简介
GPT的发展历程
- GPT-1用的是无监督预训练+有监督微调。
- GPT-2用的是纯无监督预训练。
- GPT-3沿用了GPT-2的纯无监督预训练,但是数据大了好几个量级。
- InstructGPT在GPT-3上用强化学习做微调,内核模型为PPO-ptx
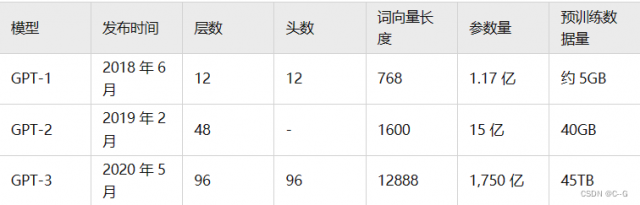
GPT-1比BERT诞生略早几个月。它们都是采用了Transformer为核心结构,不同的是GPT-1通过自左向右生成式的构建预训练任务,然后得到一个通用的预训练模型,这个模型和BERT一样都可用来做下游任务的微调。GPT-1当时在9个NLP任务上取得了SOTA的效果,但GPT-1使用的模型规模和数据量都比较小,这也就促使了GPT-2的诞生
对比GPT-1,GPT-2并未在模型结构上大作文章,只是使用了更多参数的模型和更多的训练数据。GPT-2最重要的思想是提出了“所有的有监督学习都是无监督语言模型的一个子集”的思想,这个思想也是提示学习(Prompt Learning)的前身。
GPT-3被提出时,除了它远超GPT-2的效果外,引起更多讨论的是它1750亿的参数量。GPT-3除了能完成常见的NLP任务外,研究者意外的发现GPT-3在写SQL,JavaScript等语言的代码,进行简单的数学运算上也有不错的表现效果。GPT-3的训练使用了情境学习(In-context Learning),它是元学习(Meta-learning)的一种,元学习的核心思想在于通过少量的数据寻找一个合适的初始化范围,使得模型能够在有限的数据集上快速拟合,并获得不错的效果
指示学习(Instruct Learning)和提示(Prompt Learning)学习
指示学习是谷歌Deepmind的Quoc V.Le团队在2021年的一篇名为《Finetuned Language Models Are Zero-Shot Learners》文章中提出的思想。指示学习和提示学习的目的都是去挖掘语言模型本身具备的知识。不同的是Prompt是激发语言模型的,例如根据上半句生成下半句,或是完形填空等。Instruct是激发语言模型的理解能力,它通过给出更明显的指令,让模型去做出正确的行动。
- 提示学习:给女朋友买了这个项链,她很喜欢,这个项链太____了。
- 指示学习:判断这句话的情感:给女朋友买了这个项链,她很喜欢。选项:A=好;B=一般;C=差。
指示学习的优点是它经过多任务的微调后,也能够在其他任务上做zero-shot,而提示学习都是针对一个任务的。泛化能力不如指示学习。
模型微调
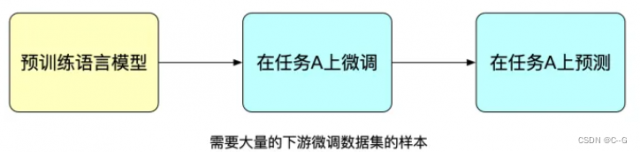
提示学习

指示学习

人工反馈的强化学习
因为训练得到的模型并不是非常可控的,模型可以看做对训练集分布的一个拟合。那么反馈到生成模型中,训练数据的分布便是影响生成内容的质量最重要的一个因素。有时候我们希望模型并不仅仅只受训练数据的影响,而是人为可控的,从而保证生成数据的有用性,真实性和无害性。论文中多次提到了对齐(Alignment)问题,我们可以理解为模型的输出内容和人类喜欢的输出内容的对齐,人类喜欢的不止包括生成内容的流畅性和语法的正确性,还包括生成内容的有用性、真实性和无害性。
我们知道强化学习通过奖励(Reward)机制来指导模型训练,奖励机制可以看做传统模训练机制的损失函数。奖励的计算要比损失函数更灵活和多样(AlphaGO的奖励是对局的胜负),这带来的代价是奖励的计算是不可导的,因此不能直接拿来做反向传播。强化学习的思路是通过对奖励的大量采样来拟合损失函数,从而实现模型的训练。同样人类反馈也是不可导的,那么我们也可以将人工反馈作为强化学习的奖励,基于人工反馈的强化学习便应运而生。
RLHF最早可以追溯到Google在2017年发表的《Deep Reinforcement Learning from Human Preferences》
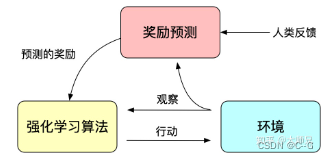
InstructGPT/ChatGPT中还用到了强化学习中一个经典的算法:OpenAI提出的最近策略优化(Proximal Policy Optimization,PPO)。PPO算法是一种新型的Policy Gradient算法,Policy Gradient算法对步长十分敏感,但是又难以选择合适的步长,在训练过程中新旧策略的的变化差异如果过大则不利于学习。PPO提出了新的目标函数可以在多个训练步骤实现小批量的更新,解决了Policy Gradient算法中步长难以确定的问题。其实TRPO也是为了解决这个思想但是相比于TRPO算法PPO算法更容易求解。
