SQLite3 + mmicu微信全文搜索库编译过程
本来想写一些关于sqlite3相关的技术文章,但是一直较忙,导致很久没有来csdn了。现在来,争取多写些文章。
- ICU库准备
- SQLite3源码准备
- wcdb相关源码
- 工程创建
- 测试工程
1. ICU库准备
因为全文搜索,首先需要对文本进行分词处理。而这个就需要icu相关函数了。所以要先准备icu库。不知道icu库是啥的朋友们可以先自行baidu/google。
下载icu库 http://site.icu-project.org/download/
这里为了省事,直接下载的库,如果想自己编译的,需要下载源码自行编译。
因为已编译的只有到57的版本有win32的,所以没有选取最新的
http://apps.icu-project.org/icu-jsp/downloadPage.jsp?ver=57.1&base=c&svn=release-57-1
2. SQLite3源码准备
因为以前编译时写的相关文档,所以SQLite3不是最新版本。大家可以根据自己需要,去 http://www.sqlite.org 下载最新源码。这里列出需要相关的文件:
Source Code -> sqlite-amalgamation-3200100.zip(需所有文件)
Precompiled Binaries for Windows -> sqlite-dll-win32-x86-3200100.zip(需sqlite3.def文件)
3. 下载wcdb相关源码
wcdb是腾讯微信开源的一个sqlite3相关的组件。里面涉及到对sqlite3数据库的加密,解密,全文搜索,数据库修复等功能及各种对大数据量的优化。
https://github.com/Tencent/wcdb
这里需要fts/mm_tokenizer.c和fts/fts3_tokenizer.h文件
4. 创建SQLite3工程
- 首先需要编译出一个支持icu,fts3的动态链接库出来。步骤如下:
创建一个名叫sqlite3的win32控制台应用程序项目,添加如下文件:

- 将icu文件解压出来,放到父层dependency目录下:

- 在sqlite3.c文件前面加入下面的宏:
/******************************************************************/
/* Preprocessor Macro */
/******************************************************************/
#define SQLITE_ENABLE_ICU 1
#define SQLITE_ENABLE_FTS3 1
#define SQLITE_ENABLE_FTS3_PARENTHESIS 1
#define SQLITE_ENABLE_FTS5 1
#define SQLITE_ENABLE_RTREE 1
#define SQLITE_ENABLE_COLUMN_METADATA 1
/******************************************************************/
- 打开工程属性,进行如下配置:
配置属性 -> 常规 -> 配置类型 -> 动态库(.dll)
配置属性 -> C/C++ -> 常规 -> 附加包含目录 -> ..\dependency\icu\include
配置属性 -> C/C++ -> 预编译头 -> 创建/使用预编译头 -> 不使用预编译头
配置属性 -> 链接器 -> 常规 -> 附加库目录 -> ..\dependency\icu\lib
配置属性 -> 链接器 -> 输入 -> 附加依赖项 -> icudt.lib icuin.lib icuuc.lib
配置属性 -> 链接器 -> 输入 -> 模块定义文件 -> sqlite3.def
配置属性 -> 生成事件 -> 预生成事件 -> 命令行 -> cd.. configure.bat (该处是cd..和configure.bat两个命令)
父层这个configure.bat文件包含如下命令:
if not exist "debug". (md "debug".)
if not exist "release". (md "release".)
if not exist "debug\icudt57.dll" (copy "dependency\icu\bin\icudt57.dll" "debug".)
if not exist "debug\icuin57.dll" (copy "dependency\icu\bin\icuin57.dll" "debug".)
if not exist "debug\icuuc57.dll" (copy "dependency\icu\bin\icuuc57.dll" "debug".)
if not exist "release\icudt57.dll" (copy "dependency\icu\bin\icudt57.dll" "release".)
if not exist "release\icuin57.dll" (copy "dependency\icu\bin\icuin57.dll" "release".)
if not exist "release\icuuc57.dll" (copy "dependency\icu\bin\icuuc57.dll" "release".)
