深度学习实例分割篇——Mask RCNN原理详解篇
写在前面
在前面的文章中,我已经为大家介绍过深度学习中的物体分类、目标检测和语义分割,感兴趣的可以进入我的主页了解详情。我尽量通俗的为大家介绍各种网络结构原理,并配合代码帮助大家深入理解,感兴趣的快来和我一起学习吧,让我们共同进步。🥂🥂🥂
今天为大家讲解Mask RCNN的原理,在阅读本教程之前,有些知识你是必须掌握的,如下:
- [1] 目标检测系列——开山之作RCNN原理详解 🍁🍁🍁
- [2] 目标检测系列——Fast R-CNN原理详解 🍁🍁🍁
- [3] 目标检测系列——Faster R-CNN原理详解 🍁🍁🍁
- [4] 还不懂目标检测嘛?一起来看看Faster R-CNN源码解读 🍁🍁🍁
- [5] 深度学习语义分割篇——FCN原理详解篇 🍁🍁🍁
- [6]深度学习语义分割篇——FCN源码解析篇 🍁🍁🍁
Mask RCNN是在Faster RCNN的基础上提出的,因此你需要对Faster RCNN的结构相当了解,不清楚的可以参考上述的[1]-[4]。同时Mask RCNN中又嵌入了FCN语义分割模块,因此你也要对此有充分认知,不清楚的可以参考[5]和[6]。
那么现在我就当大家已经有了以上的先验知识,快来和我一起学学Mask RCNN吧!🚖🚖🚖
Mask RCNN总体框架
Mask RCNN的网络结构如下图所示,我们先从宏观上认识一下Mask RCNN的整体结构。其主要分为两个部分,下图中黄框框住的部分为Faster RCNN结构,绿框框住的是一个FCN结构。也就是说,Mask RCNN是在Faster RCNN的基础上添加了一个FCN结构!!!
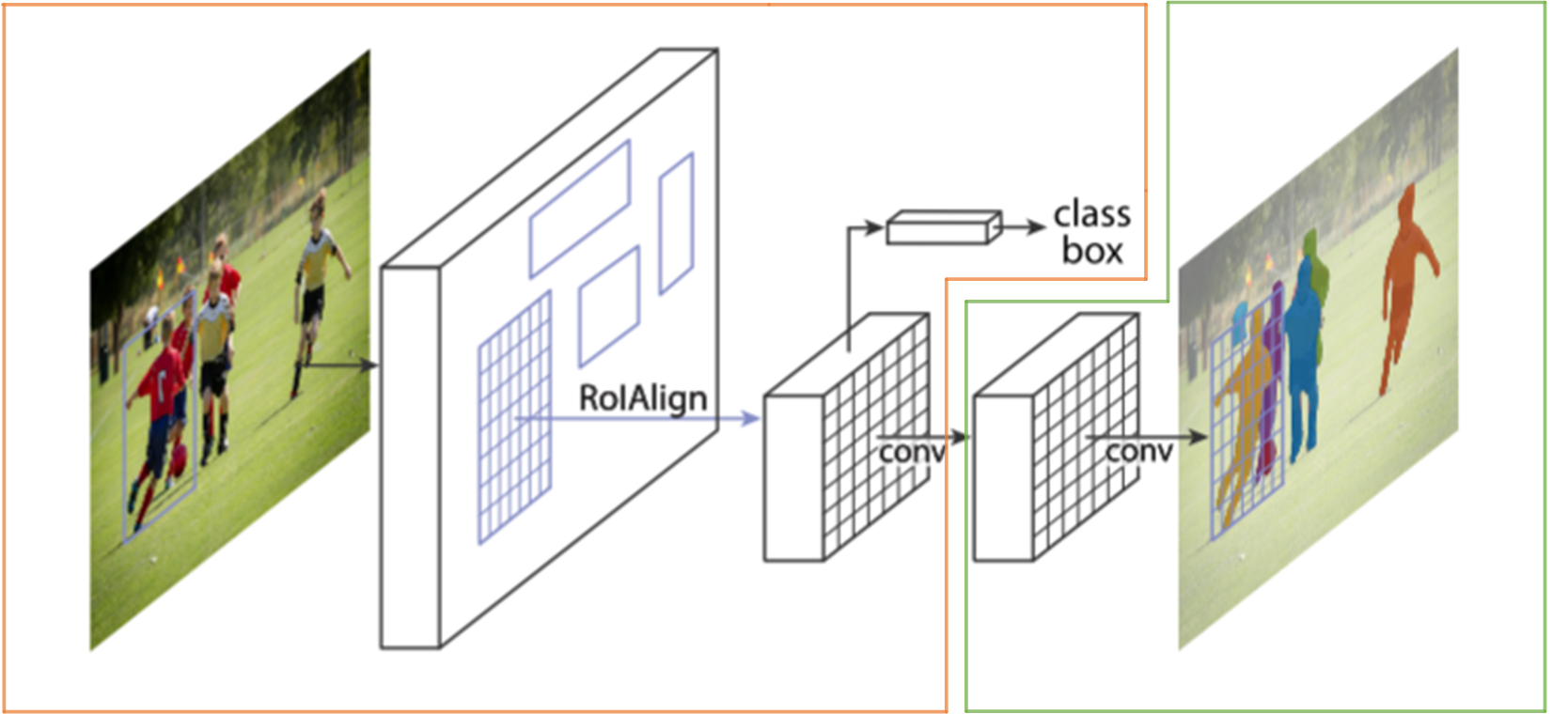
图1 Mask RCNN整体框架图
是的,Mask RCNN的结构就是这么简单,却能起到非常好的效果。而且可扩展行非常好,比如我们还添加一个可以检测人体关键点信息的网络。在介绍Mask RCNN的一些细节前,让我们先来看看Mask RCNN的效果吧。

