CPU三级缓存和缓存行的概念(并发可见性)
- 什么是三级缓存
- 为什么需要三级缓存
- 缓存块(行)的概念
- 程序局部性原理
- cpu cache 读取过程
- 缓存行读多大?
- 如何写出让cpu跑的更快的代码
- 结合并发可见性的总结
什么是三级缓存
cpu存取数据大致可以认为是下图的流程
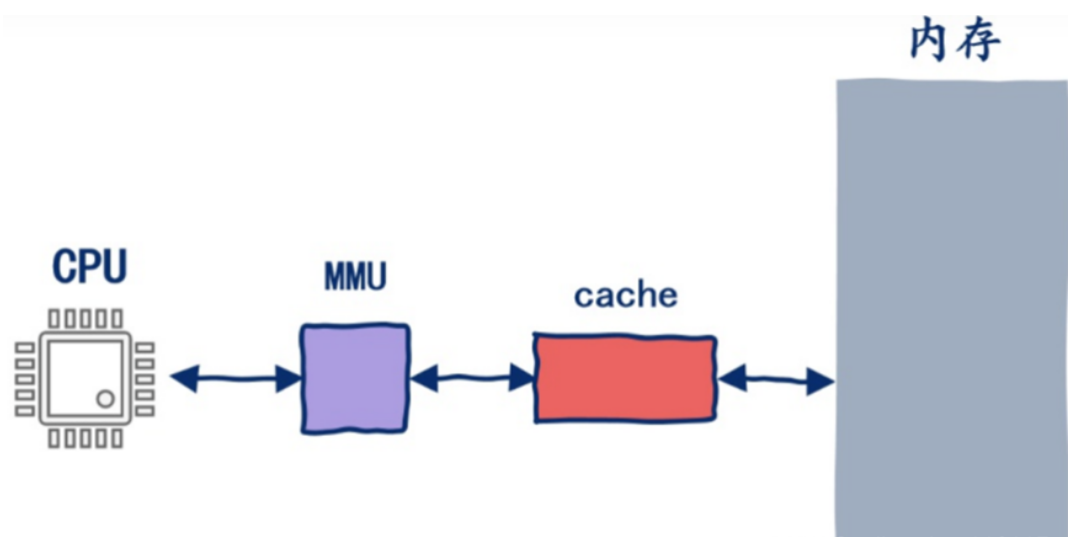
cpu拿到需要的内存地址,之后这个地址会被mmu转换成真正的物理地址,接下来会去查接下来查L1 cache,L1 cache不命中查L2 cache,L2 cache不命中查L3 cache,L3 cache不能命中查内存。
为什么需要三级缓存
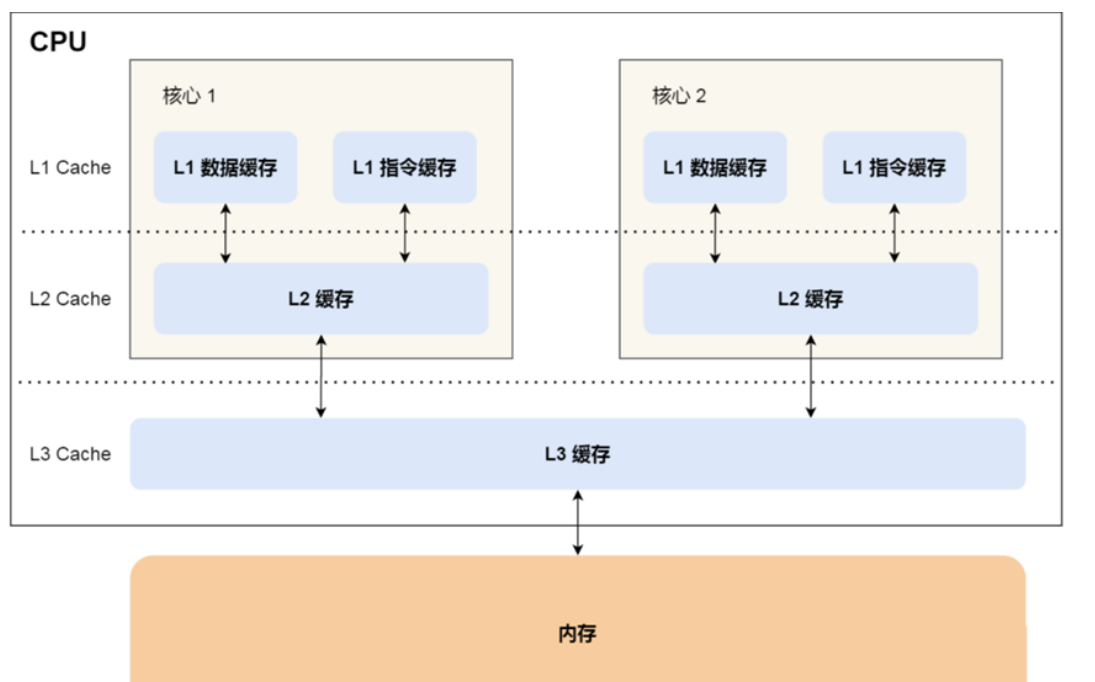
为了弥补 CPU 与内存两者之间的性能差异,就在 CPU 内部引入了 CPU Cache,也称高速缓存。CPU Cache 通常分为大小不等的三级缓存,分别是 L1 Cache、L2 Cache 和 L3 Cache。其中L3是多个核心共享的。程序执行时,会先将内存中的数据加载到共享的 L3 Cache 中,再加载到每个核心独有的 L2 Cache,最后 进入到最快的 L1 Cache,之后才会被 CPU 读取。之间的层级关系,如下图。
缓存块(行)的概念
程序局部性原理
如果访问内存中的一个数据A,那么很有可能接下来再次访问到,同时还很有可能访问与数据A相邻的数据B,这分别叫做时间局部性和空间局部性。
cpu cache 读取过程
CPU Cache 的数据是从内存中读取过来的,以一小块一小块读取数据的,而不是按照单个数组元素来读取数据的,在 CPU Cache 中的,这样一小块一小块的数据,称为 Cache Line(缓存块)。
缓存行读多大?
