为:',time_end-time_start,'s')
第四部分:切割后的PNG文件中的文本提取
- 最后给出的是一个 csv 文件,这个文件中存储了参赛队号,题目类型,参赛队员,指导老师,获奖类型这几类信息,并且默认参赛队员的人数为三人。
import pytesseract
import os
from PIL import Image
import time
import csv
from tqdm import notebooktime_start=time.time()
#读取partpng的一般路径
general_partpng_read_path = "/data/python大作业/partpng/"
#读取croppng的一般路径
general_croppng_read_path = "/data/python大作业/croppng/"
#存储最终结果数据totaltxt的一般路径
general_totaltxt_save_path = "/data/python大作业/final_result.csv"#最终将给出一个CSV文件,顺序为参赛队号,题目类型,参赛队员,指导老师,获奖类型
#注意这里默认美赛的参赛者有三个人
def img_to_txt(imgs_path,imags_name):temp = [] #这是一个暂存的列表temp.append(imags_name[1:-1] + imags_name[-1]) #把队号存入temp.append(imags_name[0]) #把题目存入#把三个队员名字存入image = Image.open(general_croppng_read_path + imags_name + "%0.png")content = pytesseract.image_to_string(image).split('\n')for i in range(len(content)):temp.append(content[i])for i in range(1,3):image = Image.open(general_croppng_read_path + imags_name + "%" + str(i) + ".png")content = pytesseract.image_to_string(image)temp.append(content)csv_writer.writerow(temp)f = open(general_totaltxt_save_path,'w',encoding='utf_8_sig')
#这里生成一个CSV对象
csv_writer = csv.writer(f)
#首先将第一行,表头写入
csv_writer.writerow(["队号","题目","队员一","队员二","队员三","教练","获奖"])
#读取该文件夹下面所有文件
filenames = os.listdir(general_partpng_read_path)
with notebook.tqdm(total=len(filenames), desc='PNG文件提取进度') as pbar: for filename in filenames:img_to_txt(general_partpng_read_path + filename[0:-4],filename[0:-4])pbar.update(1)f.close()time_end=time.time()print('花费的总时间为:',time_end-time_start,'s')
- 完成上面的步骤,基本的信息统计就完成了,接下来的信息分析就可以借助超神工具 excel 来进行了。
本文链接:https://my.lmcjl.com/post/10376.html
展开阅读全文
4 评论