然后进行编译,编译出对应sqlite3库
5. 创建SQLite3Test工程
- 创建一个名叫sqlite3test的win32控制台应用程序项目,添加如下文件:

其中mm_tokenizer.h文件只包含下面内容:

- 打开工程属性,进行如下配置:
配置属性 -> 常规 -> 配置类型 -> 应用程序(.exe)
配置属性 -> C/C++ -> 常规 -> 附加包含目录 -> ..\dependency\icu\include
配置属性 -> C/C++ -> 预编译头 -> 创建/使用预编译头 -> 不使用预编译头
配置属性 -> 链接器 -> 常规 -> 附加库目录 -> ..\dependency\icu\lib
配置属性 -> 链接器 -> 输入 -> 附加依赖项 -> icudt.lib icuin.lib icuuc.lib
配置属性 -> 生成事件 -> 预生成事件 -> 命令行 -> cd.. configure.bat (该处是cd..和configure.bat两个命令)
- 编译
过程中可能有些错误,自行改正。将mm_tokenizer.cpp文件中不需要的函数,头文件去掉。
然后main函数就是测试代码了:
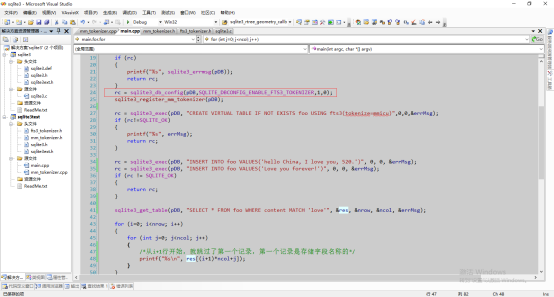
需要注意红线这部分代码,因为由于安全原因,fts3_tokenizer默认是不打开的。需要打开这个功能。

这里列出mm_tokenizer.cpp的源码
/** Tencent is pleased to support the open source community by making* WCDB available.** Copyright (C) 2017 THL A29 Limited, a Tencent company.* All rights reserved.** Licensed under the BSD 3-Clause License (the "License"); you may not use* this file except in compliance with the License. You may obtain a copy of* the License at** https://opensource.org/licenses/BSD-3-Clause** Unless required by applicable law or agreed to in writing, software* distributed under the License is distributed on an "AS IS" BASIS,* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.* See the License for the specific language governing permissions and* limitations under the License.*/#include "fts3_tokenizer.h"
#include "mm_tokenizer.h"
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unicode/ubrk.h>
#include <unicode/unorm.h>
#include <unicode/utf16.h>
#include <unicode/utf8.h>#ifdef _WIN32
#include <malloc.h>
#endif#define ROUND4(n) (((n) + 3) & ~3)typedef struct mm_tokenizer_t mm_tokenizer_t;
typedef struct mm_cursor_t mm_cursor_t;typedef struct mm_tokenizer_t {sqlite3_tokenizer base;char locale[16];
} mm_tokenizer_t;typedef struct mm_cursor_t {sqlite3_tokenizer_cursor base;UBreakIterator *iter; // UBreakIterator for the text.UChar *in_buffer; // whole input text buffer, in UTF-16, // allocated altogather with mm_cursor_t.int *in_offset;int in_length; // input text length.char *out_buffer; // output token buffer, int UTF-8, // allocated in mmtok_next.int out_length; // output token buffer length.int token_count;int32_t ideo_start; // ideographic unary/binary tokenizing cursor.int32_t ideo_end; // ideographic unary/binary tokenizing end point.int ideo_state; // 0 for unary output, -1 for invalid status.
