系统环境
python 3.7
windows 10
一些python依赖包使用pip install 安装即可,出现报错时用conda install 一般均可以正确安装
百度语音API与讯飞语音API使用方式几乎一致,也可使用讯飞语音API
整个百度语音识别api 使用分为三部分:
1 (申请操作)创建应用,获取应用的 API Key 以及 Secret Key。
2 (程序实现)通过已知的 应用的 API Key 以及 Secret Key, 发送post 请求到 https://openapi.baidu.com/oauth/2.0/token 获取 token
(程序实现) 通过上步骤获取的 token,通过post, 发送相关的语音信息到 http://vop.baidu.com/server_api ,获取识别结果.
实现步骤
**
一、申请百度语音AI平台账号
进入百度语音识别AI网站 百度语音AI网站
点击立即使用进入登录注册界面,按顺序操作即可,登录百度账号即可。
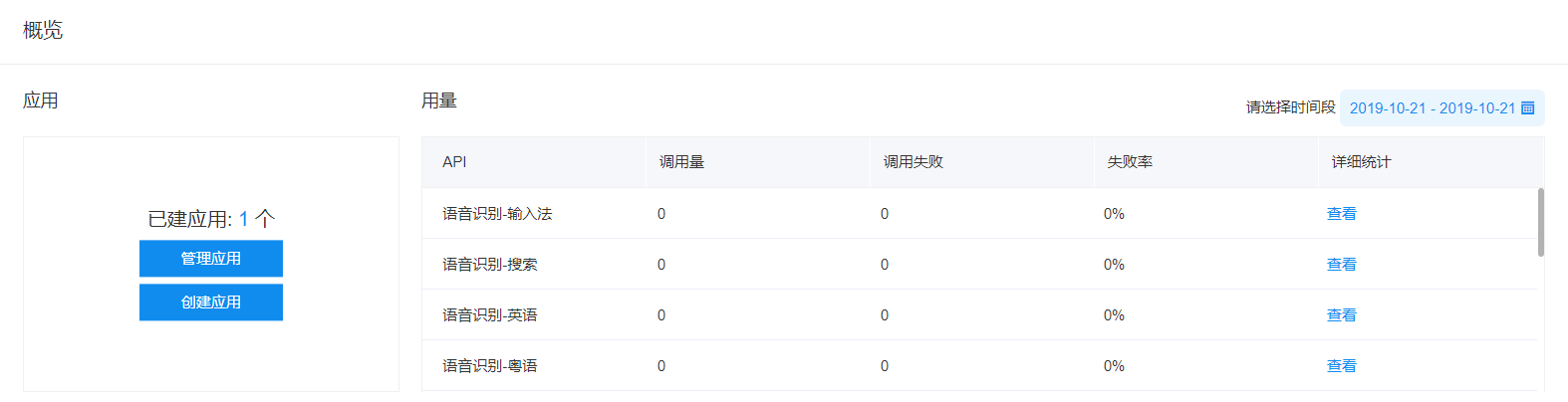
然后选择创建应用,创建完成后会有专属于自己的API key与Screct Key,这些在下面python代码里会用到,需要改为自己的key。
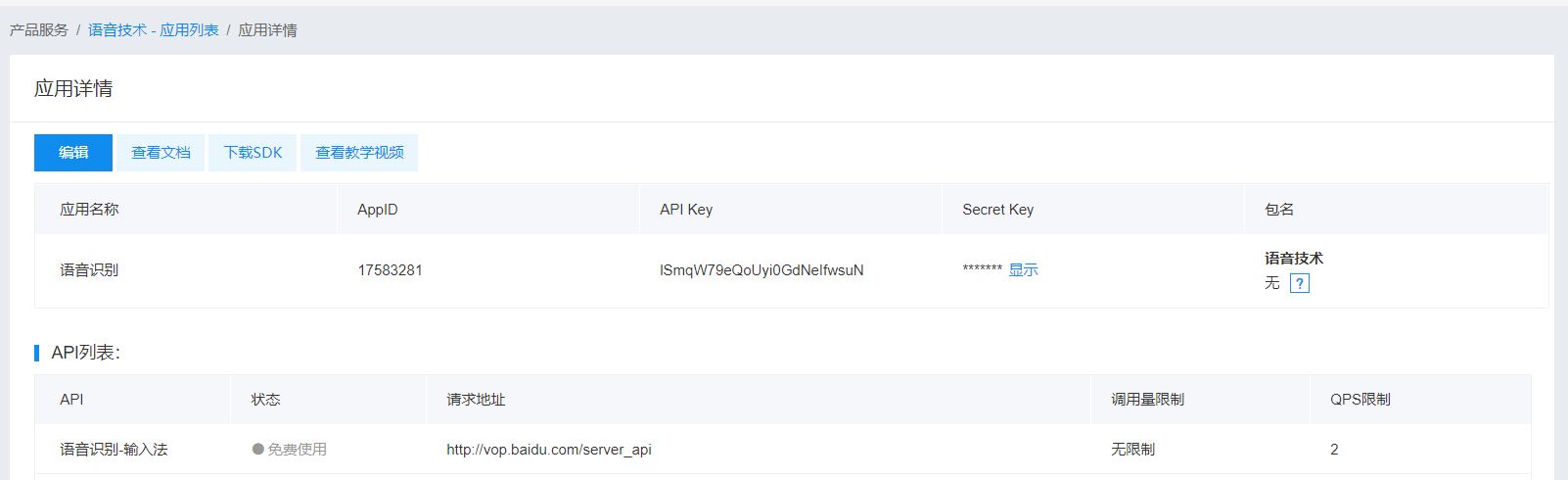
二、python实现语音识别
代码部分来自于CSND博客,看代码中一些print输出应该是北京邮电大学的学生,但关闭网页后找不到原文,若有侵权,请联系。
import urllib.request
import urllib
import json
import base64
class BaiduRest:def __init__(self, cu_id, api_key, api_secert):# token认证的urlself.token_url = "https://openapi.baidu.com/oauth/2.0/token?grant_type=client_credentials&client_id=%s&client_secret=%s"# 语音合成的resturlself.getvoice_url = "http://tsn.baidu.com/text2audio?tex=%s&lan=zh&cuid=%s&ctp=1&tok=%s"# 语音识别的resturlself.upvoice_url = 'http://vop.baidu.com/server_api'self.cu_id = cu_idself.getToken(api_key, api_secert)returndef getToken(self, api_key, api_secert):# 1.获取tokentoken_url = self.token_url % (api_key,api_secert)r_str = urllib.request.urlopen(token_url).read()token_data = json.loads(r_str)self.token_str = token_data['access_token']passdef getText(self, filename):# 2. 