1. 背景
在2022年11月中旬,chatgpt这个问答AI开始爆火,由于chatgpt目前仅限于官网网页版访问使用,登录也麻烦。于是有些作者在解析网页后做了可供第三方使用的插件等等,但是这一切在12月13日OpenAI官方加了cf认证后基本告一段落。因此,有些作者转而使用官网提供的低配版chatgpt,也就是用text-davinci-003模型代替的弱化版chatgpt,而OpenAI官网提供了对text-davinci-003模型的接口。
2 接口使用简述
一般情况下,其回答质量还是蛮高的。不过也不应该盲目的相信ChatGPT的回答:另外需要说明的是,虽然OpenAI注册和使用不支持中国地区,但是不意味着不支持中文,如果你用中文提问,那么ChatGPT将用中文回答你,对于其他语言也是同样。
2.1 接口使用简述
1、接口鉴权
使用http Authorization头进行鉴权,值为:申请的接口 keys。对于接口 keys的管理官方的描述是:
2、参数描述
- model :使用什么模型。
- prompt :上下文内容。
- temperature :字面意思是温度,作用是影响回答的“热”度,值越低回答的越准备和客观,官方的建议值是0.5 -1,我认为还是直接给0为好。
- max_tokens:最大Token,官方默认值为2048,首先关于Token我最初的理解是类比词法分析中的Token(之前写了一个demo,里面涉及了分词:《遵循编译原理主要过程实现“打印1+1结果”》https://blog.csdn.net/camelials/article/details/123415475),不过从官方的介绍上来看,这样理解没有问题。需要说明的是该字段影响回答的饱满度,即回答的内容长度不超过该设置。后面我会简单介绍计费相关,最后你一点会觉得:先聊十块钱的,然后发现十块钱不够聊的。因为一次请求所花费的Token数量可不单单只是回答所消耗的Token还有prompt所消耗的Token。
此外,请求参数还有一些可选参数,例如:n,默认为1,如果设置为2则每次可以得到2个回答。即,choices数组的length为2。