图2 实例分割效果图

图3 关键点检测效果图
Mask RCNN细节梳理
我们先以下图来介绍一下Mask RCNN的整体流程。首先对于一张输入图片,我们先将其经过特征提取骨干网络得到特征图,然后将特征图送入RPN网络得到一系列候选框,接着利用刚刚得到的候选框,剪裁出候选框对应特征图的部分,然后送入ROI Align层【大家先当成ROI Pooling即可,后文详细介绍】 获得尺寸一致的特征图,然后分别送入分支①(class、box分支)和分支②(Mask分支),分支①用于获取图像中物体的位置和类别信息,分支②用于获取图像中物体的分割信息。
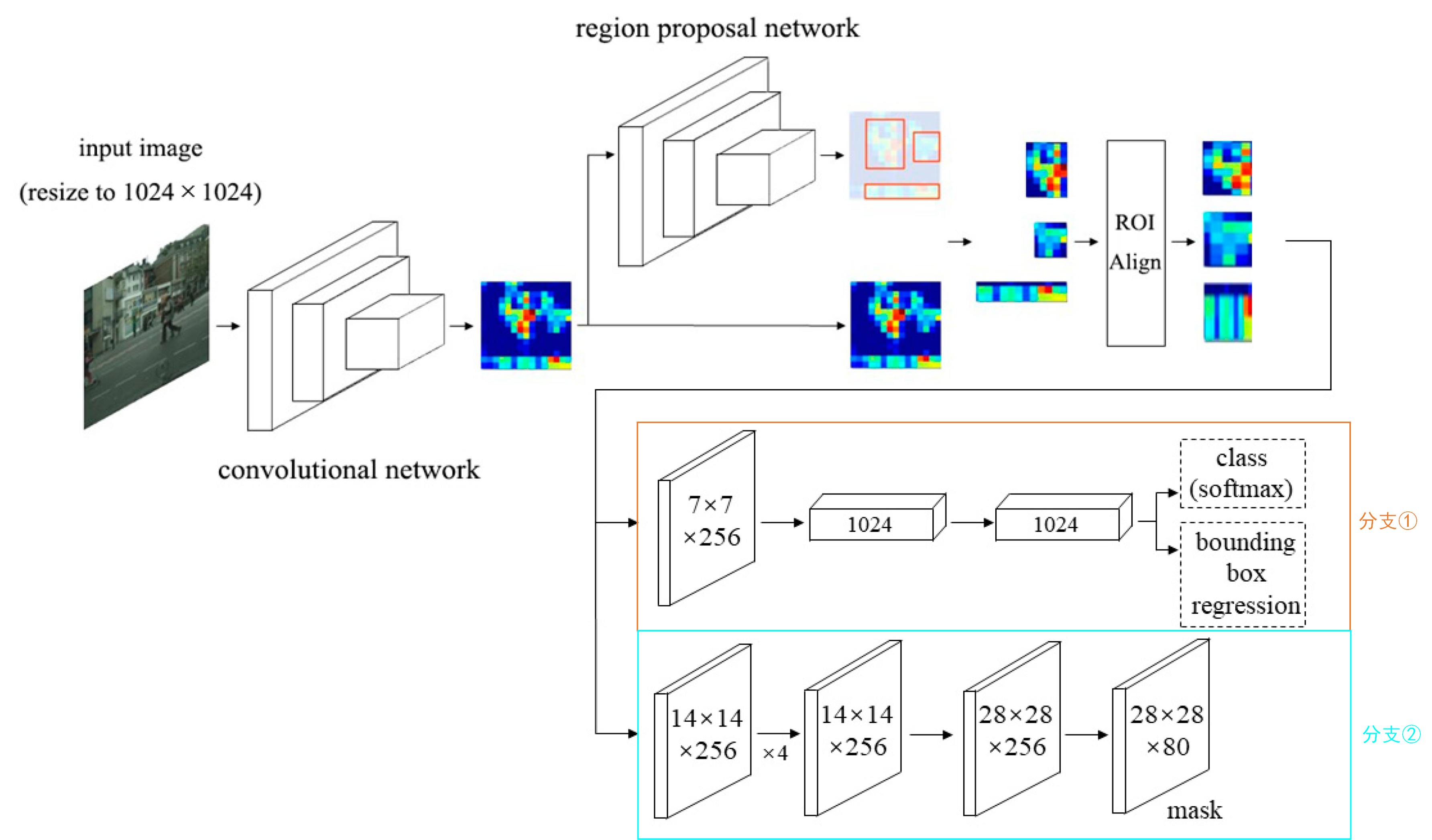
图4 Mask RCNN整理流程
对于上述所述的流程大家能否看懂呢,我觉得分支①和分支②之前的部分大家应该很熟悉才是,完全和Faster RCNN一样,不清楚的大家先点击[3]、[4]补充补充知识。关于分支①,其是Faster RCNN中的分类头和回归头,不知道的大家自行充能喔,这里就不介绍了。关于分支②,其就是一个FCN结构,其详细结构如下图所示:

图5 Mask分支结构
我想这个结构对大家来说没有什么难度吧,都是一些基础的卷积和转置卷积操作,最后的输出Mask尺寸为 28 × 28 × n u m c l s 28×28×num_{cls} 28×28×numcls,对于coco数据集来说, n u m c l s = 80 num_{cls}=80 numcls=80。【注意:这里所说的80没有包含背景哦,在一些代码中可能会包括背景】关于RoIAlign的作用就是将输入统一到指定大小,上图将原始输入 H × W × 256 H×W×256 H×W×256统一至 14 × 14 × 256 14×14×256 14×14×256大小。RoIAlign的作用和RoIPool的作用是一致的,不过RoIAlign相比RoIPool做了一些优化,具体内容可看本篇附录—>RoIAlign详解部分。