} mm_cursor_t;
#define MINIMAL_OUT_BUFFER_LENGTH 512static char *generate_token_printable_code(const UChar *buf, int32_t length)
{char *out = (char *) malloc(length * 5 + 1);char *pc = out;if (!out)return "";while (length > 0) {_snprintf(pc, 6, "%04hX ", *buf);length--;buf++;pc += 5;}return out;
}static int output_token(mm_cursor_t *cur,int32_t start,int32_t end,const char **ppToken,int *pnBytes,int *piStartOffset,int *piEndOffset,int *piPosition)
{UChar buf1[256];UChar buf2[256];UErrorCode status = U_ZERO_ERROR;int32_t result;int32_t length;length = end - start;if (length > 256)length = 256;result = unorm_normalize(cur->in_buffer + start, length, UNORM_NFKD, 0,buf1, sizeof(buf1) / sizeof(UChar), &status);// currently, only try fixed length buffer, failed if overflowed.if (U_FAILURE(status) || result > sizeof(buf1) / sizeof(UChar)) {char *seq =generate_token_printable_code(cur->in_buffer + start, length);
// sqlite3_mm_set_last_error(
// "Normalize token failed. ICU status: %d, input: %s", status, seq);free(seq);return SQLITE_ERROR;}length = result;result = u_strFoldCase(buf2, sizeof(buf2) / sizeof(UChar), buf1, length,U_FOLD_CASE_DEFAULT, &status);// currently, only try fixed length buffer, failed if overflowed.if (U_FAILURE(status) || result > sizeof(buf2) / sizeof(UChar)) {char *seq = generate_token_printable_code(buf1, length);
// sqlite3_mm_set_last_error(
// "FoldCase token failed. ICU status: %d, input: %s", status, seq);free(seq);return SQLITE_ERROR;}if (cur->out_buffer == NULL) {cur->out_buffer =(char *) sqlite3_malloc(MINIMAL_OUT_BUFFER_LENGTH * sizeof(char));if (!cur->out_buffer)return SQLITE_NOMEM;cur->out_length = MINIMAL_OUT_BUFFER_LENGTH;}length = result;u_strToUTF8(cur->out_buffer, cur->out_length, &result, buf2, length,&status);if (result > cur->out_length) {char *b =(char *) sqlite3_realloc(cur->out_buffer, result * sizeof(char));if (!b)return SQLITE_NOMEM;cur->out_buffer = b;cur->out_length = result;status = U_ZERO_ERROR;u_strToUTF8(cur->out_buffer, cur->out_length, &result, buf2, length,&status);}if (U_FAILURE(status) || result > cur->out_length) {char *seq = generate_token_printable_code(buf2, length);
// sqlite3_mm_set_last_error(
// "Transform token to UTF-8 failed. ICU status: %d, input: %s",
// status, seq);free(seq);return SQLITE_ERROR;}*ppToken = cur->out_buffer;*pnBytes = result;*piStartOffset = cur->in_offset[start];*piEndOffset = cur->in_offset[end];*piPosition = cur->token_count++;return SQLITE_OK;
}static int find_splited_ideo_token(mm_cursor_t *cur, int32_t *start, int32_t *end)