一个缓存行64个字节
如何写出让cpu跑的更快的代码
其实,这个问题定义为如何提高cpu缓存利用率更好,我们来看以下的代码程序,定义一个数组arr,容量为大小为2来存放long类型的变量X,写两个线程t1和t2,循环变更数组arr[0]和arr[1]的值1000_0000L次,然后计算其所花费的时间。
public class T01_CacheLinePadding {private static class T {public volatile long x = 0L;}public static T[] arr = new T[2];static {arr[0] = new T();arr[1] = new T();}public static void main(String[] args) throws Exception {Thread t1 = new Thread(()->{for (long i = 0; i < 1000_0000L; i++) {arr[0].x = i;}});Thread t2 = new Thread(()->{for (long i = 0; i < 1000_0000L; i++) {arr[1].x = i;}});final long start = System.nanoTime();t1.start();t2.start();t1.join();t2.join();System.out.println((System.nanoTime() - start)/100_0000);}
执行结果为
200
现在我们将程序代码修改一下:
public class T02_CacheLinePadding {private static class Padding {public volatile long p1, p2, p3, p4, p5, p6, p7;}private static class T extends Padding {public volatile long x = 0L;}public static T[] arr = new T[2];static {arr[0] = new T();arr[1] = new T();}public static void main(String[] args) throws Exception {Thread t1 = new Thread(()->{for (long i = 0; i < 1000_0000L; i++) {arr[0].x = i;}});Thread t2 = new Thread(()->{for (long i = 0; i < 1000_0000L; i++) {arr[1].x = i;}});final long start = System.nanoTime();t1.start();t2.start();t1.join();t2.join();System.out.println((System.nanoTime() - start)/100_0000);}
}执行结果为
83
我们发现同样是处理1000_0000L次,后面的代码执行效率明显比前面的快,这是为什么呢?下面我们来仔细分析下:
前面我们提到了缓存行的概念,缓存行的大小为64个字节,一个long值在内存中占用8个字节,那么我们后一段代码中通过父子类定义了8个long类型的变量,正好占用内存64个字节大小,根据空间局部性原理,从主存是按块读取数据进缓存,这一块就叫缓存行,一个缓存行是64字节 根据缓存一致性协议,如果两个线程修改的内容存在于一个缓存行的话,会互相干扰,影响效率, 所以可以前后各填充一定的空来保证有效数据一定在独立的缓存行来提升效率 。
结合并发可见性的总结
可见性:
1)线程开始时会从主内存将数据读到缓存中,如果不是线程可见的话,此线程不会读到其他线程对数据的更改
2)对数据加上volatile修饰,即可达到线程可见,各线程会立即读到对数据的更改
3)如果volatile修饰引用类型,则引用的内部字段不能保证线程可见
4)缓存行:根据空间局部性原理,从主存是按块读取数据进缓存,这一块就叫缓存行,一个缓存行是64字节 根据缓存一致性协议,如果两个线程修改的内容存在于一个缓存行的话,会互相干扰,影响效率, 所以可以前后各填充一定的空来保证有效数据一定在独立的缓存行来提升效率
5)jdk1.8中注解@contended保证它修饰的变量独占缓存行,前提是关闭jvm对它的限制RestrictContended。
6)缓存行越大、局部空间效率越高、但读取时间越慢,缓存行越小、局部空间效率月底,但读取时间越快
本文链接:https://my.lmcjl.com/post/8395.html
4 评论