其实我感觉介绍到这里Mask RCNN的主体部分就都讲完了,剩下的就是一些细节部分,让我们一起来看看吧。
首先来看一下论文的创新点,上文提到对于我们图5中的Mask分支,其实就是一个FCN结构。我们知道,FCN结构会对每个像素的每个类别预测一个分数,最后通过softmax得到每个类别的概率,关于这个不知道的可以去阅读我对FCN的相关介绍,我也在这里放一张介绍FCN时的图片,希望帮助大家理解。

图6 FCN预测类别
当我们使用softmax时,分数高的会抑制分数低的,因为所有类别的预测概率要满足和为1的条件 。作者认为这使得不同类别之间存在相互竞争,这被称为是一种耦合关系,是不利于最终的结果的。于是作者希望消除这种耦合,即解耦。由于在Mask RCNN中我们还有一个分类和回归分支来预测类别和边界框,因此我们可以利用分类分支的预测类别直接提取出对应的Mask,这样就消除了不同类别间的竞争关系。作者也通过实验证明了这种解耦的方式可以提高检测精度,如下图所示:

图7 解耦前后精度对比
这里不知道大家听懂了没有,没听懂也没关系,在下文介绍损失函数的时候我也会为大家再次介绍。🍄🍄🍄
其实啊,对于图4给出的Mask RCNN整理流程,图中的分支①和分支②部分论文给出了两种结构,如下图所示:
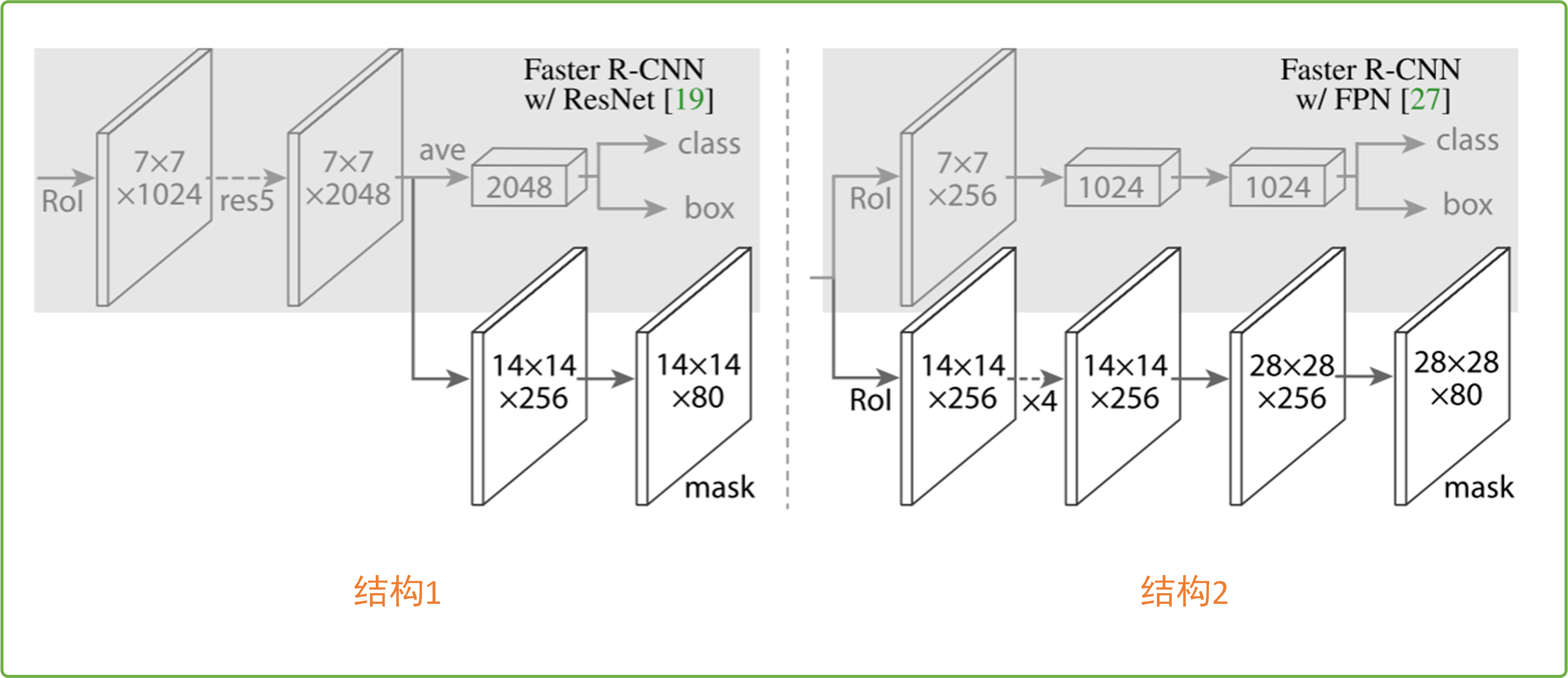
图8 Mask分支两种结构
可以看出我们图4中的结构采用的是图8的结构2,这种结构要求Mask RCNN的backbone使用FPN网络(特征金字塔网络),可以看出结构2中class、box分支和Mask分支不共用一个ROI层,这是为了保证mask分支拥有更多的细节信息。图8的结构1要求Maks RCNN的backbone采用resnet结构,也即不使用FPN结构。其实我倒是认为这两种结构差的不多,可能是作者在实验时发现采用不同backbone不同结构效果不一样吧,目前来说,我觉得大家无脑用结构2就好,采用FPN对检测小目标的效果会有较大的提升。