{int32_t s, e;UChar32 c;if (cur->ideo_state < 0)return 0;if (cur->ideo_start == cur->ideo_end) {cur->ideo_state = -1;return 0;}// check UTF-16 surrogates, output 2 UChars if it's a lead surrogates, otherwise 1.s = cur->ideo_start;e = s + 1;c = cur->in_buffer[s];if (U16_IS_LEAD(c) && cur->ideo_end - s >= 2)e++;*start = s;*end = e;cur->ideo_start = e;return 1;
}static int
mmtok_create(int argc, const char *const *argv, sqlite3_tokenizer **ppTokenizer)
{mm_tokenizer_t *tok = (mm_tokenizer_t*)sqlite3_malloc(sizeof(mm_tokenizer_t));if (!tok)return SQLITE_NOMEM;if (argc > 0) {strncpy(tok->locale, argv[0], 15);tok->locale[15] = 0;} elsetok->locale[0] = 0;*ppTokenizer = (sqlite3_tokenizer *) tok;return SQLITE_OK;
}static int mmtok_destroy(sqlite3_tokenizer *pTokenizer)
{mm_tokenizer_t *tok = (mm_tokenizer_t *) pTokenizer;sqlite3_free(tok);return SQLITE_OK;
}static int mmtok_open(sqlite3_tokenizer *pTokenizer,const char *zInput,int nInput,sqlite3_tokenizer_cursor **ppCursor)
{mm_tokenizer_t *tok = (mm_tokenizer_t *) pTokenizer;mm_cursor_t *cur;int i_input;int i_output;int is_error;UErrorCode status = U_ZERO_ERROR;int32_t dst_len;UChar32 c;//__android_log_print(ANDROID_LOG_VERBOSE, "TOKENIZER", "Begin: %s", zInput);if (nInput < 0)nInput = strlen(zInput);dst_len = ROUND4(nInput + 1);cur = (mm_cursor_t *) sqlite3_malloc(sizeof(mm_cursor_t) + dst_len * sizeof(UChar) // in_buffer+ (dst_len + 1) * sizeof(int) // in_offset);if (!cur)return SQLITE_NOMEM;memset(cur, 0, sizeof(mm_cursor_t));cur->in_buffer = (UChar *) &cur[1];cur->in_offset = (int *) &cur->in_buffer[dst_len];cur->out_buffer = NULL;cur->out_length = 0;cur->token_count = 0;cur->ideo_start = -1;cur->ideo_end = -1;cur->ideo_state = -1;i_input = 0;i_output = 0;cur->in_offset[i_output] = i_input;for (;;) {if (i_input >= nInput)break;U8_NEXT(zInput, i_input, nInput, c);if (!c)break;if (c < 0)c = ' ';is_error = 0;U16_APPEND(cur->in_buffer, i_output, dst_len, c, is_error);if (is_error) {sqlite3_free(cur);
// sqlite3_mm_set_last_error(
// "Writing UTF-16 character failed. Code point: 0x%x", c);return SQLITE_ERROR;}cur->in_offset[i_output] = i_input;}cur->iter =ubrk_open(UBRK_WORD, tok->locale, cur->in_buffer, i_output, &status);if (U_FAILURE(status)) {
// sqlite3_mm_set_last_error(
// "Open UBreakIterator failed. ICU error code: %d", status);return SQLITE_ERROR;}cur->in_length = i_output;ubrk_first(cur->iter);*ppCursor = (sqlite3_tokenizer_cursor *) cur;return SQLITE_OK;
}static int mmtok_close(sqlite3_tokenizer_cursor *pCursor)
{mm_cursor_t *cur = (mm_cursor_t *) pCursor;ubrk_close(cur->iter);if (cur->out_buffer)sqlite3_free(cur->out_buffer);sqlite3_free(cur);return SQLITE_OK;
}static int
mmtok_next(sqlite3_tokenizer_cursor *pCursor, // Cursor returned by simpleOpenconst char **ppToken, // OUT: *ppToken is the token textint *pnBytes, // OUT: Number of bytes in tokenint *piStartOffset, // OUT: Starting offset of tokenint *piEndOffset, // OUT: Ending offset of tokenint *piPosition // OUT: Position integer of token)