InstructGPT
有了上面这些基础知识,我们再去了解InstructGPT和ChatGPT就会简单很多。简单来说,InstructGPT/ChatGPT都是采用了GPT-3的网络结构,通过指示学习构建训练样本来训练一个反应预测内容效果的奖励模型(RM),最后通过这个奖励模型的打分来指导强化学习模型的训练。
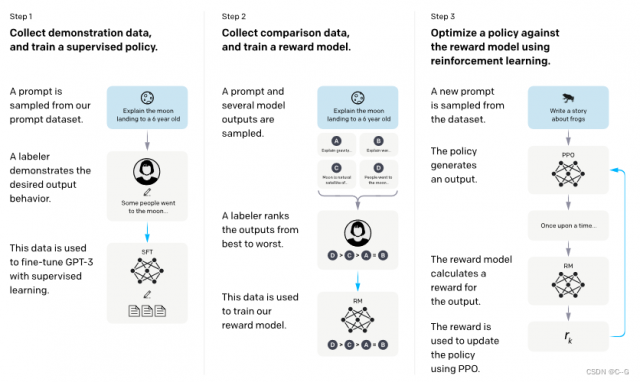
- 工作人员手动标注prompt dataset数据(回答问题),通过这些数据有监督微调GPT-3(Supervised Fine Tune ,SFT)
- 微调过的GPT-3预测prompt dataset,获得一系列结果,让人工根据预测结果进行标注,利用这些标注的结果训练一个奖励模型(Reword Model,RM)
- 使用RM作为强化学习的优化目标,利用PPO算法微调SFT模型
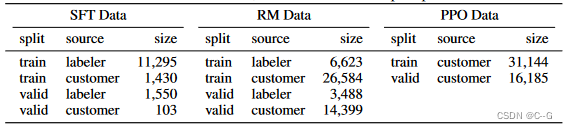
SFT数据集是用来训练第1步有监督的模型,即使用采集的新数据,按照GPT-3的训练方式对GPT-3进行微调。因为GPT-3是一个基于提示学习的生成模型,因此SFT数据集也是由提示-答复对组成的样本。SFT数据一部分来自使用OpenAI的PlayGround的用户,另一部分来自OpenAI雇佣的40名标注工(labeler)。并且他们对labeler进行了培训。在这个数据集中,标注工的工作是根据内容自己编写指示,并且要求编写的指示满足下面三点:
- 简单任务:labeler给出任意一个简单的任务,同时要确保任务的多样性;
- Few-shot任务:labeler给出一个指示,以及该指示的多个查询-相应对;
- 用户相关的:从接口中获取用例,然后让labeler根据这些用例编写指示。
RM数据集用来训练第2步的奖励模型,我们也需要为InstructGPT的训练设置一个奖励目标。这个奖励目标不必可导,但是一定要尽可能全面且真实的对齐我们需要模型生成的内容。很自然的,我们可以通过人工标注的方式来提供这个奖励,通过人工对可以给那些涉及偏见的生成内容更低的分从而鼓励模型不去生成这些人类不喜欢的内容。InstructGPT/ChatGPT的做法是先让模型生成一批候选文本,让后通过labeler根据生成数据的质量对这些生成内容进行排序。
InstructGPT的PPO数据没有进行标注,它均来自GPT-3的API的用户。既又不同用户提供的不同种类的生成任务,其中占比最高的包括生成任务(45.6%),QA(12.4%),头脑风暴(11.2%),对话(8.4%)等。
简历模型(RM)
有监督微调(SFT)的训练和GPT-3一致,而且作者发现让模型适当过拟合有助于后面两步的训练。
因为训练RM的数据是一个labeler根据生成结果排序的形式,所以它可以看做一个回归模型。RM结构是将SFT训练后的模型的最后的嵌入层去掉后的模型。它的输入是prompt和Reponse,输出是奖励值。具体的讲,对弈每个prompt,InstructGPT会随机生成 K个输出(4《 K《 9)
),然后它们向每个labeler成对的展示输出结果,也就是每个prompt共展示 C k 2 C^2_k Ck2 个结果,然后用户从中选择效果更好的输出。在训练时,InstructGPT将每个prompt的 C k 2 C^2_k Ck2 个响应对作为一个batch,这种按prompt为batch的训练方式要比传统的按样本为batch的方式更不容易过拟合,因为这种方式每个prompt会且仅会输入到模型中一次。
奖励模型的损失函数的目标是最大化labeler更喜欢的响应和不喜欢的响应之间的差值。
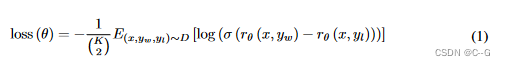
r θ ( x , y ) r_{\theta}(x,y) rθ(x,y)是提示 x 和 响应 y 在参数为 θ \theta θ 的奖励模式下的奖励值, y w y_w yw 是labeler 更喜欢的响应结果, y l y_l yl 是label不喜欢的响应结果。D 是整个训练数据集
强化学习模型(PPO)
强化学习和预训练模型是最近两年最为火热的AI方向之二,之前不少科研工作者说强化学习并不是一个非常适合应用到预训练模型中,因为很难通过模型的输出内容建立奖励机制。而InstructGPT/ChatGPT反直觉的做到了这点,它通过结合人工标注,将强化学习引入到预训练语言模型是这个算法最大的创新点。