这部分来谈谈Mask RCNN的损失,我们知道Mask RCNN就在Faster RCNN的基础上加上了一个Mask分支,那么Mask RCNN的损失即为Faster RCNN损失加上Mask分支的损失,如下:
L o s s = L f a s t e r _ r c n n + L m a s k = L r p n + L f a s t _ r c n n + L m a s k Loss=L_{faster\_rcnn}+L_{mask}=L_{rpn}+L_{fast\_rcnn}+L_{mask} Loss=Lfaster_rcnn+Lmask=Lrpn+Lfast_rcnn+Lmask
Faster RCNN的损失就不用我介绍了吧,不懂的去看一下写在前面提到的几篇文章,相信你读完后就明白了。这里重点说一下Mask损失,其就是一个交叉熵损失,关于交叉熵损失可以看看这篇FCN文章的附录部分。那么在Mask RCNN中是怎么计算交叉熵损失的呢?我们先来看下图:
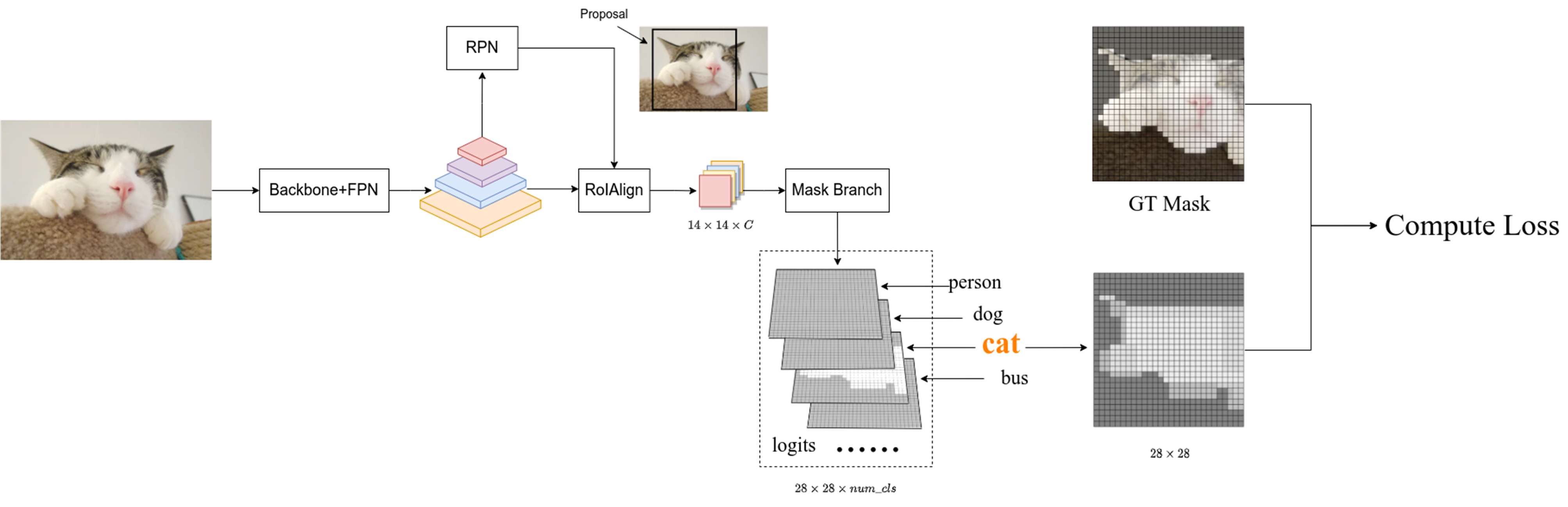
图9 图片来自B站霹雳吧啦Wz
首先输入RoIAlign的是一个个候选框,输出的是 14 × 14 × c 14×14×c 14×14×c大小的特征图,然后经过一系列的卷积、转置等操作得到logits,其是尺度为 28 × 28 × n u m c l s 28×28×num_{cls} 28×28×numcls的特征图,这个过程对应图5。上图描述的是Mask分支的结构,我们可以思考一下利用现在的logits能不能实现分割任务呢?我想这完全是可行的,因为FCN就是这么做的呀!!!