爬取目标站点分析 本次采集的目标站点为:https://www.zaih.com/falcon/mentors,目标数据为在行高手数据。 本次数据保存到 MySQL 数据库中,基于目标数据,设计表结构如下所示。 对比表结构,可以直接将 scrapy 中的 items.py 文件编写完毕。 class ZaihangItem(scrapy.Item): # define the fields for your item he 继续阅读
python实战项目scrapy管道学习爬取在行高手数据
查询到最新的12条
爬取目标站点分析 本次采集的目标站点为:https://www.zaih.com/falcon/mentors,目标数据为在行高手数据。 本次数据保存到 MySQL 数据库中,基于目标数据,设计表结构如下所示。 对比表结构,可以直接将 scrapy 中的 items.py 文件编写完毕。 class ZaihangItem(scrapy.Item): # define the fields for your item he 继续阅读
这本Python网络数据爬取及分析从入门到精通(分析篇)图书,是2018-06-01月由北京航空航天大学出版社所出版的,著作者信息: 杨秀璋,颜娜 著,本版是第1次印刷, ISBN:9787512427136,品牌:北京航空航天大学出版社, 这本书的包装是小全开平装,所用纸张为胶版纸,全书页数未知,字数有万字, 是本值得推荐的Python软件开发图书。此书内容摘要Python网络数据爬取及分析从入门到精通(分析篇)本书采用通俗易懂的语言、丰富多彩的实例,详细介绍了使用Python语言进行网络数据 继续阅读
一、前言 本文是对2020年亚太数学建模竞赛B题:美国总统候选人对美国和中国的经济影响分析的解题思路,希望能够对正在学习数学建模或者研究该类问题的读者提供帮助。 本解题思路为中文版,由于亚太杯本为纯英文数学建模竞赛,后续会更新英文版内容,受限于本人英文水平,该篇文章的问题背景和具体问题部分为机翻,请见谅。 二、问题背景 美国总统选举每四年举 继续阅读
一、思路 最近做了一个网站用到了从网址爬取天猫和淘宝的商品信息,首先看了下手机端的网页发现用的react,不太了解没法搞,所以就考虑从PC入口爬取数据,但是当爬取URL获取数据时并没有获取价格,库存等的信息,仔细研究了下发现是异步请求了另一个接口,但是接口要使用refer才能获取数据,于是就通过以下方式写了一个简单的爬虫,用于爬取商品预览图和商品的第一个分类的价格、库存等。 二、实现 代码如下: php;" > function crawlUrl($url){ impor 继续阅读
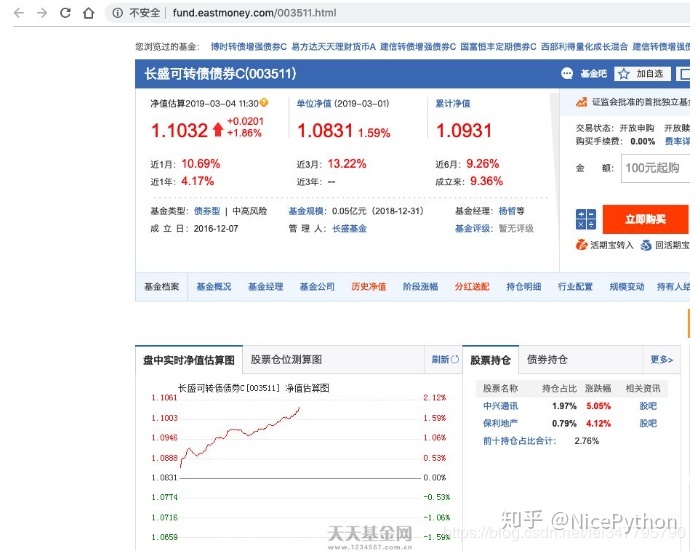
接口分析爬数据需要先思考从哪里爬?经过一番搜索和考虑,我发现天天基金网的数据既比较全,又十分容易爬取,所以就从它入手了。首先,随便点开一支基金,我们可以看到域名就是该基金的代码,十分方便,其次下面有生成的净值图。 基金详情打开chrome的开发者调试,选择Network,然后刷新一下,很快我们就能发现我们想要的东西了。可以看到,这 继续阅读