向Rest接口提交数据data = {}# 语音的一些参数data['format'] = 'wav'data['rate'] = 8000data['channel'] = 1data['cuid'] = self.cu_iddata['token'] = self.token_strwav_fp = open(filename,'rb')voice_data = wav_fp.read()data['len'] = len(voice_data)data['speech'] = base64.b64encode(voice_data).decode('utf-8')post_data = json.dumps(data)r_data = urllib.request.urlopen(self.upvoice_url,data=bytes(post_data,encoding="utf-8")).read()# 3.处理返回数据return json.loads(r_data)['result']if __name__ == "__main__":#上面得到的API key与Screct Key,替换为自己的即可api_key = "EE1***************" api_secert = "YDD5O***********************"# 初始化bdr = BaiduRest("test_python", api_key, api_secert)# 识别test.wav语音内容并显示print(bdr.getText("16k.wav"))
运行结果为:

上面的测试文件“16k.wav”可在百度语音示例demo里下载,地址为: 百度语音示例Github链接
百度语音官方文档中写的支持的语音格式为:
原始 PCM 的录音参数必须符合 16k 采样率、16bit 位深、单声道,支持的格式有:pcm(不压缩)、wav(不压缩,pcm编码)、amr(压缩格式)
但刚才在测试中发现手机录音文件也可以,华为手机的.m4a格式的录音文件可以实现识别。
需要更改的代码如下两张图所示:
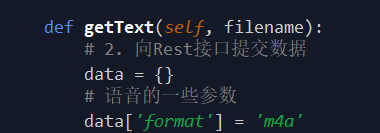

可以看出这个文件是标准的手机录音文件,以具体日期时间命名。
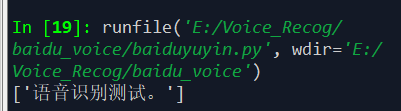
运行结果如下所示,是完全正确的,这就不知道是因为华为录音软件本身就将语音信号的噪音处理的很好了还是百度语音API确实做的很好:
另外台式机有麦克风的可以试试这个有趣的实验:用 Python 实现自己的智能语音助理(百度语音 + 图灵机器人)智能语音助手具体实现链接
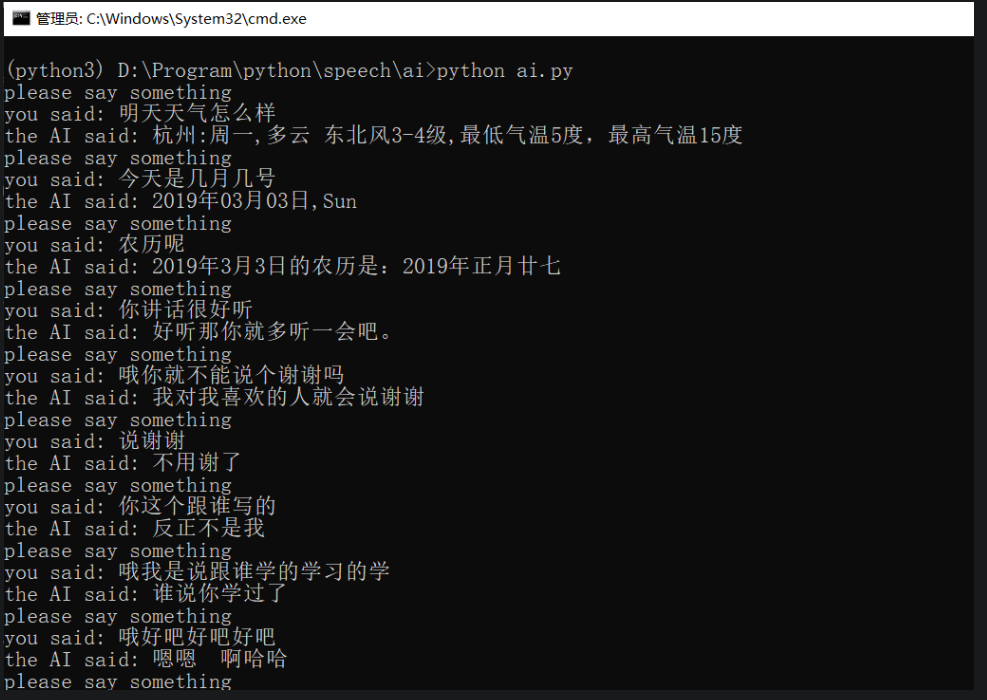
作者实现的效果如下所示
西安市沙坡村职业技术学院
2019年10月21日
本文链接:https://my.lmcjl.com/post/11152.html
4 评论