🍮🍮🍮这就回到了上文所述的本论文的创新点上,这里论文不采用传统FCN的方式实现分割,因为这样会让不同类别之前存在竞争关系,会导致最后的分割精度下降。这里我们会利用class、box分支中的类别信息,比如我们通过class、box分支会知道当前的候选框的GT类别是cat(猫),于是我们就提取出logits中对应类别为猫的mask,此时这个mask是单通道的28×28大小的图像,这样就得到了Mask分支的预测输出,那么只要和GT计算交叉熵损失即可。那么GT是什么呢?同样的道理,我们通过class、box分支知道了候选框的类别是cat,那么我们将这个候选框在原图对应的GT【注:原图对应的GT是单通道的喔,目标区域为1,背景区域为0】上进行裁剪并将裁剪后图片缩放到28×28大小得到GT Mask,此时计算GT Mask和Mask分支的损失即可。
还有一点大家需要注意,图9所述的损失计算是训练过程中的,其输入RoIALign的候选框是由RPN网络提供的,至于为什么这样做呢?我提供B站霹雳吧啦Wz的一个理解,我觉得非常有道理。我们知道RPN网络提供的候选框是不准确的,一个目标可能会有好多个边界框,如下图所示,非常类似于对目标做随机裁剪,这样起到扩充数据集的作用。
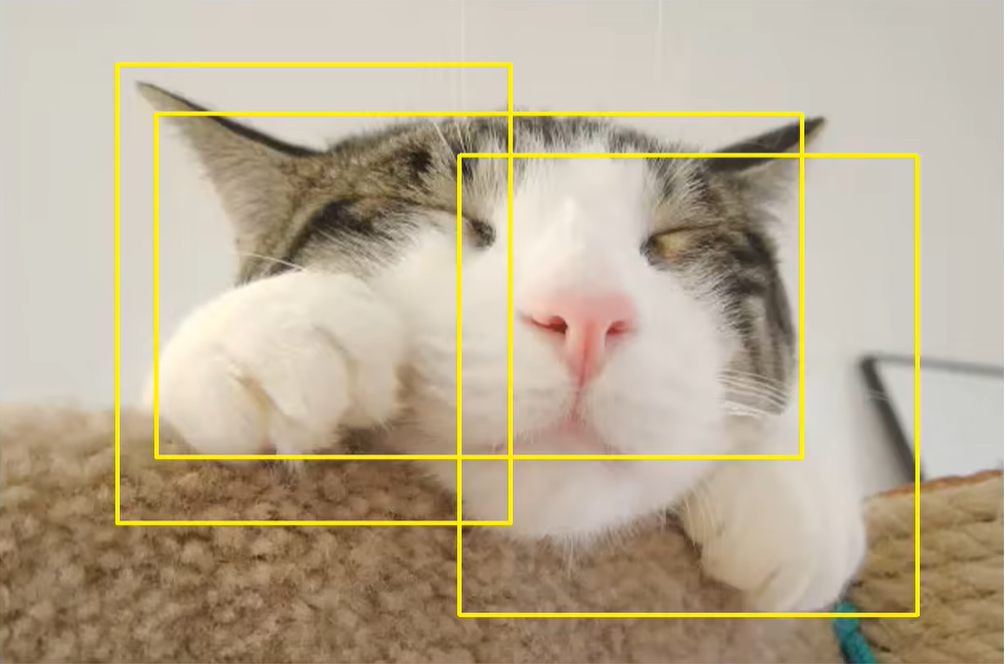
上一部分谈了谈训练过程中的损失计算,这部分为大家介绍介绍Mask RCNN的预测过程,如下图所示:

图10 图片来自B站霹雳吧啦Wz
看了图10,你可能会觉得和图9差不多,但你仔细观察观察就会发现有一些不一样了喔。首先我们来看看此时输入Mask分支的候选框来自哪里,通过图10你会发现,其不再和训练阶段一样由RPN网络提供,而是由Fast RCNN网络提供。我想这一部分也非常好理解,在预测阶段我们只需要一个最准确的候选框就好了,不再像训练阶段一样需要数据增强,所以直接从Fast RCNN网络中获得候选框即可,FPN中得到的候选框没有经过一系列微调,不准确。