{mm_cursor_t *cur = (mm_cursor_t *) pCursor;int32_t start, end;int32_t token_type;// process pending ideographic token.if (find_splited_ideo_token(cur, &start, &end))return output_token(cur, start, end, ppToken, pnBytes, piStartOffset,piEndOffset, piPosition);start = ubrk_current(cur->iter);// find first non-NONE token.for (;;) {end = ubrk_next(cur->iter);if (end == UBRK_DONE) {//sqlite3_mm_clear_error();return SQLITE_DONE;}token_type = ubrk_getRuleStatus(cur->iter);if (token_type >= UBRK_WORD_NONE && token_type < UBRK_WORD_NONE_LIMIT) {// look at the first character, if it's a space or ZWSP, ignore this token.// also ignore '*' because sqlite parser uses it as prefix operator.UChar32 c = cur->in_buffer[start];if (c == '*' || c == 0x200b || u_isspace(c)) {start = end;continue;}}break;}// for non-IDEO tokens, just return.if (token_type < UBRK_WORD_IDEO || token_type >= UBRK_WORD_IDEO_LIMIT)return output_token(cur, start, end, ppToken, pnBytes, piStartOffset,piEndOffset, piPosition);// for IDEO tokens, find all suffix ideo tokens.for (;;) {int32_t e = ubrk_next(cur->iter);if (e == UBRK_DONE)break;token_type = ubrk_getRuleStatus(cur->iter);if (token_type < UBRK_WORD_IDEO || token_type >= UBRK_WORD_IDEO_LIMIT)break;end = e;}ubrk_isBoundary(cur->iter, end);cur->ideo_start = start;cur->ideo_end = end;cur->ideo_state = 0;if (find_splited_ideo_token(cur, &start, &end))return output_token(cur, start, end, ppToken, pnBytes, piStartOffset,piEndOffset, piPosition);/* sqlite3_mm_set_last_error("IDEO token found but can't output token.");*/return SQLITE_ERROR;
}static const sqlite3_tokenizer_module mm_tokenizer_module = {0, mmtok_create, mmtok_destroy, mmtok_open, mmtok_close, mmtok_next};int sqlite3_register_mm_tokenizer(sqlite3 *db)
{sqlite3_db_config(db,SQLITE_DBCONFIG_ENABLE_FTS3_TOKENIZER,1,0);const sqlite3_tokenizer_module *module = &mm_tokenizer_module;sqlite3_stmt *stmt = NULL;int result;result =sqlite3_prepare_v2(db, "SELECT fts3_tokenizer(?, ?)", -1, &stmt, 0);if (result != SQLITE_OK)return result;sqlite3_bind_text(stmt, 1, "mmicu", -1, SQLITE_STATIC);sqlite3_bind_blob(stmt, 2, &module, sizeof(sqlite3_tokenizer_module *),SQLITE_STATIC);sqlite3_step(stmt);return sqlite3_finalize(stmt);
}后记
这种用法就是把SQLite编译好后,再另外的工程提供SQLite3相关分词代码,其它工程因为用到分词器进行分词,不得不也链接icu库使用,这显然是有些麻烦的。
当然也有简单的办法,把分词代码整合到SQLite3源码中去,这样外层就直接调用,不用再去理会icu。这部分我自己已经修改好一个将分词源码整合到sqlite.c的工程中,然后再加上加密的工程。这个可以下次介绍该如何做,才能将工程整合。
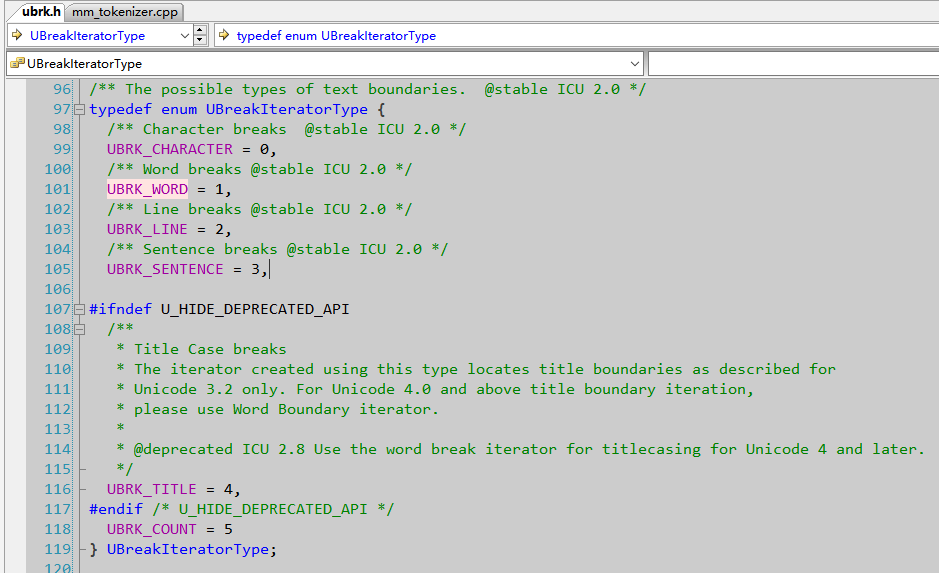
另外,该处可以指定分词级别,这里默认是词组:

这里可以根据自己需要,选择对应分词类型。一般来说,选择UBRK_CHARACTER会查询到的更多。UBRK_WORD对于中文来说,只有成词组的才能搜索到。
本文链接:https://my.lmcjl.com/post/12931.html
4 评论