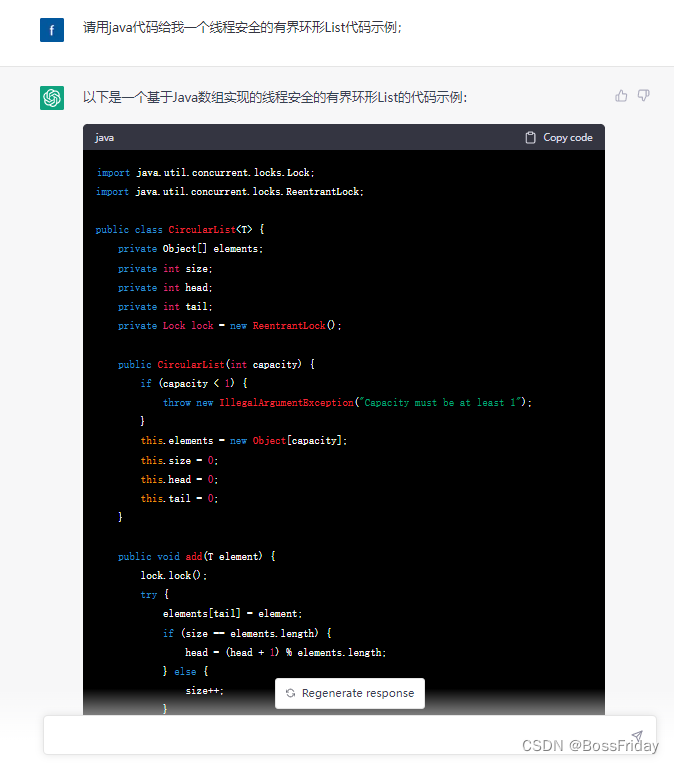
2.2 如何关联上下文
从上面我贴的接口请求/响应的示例中我们可以看出:好像没有什么地方可以表达会话信息。那么如何使用接口如何串联上下文呢?由于没有快速找到相关说明,于是我直接问了ChatGPT自己,得到的答复是:
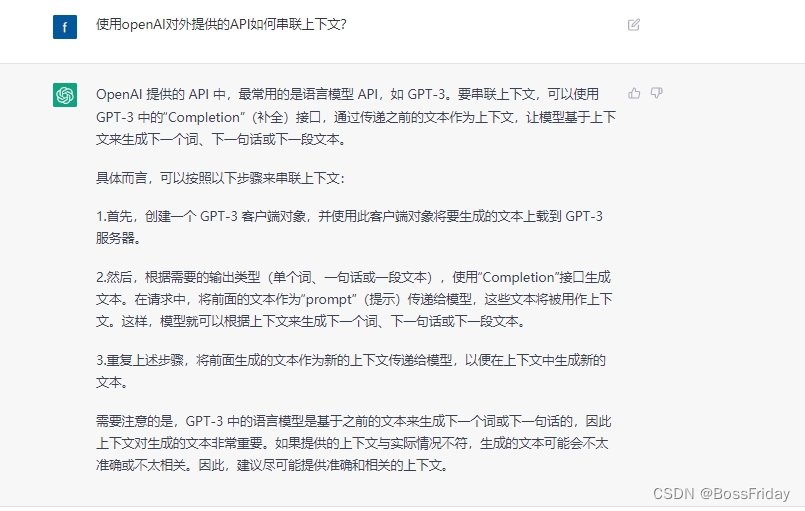
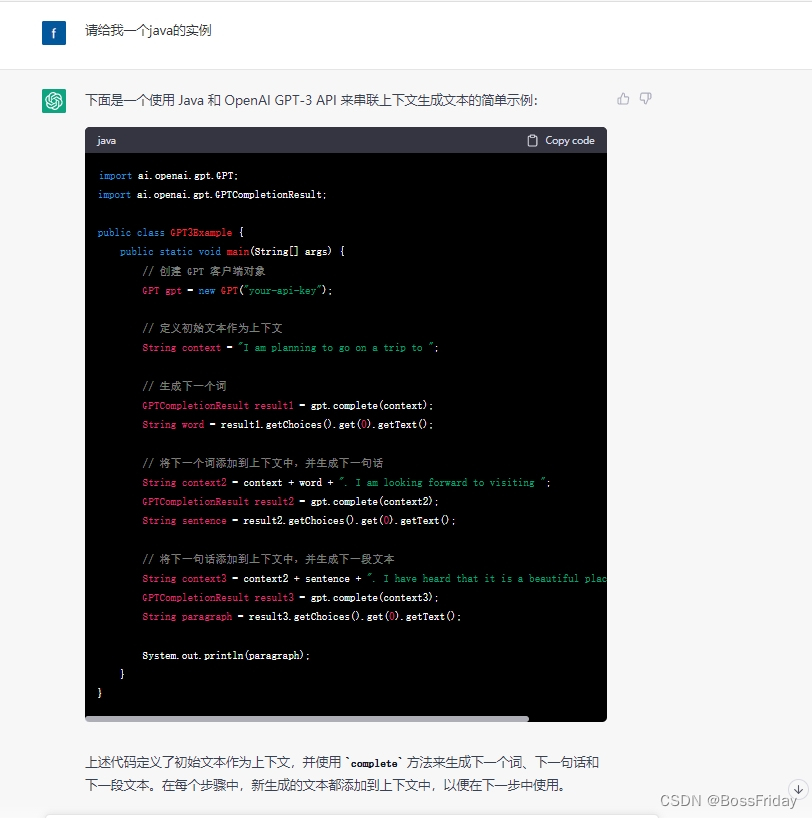
上面的文字回答可能有些地方存在二意性,于是我接着直接让chatGPT给出java代码。从下面的代码就能看出:串联上下文其实就是简单暴力的将前面的问答内容不断的累加到后面的问题中
3 接口计费
官方计费说明简单来说:按照token计费,1000token大约750个单词,当然这里说的英文单词而不是中文。
3.1 计费明细
3.1.1 图片模型计费明细

3.1.2 语言模型计费明细
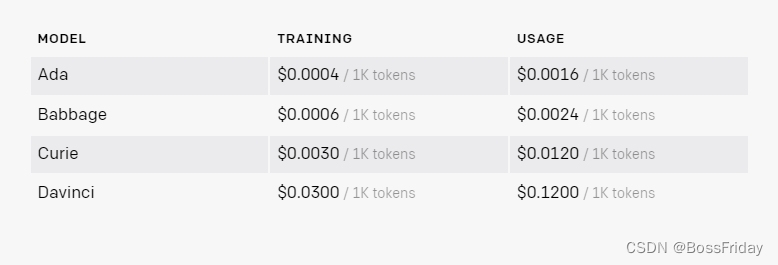
咋一看,感觉便宜,但是你想想:
- 1、现在只能使用text-davinci-003模型,0.12刀/k tokens;
- 2、前面我说的max_tokens参数用途,如果想要详尽的回答,这个值不能限的较小吧?
- 3、前面说的如何串联上下文只能是简单暴力的将前面的问答内容不断的累加到后面的问题中。
结合这3点,是不是觉得: 不差钱,先聊十块钱的,然后发现十块钱不够聊的? 因此,从基于ChatGPT应用的产品和技术层面上来说以下两点是需要首先注意的问题:
- 不能无限制的支持上下文关联,个人认为只支持单位时间里有限数量的会话关联为好,例如:只关联最近5分钟里的最多10条对话上下文。
- 动态控制max_tokens的给值,当然目前我并不能给出较好的解决方案,好像基于提出的问题内容本身,目前难以提前知晓其回答的内容的多与少,如果能知道那么其实我自己的系统也可以算是具备了chatGPT的某些能力,这显然是不现实的。当然,这块的处理如果没有好的解决方案那么就静态的给官方建议值:2048。
本文链接:https://my.lmcjl.com/post/5840.html
4 评论