经过RoIAlign后,和训练阶段一样我们会得到一个28×28的单通道图片,然后将其缩放到预测目标候选框同样大小,接着将其放到原图对应的区域,得到Mask。最后还会设置一个阈值,比如0.5,将刚刚得到的Mask转换为二值图像,具体操作为将预测值大于0.5的区域设置为前景剩下区域都设置为背景。最后我们就能够在一张图像上展示出类别信息,边界框信息和Mask信息。
小结
Mask RCNN的原理部分就为大家介绍到这里了喔,更多细节将在下一篇Mask RCNN源码解析中为大家介绍,敬请期待吧。🍓🍓🍓
参考连接
附录
RoIAlign详解
这部分我们来看看RoIAlign的实现原理,在介绍RoIAlign之前,我们必须要谈的是我们为什么不使用传统的RoIPool,也即RoIAlign相较RoIPool有什么优势。【注:RoIAlign和RoIPool的目的是相同的】
RoIPool的目的是将原图缩放到统一的大小,比如原图大小为8×8,我们期望经过RoIPool层后输出2×2大小的特征图,我们只需将原图等分成4份,分别为1、2、3、4,然后对1、2、3、4应用maxPool即可得到2×2大小的特征图,大致过程如下图所示:

图11 RoIPool
现在考虑如果原图的大小是9×9,期望经过RoIPool层后的输出同样为2×2大小的特征图,此时2不能被9整除,我们需要进行量化操作(取整操作),如下图所示:

图12 RoIPool量化操作
这种量化操作会导致最终的2×2的特征图的每个像素对应的信息量不同,有点是由16个像素MaxPool得到,有点是由20个像素得到…作者认为这种操作是对分割影响很大的。
通过上文的简单描述,我想你可能明白了RoIPool是怎么运行的了,也知道了RoIPool的量化操作是不利于分割的。其实啊,使用RoIPool一共使用了两次量化操作,如下图所示:

图13 RoIPool两次量化
