ChatGPT 串接 Firebase,實現上下文歷史紀錄
在使用 ChatGPT API 時,因為 API 本身是「一次性」,無法儲存聊天的歷史紀錄,這也衍生了「無法串聯上下文」的問題,不過如果將 ChatGPT 串連 Firebase 的 Realtime database,就能夠做到在與 ChatGPT 聊天時,即時透過資料庫記錄上下文的內容,這篇教學會介紹相關的做法。
建立與設定 Firebase Realtime database
參考「建立 Firebase RealTime Database」教學,建立一個 Firebase Realtime database。
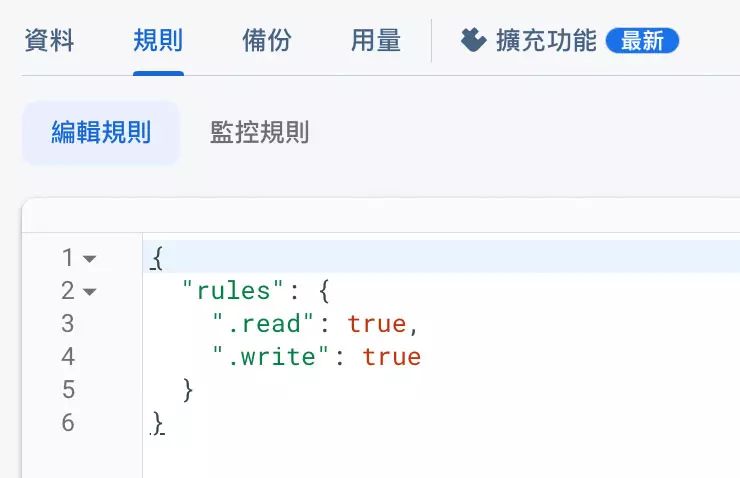
參考「設定 Firebase RealTime Database 安全規則」教學,將讀取和寫入的規則都設為 true。
參考「串接 Firebase RealTime Database 存取資料」教學,安裝 Python 的 firebase 函式庫。
pip install git+https://github.com/ozgur/python-firebase
ChatGPT 使用 text-davinci-003 模型
參考「ChatCPT 串連上下文語句」教學中的 text-davinci-003 模型範例,加入 Firebase Realtime database 儲存對話紀錄,如此一來就能在再次開啟時,記得上一次所講的對話。
import openai
openai.api_key = '你的 API Key'from firebase import firebase
url = 'https://XXXXXXXXX.firebaseio.com'
fdb = firebase.FirebaseApplication(url, None) # 初始化 Firebase Realtime database
chatgpt = fdb.get('/','chatgpt') # 取的 chatgpt 節點的資料if chatgpt == None:messages = '' # 如果節點沒有資料,訊息內容設定為空
else:messages = chatgpt # 如果節點有資料,使用該資料作為歷史聊天記錄while True:msg = input('me > ')if msg == '!reset':message = ''fdb.delete('/','chatgpt') # 如果輸入 !reset 就清空歷史紀錄print('ai > 對話歷史紀錄已經清空!')else:messages = f'{messages}{msg}\n' # 在輸入的訊息前方加上歷史紀錄response = openai.Completion.create(model='text-davinci-003',prompt=messages,max_tokens=128,temperature=0.5)ai_msg = response['choices'][0]['text'].replace('\n','') # 取得 ChatGPT 的回應print('ai > '+ai_msg)messages = f'{messages}\n{ai_msg}\n\n' # 在訊息中加入 ChatGPT 的回應fdb.put('/','chatgpt',messages) # 更新資料庫資料
執行程式後,就算重新啟動程式,ChatGPT 也會記得過去的聊天內容 ( 例如說還記得名字 )

進入 Firebase Realtime database 也能看到歷史紀錄的資料。

ChatGPT 使用 gpt-3.5-turbo 模型
參考「ChatCPT 串連上下文語句」教學中的 gpt-3.5-turbo3 模型範例,加入 Firebase Realtime database 儲存對話紀錄,如此一來就能在再次開啟時,記得上一次所講的對話。
import openai
openai.api_key = '你的 API Key'from firebase import firebase
url = 'https://XXXXXXXXXXX.firebaseio.com'
fdb = firebase.FirebaseApplication(url, None) # 初始化 Firebase Realtimr database
chatgpt = fdb.get('/','chatgpt') # 讀取 chatgpt 節點中所有的資料if chatgpt == None:messages = [] # 如果沒有資料,預設訊息為空串列
else:messages = chatgpt # 如果有資料,訊息設定為該資料while True:msg = input('me > ')if msg == '!reset':fdb.delete('/','chatgpt') # 如果輸入 !reset 就清空 chatgpt 的節點內容messages = []print('ai > 對話歷史紀錄已經清空!')else:messages.append({"role":"user","content":msg}) # 將輸入的訊息加入歷史紀錄的串列中response = openai.ChatCompletion.create(model="gpt-3.5-turbo",max_tokens=128,temperature=0.5,messages=messages)ai_msg = response.choices[0].message.content.replace('\n','') # 取得回應訊息messages.append({"role":"assistant","content":ai_msg}) # 將回應訊息加入歷史紀錄串列中fdb.put('/','chatgpt',messages) # 更新 chatgpt 節點內容print(f'ai > {ai_msg}')
執行程式後,就算重新啟動程式,ChatGPT 也會記得過去的聊天內容 ( 例如說還記得名字 )
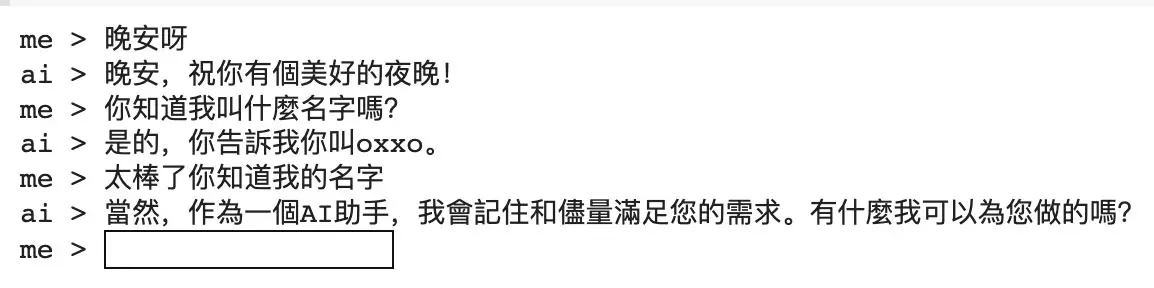
進入 Firebase Realtime database 也能看到歷史紀錄的資料。

小結
透過 Firebase Realtime database,就能非常方便快速地儲存 ChatGPT 的聊天記錄,並讓 ChatGPT 能夠分辨上下文,是相當不錯的功能!但仍然要注意的是,回傳歷史紀錄會造成 ChatGPT 的 token 數量暴增,一但超過免費額度就要開始收費囉。
文章摘自ChatGPT 串接 Firebase,實現上下文歷史紀錄 - Python 教學 | STEAM 教育學習網
本文链接:https://my.lmcjl.com/post/9058.html
4 评论