近日,由湖南省人民政府、工业和信息化部主办的 2019 世界计算机大会在湖南长沙举行。大会以「计算万物 湘约未来」为主题,邀请国内外行业专家学者、企业家汇聚一堂,共同探讨计算技术产业发展之路,是我国计算机产业领域规格最高、规模最大的专业性盛会。 会议期间,由大数据产业生态联盟联合赛迪顾问共同编制的《2019 中国大数据产业发展白皮书》在「计算机未来:算力驱动万物互联」主题论坛上隆重发布,并揭晓了「 继续阅读
Python是一门高级编程语言,一般情况下它可以完成多种不同类型的编程任务,包括Web开发,数据科学等等领域。而在美国队长这个银幕英雄的角色中,他的角色的工资是一个很重要的话题。那么,我们可以从以下几个方向来详细阐述Python美国队长工资的情况。 一、工作职责 按照电影内容中美国队长的职责来讲,他是一位超级英雄,需要拯救世界免遭各种火灾、洪水、外星人和疯狂的科学家等各种威胁。在实际情况中,能够胜任这种工作的人才是真正的牛人,因为这不仅需要他们具备超凡的身体素 继续阅读
编程书籍推荐:解析Python网络爬虫:核心技术、Scrapy框架、分布式爬虫,由中国铁道出版社2018-08-01月出版,本书发行作者信息: 黑马程序员 著此次为第1次发行, 国际标准书号为:9787113246785,品牌为中国铁道出版社, 这本书采用平装开本为16开,附件信息:未知,纸张采为胶版纸,全书共有272页字数万 字,值得推荐的Python Book。此书内容摘要 网络爬虫是一种按照一定的规则,自动请求万维网网站并提取网络数据的程序或脚本,它可以代替人 继续阅读

数据智能产业创新服务媒体——聚焦数智 · 改变商业要说2023年互联网行业最火爆的概念,ChatGPT绝对当仁不让。国外有微软,国内有百度、阿里、商汤、三六零等,各大互联网巨头都对这个概念青睐有加。众多企业纷纷宣布投身赛道,誓要做出属于自己的ChatGPT。然而,在如此追捧之下,已经有不少人开始翻车,蹭热点似乎也并非想象般的那样美好,昆仑万维就是一个活生生的例子。ChatGPT谁蹭谁 继续阅读
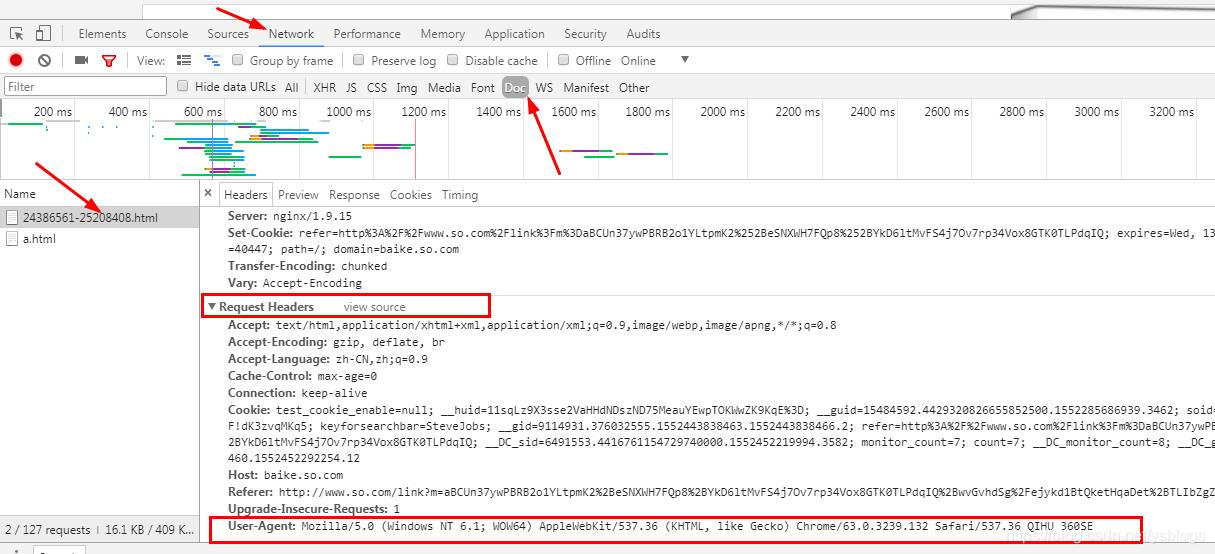
1、为什么要设置headers? 在请求网页爬取的时候,输出的text信息中会出现抱歉,无法访问等字眼,这就是禁止爬取,需要通过反爬机制去解决这个问题。 headers是解决requests请求反爬的方法之一,相当于我们进去这个网页的服务器本身,假装自己本身在爬取数据。 对反爬虫网页,可以设置一些headers信息,模拟成浏览器取访问网站 。 2、 headers在哪里找? 谷歌或者火狐浏览器,在网页面上点击:右键–> 继续阅读

目录 安装方法 使用说明 支持示例展示 水平条形图 垂直条形图比赛 条形图 饼图 多边形地理空间图 多个图表 总结 数据动画可视化制作在日常工作中是非常实用的一项技能。目前支持动画可视化 继续阅读
Python数据分析师修炼之道这本书,是由清华大学出版社在2019-06-01月出版的,本书著作者是 [美] 阿尔瓦罗·富恩特斯 著,刘璋 译,此次本版是第1次印刷发行, 国际标准书号(ISBN):9787302530169,品牌为清华大学出版社(TSINGHUA UNIVERSITY PRESS), 这本书的包装是16开平装,所用纸张为胶版纸,全书共有122页字数16万8000字, 是一本非常不错的Python编程书籍。此书内容摘要本书详细阐述了与Python数据分析相 继续阅读