首先,我们输入网络的原图大小为800×800,经过VGG16网络得到特征图。【注:这里使用VGG16做示范,此网络将原图下采样32倍】此时特征图长和宽都为 800 32 = 25 \frac{800}{32}=25 32800=25。原图中狗的bbox尺寸为665×665,经过VGG16同样下采样32倍。但是你会发现 665 32 = 20.78 \frac{665}{32}=20.78 32665=20.78,无法整除,而像素点都是整数,因此我们需要进行第一次量化操作,取20.78的下界20作为bbox的长和宽。🍭🍭🍭得到20×20的bbox后,我们将其输入RoIPool中,期望输出为7×7大小,显然此时 20 7 = 2.86 \frac{20}{7}=2.86 720=2.86,其仍然是一个小数,此时需要进行第二次量化操作,同样向下取整,即取2。【注:不知道大家发现没有,这里的第二次量化操作和我图12中所描述的是有一定差异的,这里直接舍去了一些像素,在我用代码验证过程中,发现使用的是图12的方式,当然了,可能会有一些参数来控制RoIPool实现的形式,感兴趣的可以去搜搜看喔。🍄🍄🍄】
介绍完了RoIPool,下面就来为大家介绍介绍RoIAlign,其没有像RoIPool一样采用量化操作,RoIAlign过程如下图所示:

图14 RoIAlign操作
从上图可以看出,RoIAlign在RoIPool两次量化时都没有量化,而是保留了小数,这种方式能够较大的提升网络分割效果,至于提升多大,我们直接来看论文中给的表吧。

这个提升是不是足够震惊的,足足增加了好几个点。说到这里,我想大家就知道了RoIAlign是优于RoIPool的,但是似乎还是不太明白这个RoIAlign具体是怎么操作的。这里我不准备码字为大家介绍了,推荐大家去看此视频,大家可直接跳转到5分50秒观看喔。🍀🍀🍀
如若文章对你有所帮助,那就🛴🛴🛴

本文链接:https://my.lmcjl.com/post/2439.html
4 评论