PPO的训练集完全来自API。它通过第2步得到的奖励模型来指导SFT模型的继续训练。很多时候强化学习是非常难训练的
InstructGPT在训练过程中就遇到了两个问题:
- 问题1:随着模型的更新,强化学习模型产生的数据和训练奖励模型的数据的差异会越来越大。作者的解决方案是在损失函数中加入KL惩罚项 β l o g ( π ϕ R L ( y ∣ x ) / π S F T ( y ∣ x ) ) \beta log(\pi^{RL}_{\phi}(y|x)/\pi^{SFT}(y|x)) βlog(πϕRL(y∣x)/πSFT(y∣x)) 来确保 PPO模型的输出和SFT的输出差距不会很大
- 问题2:只用PPO模型进行训练的话,会导致模型在通用NLP任务上性能的大幅下降,作者的解决方案是在训练目标中加入了通用的语言模型目标 γ E x D p r e t r a i n [ l o g ( π ϕ R L ( x ) ) ] \gamma E_x~D_{pretrain} [log(\pi^{RL}_{\phi}(x))] γEx Dpretrain[log(πϕRL(x))] ,当 γ \gamma γ 不为0,则称为PPO-ptx
因此PPO的训练目标式为:
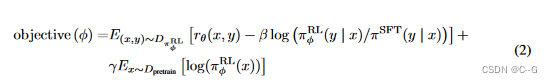
优点
InstructGPT/ChatGPT的效果比GPT-3更加真实:这个很好理解,因为GPT-3本身就具有非常强的泛化能力和生成能力,再加上InstructGPT/ChatGPT引入了不同的labeler进行提示编写和生成结果排序,而且还是在GPT-3之上进行的微调,这使得我们在训练奖励模型时对更加真实的数据会有更高的奖励。作者也在TruthfulQA数据集上对比了它们和GPT-3的效果,实验结果表明甚至13亿小尺寸的PPO-ptx的效果也要比GPT-3要好。
InstructGPT/ChatGPT在模型的无害性上比GPT-3效果要有些许提升:原理同上。但是作者发现InstructGPT在歧视、偏见等数据集上并没有明显的提升。这是因为GPT-3本身就是一个效果非常好的模型,它生成带有有害、歧视、偏见等情况的有问题样本的概率本身就会很低。仅仅通过40个labeler采集和标注的数据很可能无法对模型在这些方面进行充分的优化,所以会带来模型效果的提升很少或者无法察觉。
InstructGPT/ChatGPT具有很强的Coding能力:首先GPT-3就具有很强的Coding能力,基于GPT-3制作的API也积累了大量的Coding代码。而且也有部分OpenAI的内部员工参与了数据采集工作。通过Coding相关的大量数据以及人工标注,训练出来的InstructGPT/ChatGPT具有非常强的Coding能力也就不意外了。
缺点
InstructGPT/ChatGPT会降低模型在通用NLP任务上的效果:我们在PPO的训练的时候讨论了这点,虽然修改损失函数可以缓和,但这个问题并没有得到彻底解决。
有时候InstructGPT/ChatGPT会给出一些荒谬的输出:虽然InstructGPT/ChatGPT使用了人类反馈,但限于人力资源有限。影响模型效果最大的还是有监督的语言模型任务,人类只是起到了纠正作用。所以很有可能受限于纠正数据的有限,或是有监督任务的误导(只考虑模型的输出,没考虑人类想要什么),导致它生成内容的不真实。就像一个学生,虽然有老师对他指导,但也不能确定学生可以学会所有知识点。
模型对指示非常敏感:这个也可以归结为labeler标注的数据量不够,因为指示是模型产生输出的唯一线索,如果指示的数量和种类训练的不充分的话,就可能会让模型存在这个问题。
模型对简单概念的过分解读:这可能是因为labeler在进行生成内容的比较时,倾向于给给长的输出内容更高的奖励。
对有害的指示可能会输出有害的答复:例如InstructGPT也会对用户提出的“AI毁灭人类计划书”给出行动方案。这个是因为InstructGPT假设labeler编写的指示是合理且价值观正确的,并没有对用户给出的指示做更详细的判断,从而会导致模型会对任意输入都给出答复。虽然后面的奖励模型可能会给这类输出较低的奖励值,但模型在生成文本时,不仅要考虑模型的价值观,也要考虑生成内容和指示的匹配度,有时候生成一些价值观有问题的输出也是可能的。
原文参考于:https://zhuanlan.zhihu.com/p/590311003
本文链接:https://my.lmcjl.com/post/19761.html
4 评论